
Makine öğreniminde veri etiketleme nedir ve nasıl çalışır?
Yayınlanan: 2022-04-29Veri, günümüz işletmeleri için yeni zenginliktir. Yapay zeka gibi teknolojilerin günlük faaliyetlerimizin çoğunu aşamalı olarak üstlenmesiyle birlikte, herhangi bir verinin doğru kullanımı toplumu olumlu yönde etkiliyor. ML algoritmaları, verileri verimli bir şekilde ayırarak ve etiketleyerek sorunları keşfedebilir ve pratik ve ilgili çözümler sağlayabilir.
Veri etiketleme yardımı ile makineye çeşitli teknikleri öğretiyor ve "akıllı" davranmaları için bilgileri çeşitli formatlarda giriyoruz. Veri etiketlemenin ardındaki bilim, aynı bilginin birden çok varyasyonuyla veri kümelerini açıklama veya etiketleme şeklinde bir sürü ödevi içerir. Nihai sonuç günlük hayatımızı şaşırtıp kolaylaştırsa da, bunun arkasındaki emek muazzam ve özveri övgüye değer.
Veri etiketleme nedir?
Makine öğreniminde, girdi verilerinin kalitesi ve türü, çıktının kalitesini ve türünü belirler. Makineyi eğitmek için kullanılan verilerin kalitesi, AI modelinizin doğruluğunu artırır.
Başka bir deyişle, veri etiketleme, yapılandırılmamış veya yapılandırılmış veri kümeleri arasındaki farkları ve benzerlikleri etiketleyerek veya açıklamalar ekleyerek bulmak için bir makineyi eğitme sürecidir.
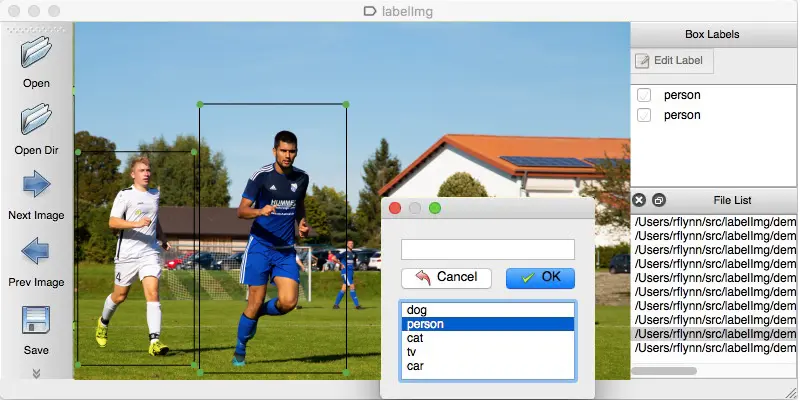
Bunu bir örnekle anlayalım. Makineyi kırmızı ışığın dur işareti olduğu konusunda eğitmek için, makinenin sinyali anlaması için çeşitli resimlerdeki tüm kırmızı ışıkları etiketlemeniz gerekir. Buna dayanarak, AI, verilen her senaryoda kırmızı ışığı bir durma sinyali olarak okuyacak bir algoritma oluşturur. Başka bir örnek, müzik türlerinin caz, pop, rock, klasik ve daha fazlası etiketleri altında birden çok veri kümesiyle ayrılabilmesidir.
Veri etiketlemedeki zorluklar
Teknoloji veya yapıdaki herhangi bir yeni değişiklik/gelişme, faydalarını ve zorluklarını da beraberinde getirir. Veri etiketleme için de durum farklı değildir. Veri etiketleme, bir işletmeyi ölçeklendirme süresini önemli ölçüde azaltabilse de , bunun bir maliyeti vardır. Veri etiketlemenin beraberinde getirdiği bazı zorluklar üzerinde duralım.
Zaman ve çaba açısından maliyet
Nişe özgü verileri büyük miktarlarda elde etmek başlı başına zorlu bir iştir. Her öğe için manuel olarak etiket eklemek, yalnızca zaten zaman alan göreve eklenir. Proje şirket içinde yürütülüyorsa, proje zamanının çoğu, verilerin toplanması, hazırlanması ve etiketlenmesi gibi verilerle ilgili görevlere harcanır.
Bu görevleri etkili bir şekilde yönetmek ve işi ilk seferde doğru yapmak için, bu özel uzmanlığa sahip uzman etiketleyicilere ihtiyacınız olacak. Bu aynı zamanda, sadece zaman açısından değil, aynı zamanda para açısından da maliyetli hale getiren pahalı bir girişimdir.
Tutarsızlık
Farklı uzmanlığa sahip yorumcular farklı etiketleme kriterlerine sahip olabilir. Sonuç olarak, tutarsız etiketleme olasılığı yüksektir. Bununla birlikte, birkaç kişi aynı veri setini etiketlediğinde, veri doğruluk oranları çok daha yüksek olacaktır.
Alan uzmanlığı
Belirli endüstriler için, belirli alan uzmanlığına sahip etiketleyicileri işe alma ihtiyacı hissedeceksiniz. Örneğin, sağlık sektörü için bir makine öğrenimi uygulaması oluşturmak için ilgili alan uzmanlığına sahip olmayan ek açıklama yapanlar, öğeleri doğru şekilde etiketlemeyi çok zor bulacaktır.
kusurlar
İnsanlar tarafından yapılan herhangi bir tekrarlı iş hataya eğilimlidir. İnsan etiketleyicinin uzmanlık düzeyi ne olursa olsun, manuel etiketleme her zaman kusurlu olacaktır. Anlatıcıların etiketleme için büyük ham veri kümeleriyle uğraşması gerektiğinden sıfır hata sağlamak neredeyse imkansızdır.
Veri etiketlemeye yönelik yaklaşımlar
Yukarıda bahsedildiği gibi, veri etiketleme, ayrıntılara dikkat etmeyi gerektiren zaman alıcı bir iştir. Sorun bildirimine, etiketlenecek veri miktarına, verilerin karmaşıklığına ve stile bağlı olarak, verilere açıklama eklemek için uygulanan strateji değişecektir.
Finansal kaynaklara ve mevcut zamana göre şirketinizin tercih edebileceği çeşitli yaklaşımları gözden geçirelim.
Şirket içi veri etiketleme
Endüstri türüne, verilen AI projesini tamamlamak için eldeki süreye ve gerekli kaynakların mevcudiyetine bağlı olarak, veri etiketi süreci kuruluşlar tarafından kurum içinde gerçekleştirilebilir.
Artıları:
- Yüksek doğruluk
- Yüksek kalite
- Basitleştirilmiş izleme
Eksileri:
- Zaman alıcı/yavaş
- Kapsamlı kaynaklar gerektirir
kitle kaynak kullanımı
Serbest çalışanlar tarafından etiketlenen kaynak bulma veri setleri, çeşitli kitle kaynak kullanımı platformlarında mevcuttur. Bu yöntem, resimler gibi genelleştirilmiş verilere açıklama eklemek için kullanılabilir.
Kitle kaynak kullanımı yoluyla veri etiketlemenin en ünlü örneği Recaptcha'dır. Kullanıcıdan, insan olduklarını kanıtlamak için belirli görüntü türlerini tanımlaması istenir. Bunlar, diğer kullanıcılar tarafından verilen girdilere göre doğrulanır. Bu, bir dizi görüntü için bir etiket veritabanı görevi görür.
Artıları:
- Çabuk ve kolay
- Uygun maliyetli
Eksileri:
- Alan uzmanlığı gerektiren veriler için kullanılamaz
- Kalite garanti edilmez
Dış kaynak kullanımı
Dış kaynak kullanımı, kurum içi veri etiketleme ile kitle kaynak kullanımı arasında bir orta yol işlevi görebilir. Alan uzmanlığına sahip üçüncü taraf kuruluşları veya bireyleri işe almak, kuruluşlara tüm uzun vadeli ve kısa vadeli projelerde yardımcı olabilir.
Artıları:
- Üst düzey geçici projeler için ideal
- Üçüncü taraf dış kaynak şirketleri, denetlenmiş personel sağlar
- İş gereksinimlerinize göre hem önceden oluşturulmuş hem de özel veri etiketleme araçları sağlar
- Nişe özel veri etiketleme uzmanlarının seçeneğini alabilir
Eksileri:
- Üçüncü tarafı yönetmek zaman alıcı olabilir
makine tabanlı
Endüstriler tarafından yaygın olarak kullanılan ve kabul edilen en son veri etiketleme ve açıklama biçimlerinden biri, makine tabanlı açıklamadır. Veri etiketleme yazılımı yardımıyla veri etiketleme sürecini otomatikleştirmek, insan müdahalesini azaltır ve etiketlemenin yapılma hızını artırır. Aktif öğrenme adı verilen teknikle, eğitim veri setlerine otomatik olarak hangi etiketlerin eklenebileceğine bağlı olarak veriler etiketlenebilir.
Artıları:
- Daha hızlı veri işleme ve etiketleme
- Daha az insan müdahalesi içerir
Eksileri:
- Daha kaliteli olmasına rağmen, insan etiketleme ile aynı seviyede değil
- Hata durumunda, insan müdahalesi hala gereklidir

Veri etiketleme nasıl çalışır?
İş gereksinimlerinize göre, gereksinimlerinize en uygun yaklaşımı seçebilirsiniz. Ancak veri etiketleme süreci kronolojik olarak aşağıdaki sıraya göre çalışır.
Veri toplama
Herhangi bir makine öğrenimi projesinin temeli verilerdir. Çeşitli formatlarda doğru miktarda ham verinin toplanması, veri etiketlemenin ilk adımını oluşturur. Veri toplama iki şekilde olabilir - biri şirketin dahili olarak topladığı, diğeri ise kamuya açık olan harici kaynaklardan toplanan.
Ham formda olan bu veriler, veri kümeleri için etiketler oluşturulmadan önce temizlenmesi ve işlenmesi gerekir. Bu temizlenmiş ve önceden işlenmiş veriler daha sonra eğitim için modele beslenir. Veriler ne kadar büyük ve çeşitlendirilmişse, sonuçlar o kadar doğru olacaktır.
Veri açıklaması
Veriler temizlendikten sonra, alan uzmanları verileri gözden geçirir ve çeşitli veri etiketleme yaklaşımlarını izleyerek etiketler ekler. Anlamlı bağlam, temel gerçek olarak kullanılabilecek modele eklenir. Bunlar, modelin tahmin etmesini istediğiniz görüntüler gibi hedef değişkenlerdir.

Kalite güvencesi
ML modeli eğitiminin başarısı, güvenilir, doğru ve tutarlı olması gereken verilerin kalitesine büyük ölçüde bağlıdır. Bu kesin ve doğru veri etiketlerini sağlamak için, yerinde düzenli KG kontrolleri yapılmalıdır. Consensus ve Cronbach's alpha testi gibi QA algoritmalarının kullanılmasıyla bu açıklamaların doğruluğu belirlenebilir. Düzenli KG kontrolleri, sonuçların doğruluğuna büyük ölçüde katkıda bulunur.
Model eğitimi ve testi
Yukarıdaki tüm adımların gerçekleştirilmesi, yalnızca verilerin doğruluk açısından test edilmesi durumunda anlamlıdır. Beklenen sonuçları verip vermediğini görmek için yapılandırılmamış veri kümesinin girilmesi süreci test edecektir.
Veri etiketleme için sektöre uygun kullanım örnekleri
Artık veri etiketlemenin ne olduğuna ve nasıl çalıştığına aşina olduğumuza göre, en belirgin kullanım örneklerini gözden geçirelim.
Bilgisayarla Görme (CV)
Bu, makinelerin görseller ve videolar (etiketleme için çıkarılan durağan görüntüler) biçiminde sağlanan girdilerden anlamlı bir yorum elde etmesini sağlayan bir AI alt kümesidir.
Bilgisayarla görü ek açıklaması, yapay zekanın pratik faydalarını uygulamak için çeşitli endüstrilerde kullanılabilir.
- Otomotiv endüstrisinde, görüntüleri ve videoları yolları, binaları, yayaları ve diğer nesneleri segmentlere ayırmak için etiketlemek, otonom araçların gerçek hayatta teması önlemek için bu varlıklar arasında ayrım yapmasına yardımcı olacaktır.
- Sağlık sektöründe hastalık belirtileri bir X-ray, MRI ve CT taramasında bölümlere ayrılabilir. Mikroskobik görüntüler yardımıyla çoğu kritik hastalık erken aşamada teşhis edilebilir.
- QR kodları, etiket barkodları vb. nakliye ve lojistik sektöründe mal takibi için etiket olarak kullanılabilir.
Doğal dil işleme (NLP)
Bu, AI makinelerinin insan dilini ve istatistiklerini yorumlamasını sağlayan bir alt kümedir. Metin ve konuşmadan anlam çıkaran algoritma, çeşitli dilbilimsel yönleri analiz edebilir.
NLP, birçok kurumsal çözümde giderek daha fazla kullanılmaktadır .
- E-posta asistanı, otomatik tamamlama özelliği, yazım denetimi, spam ve spam olmayan e-postaları ayırma ve çok daha fazlası olarak tüm sektörlerde yaygın olarak kullanılır.
- Chatbotlar şeklinde , müşteriler tarafından yöneltilen temel sorular, gerçek zamanlı olarak insan müdahalesi olmadan yorumlanır ve cevaplanır. 2023 yılına kadar müşteri etkileşimlerinin %70'inin chatbotlar ve mobil mesajlaşma uygulamaları tarafından yönetileceği tahmin ediliyor .
- Müşteri duyarlılığını yakalamak için metnin negatif ve pozitif kutuplarını anlamak, e-ticarette veri etiketleme ile yapılmaktadır.
Appinventiv, Vyrb için , kullanıcıların Bluetooth giyilebilir cihazlar için optimize edilmiş sesli mesajlar gönderip almalarını sağlayan bir sosyal medya uygulamasını başarıyla oluşturdu.

AI veri etiketleme pazarına genel bakış
Veri etiketleme, yapay zeka teknolojisinden doğan gelişen bir endüstridir . Veri etiketleme büyük ölçüde makine öğrenimine beslenen doğru verilere bağlı olduğundan, önümüzdeki birkaç yıl içinde büyümesi kaçınılmazdır.
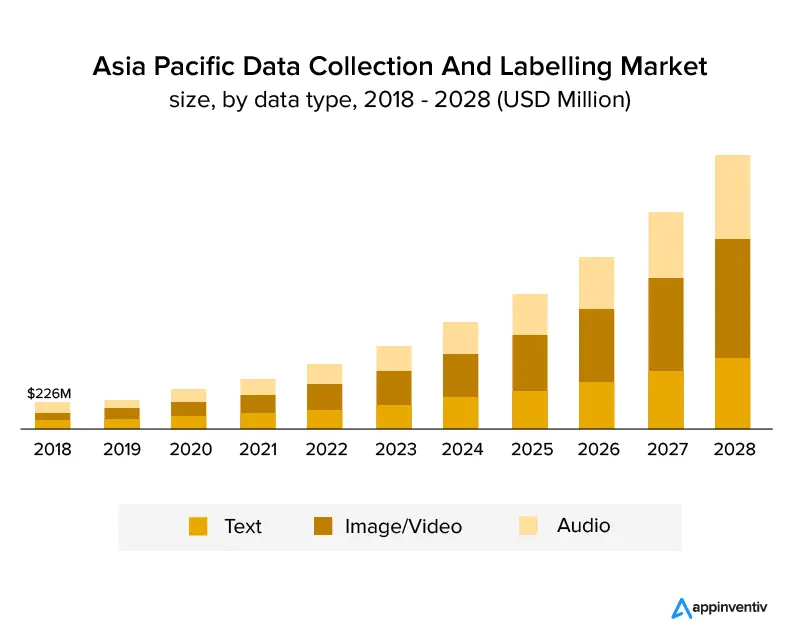
Aşağıdaki grafik, sektörün büyüdüğünü ve önümüzdeki yıllarda da büyümeye devam edeceğini açıkça göstermektedir. 2028 yılına kadar yıllık %25,6'lık bir bileşik büyüme ile büyümesi ve 8,22 milyar ABD doları tutarında bir pazar büyüklüğüne ulaşması bekleniyor. Aşağıdaki grafik, veri türüne göre büyümeyi göstermektedir.
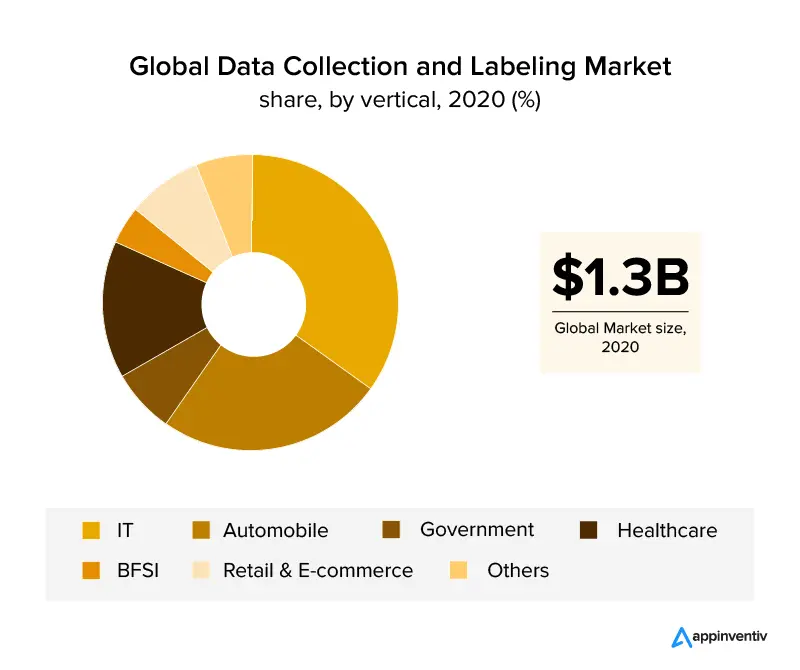
Veri etiketlemeden yararlanan iş sektörlerine genel bir bakış, küresel gelirin %30'dan fazlasını kapsayan BT ve otomotiv sektörleridir. Sağlık sektörünün büyümesiyle, sektördeki verimli AI tabanlı uygulamalar için doğru veri gereksinimleri nedeniyle veri etiketlemenin patlaması bekleniyor . Görüntü etiketlemenin yardımıyla perakende ve e-ticaret sektörleri de veri etiketleme sektöründe önemli bir pazar payı elde etti.
Appinventiv ile verileri etiketleme
Stratejik olarak şirketler, güçlü makine öğrenimi modelleri oluşturmak için veri toplama ve etiketleme hizmetlerini dış kaynak kullanıyor.
Appinventiv, yıllardır kuruluşların AI odaklı çözümlerle fırsatların kilidini açmasına yardımcı olan bir AI ve ML geliştirme şirketidir . İşletmeleri dönüştürme konusunda neredeyse on yıllık deneyime sahip olarak, farklı endüstriler için birçok karmaşık yapay zeka projesini başarıyla teslim ettik.
Örneğin Appinventiv, Avrupa'nın önde gelen bankalarından birinin bankacılık sürecini başarıyla otomatikleştirdi . Otomasyon süreci, bankanın doğruluğu %50 ve ATM hizmet düzeylerini %92 oranında iyileştirmesine yardımcı oldu.
Appinventiv'in YouCOMM'a tıbbi yardıma gerçek zamanlı erişim sağlayarak hastane içi hasta iletişimini dönüştürmek için devrim niteliğinde bir çözüm oluşturmasında yardımcı olduğu bir başka örnek. Özelleştirilebilir bir hasta mesaj sistemi ile hastalar, sesli komutlar ve baş hareketlerini kullanarak ihtiyaçlarını personele kolayca bildirebilir.
Uzmanlığımız ve müşteri odaklı ekibimizle, size özel ihtiyaç ve gereksinimlerinize göre bütünsel veri etiketleme hizmetleri sunarak zorlukların üstesinden gelmenize yardımcı olacak veri etiketleme hizmetleri sunuyoruz.
Appinventiv, etiketleme ve veri açıklaması için gereken çok çeşitli araçlardan yararlanarak, karmaşık modelleri basitleştirmek için veri eğitim süreçlerinizi iyileştirebilir. Bu, segmentasyon, sınıflandırma ve ardından hızlı ve kolay olacak veri etiketleme doğruluğu açısından daha iyi performans göstermemizi sağlar.
Tamamlanıyor!
“Yapay zekanın gücü o kadar inanılmaz ki toplumu çok derinden değiştirecek.” -Bill Gates
Yapay zeka, insan hayatını kolaylaştırma ve böylece topluma fayda sağlama potansiyeline sahiptir. Veri etiketlemenin yardımıyla büyük miktarda veriyi anlamlı talimatlara ayırma yeteneği, endüstrilerin sıçramalarla ilerlemesine ve büyümesine yardımcı oldu.
SSS
S. Mükemmel veri etiketleme için en iyi uygulamalar nelerdir?
C. Veri etiketleme için benimsediğiniz yaklaşıma bağlı olarak izleyebileceğiniz bazı en iyi uygulamalar vardır:
- Toplanan verilerin yeterli olduğundan, uygun şekilde temizlendiğinden ve işlendiğinden emin olun.
- Sektöre bağlı olarak, işi yalnızca etki alanı uzmanı veri etiketleyicilerine atayın.
- İzlenecek açıklama teknikleri kriterlerini sağlayarak ekip tarafından tek tip bir yaklaşımın izlenmesini sağlayın.
- Çapraz etiketleme için birden çok açıklayıcı atayarak bir oluşturucu-kontrol süreci izleyin.
S. Veri etiketlemenin faydaları nelerdir?
A. Veri etiketleme, verilerin kesin bir tahminini yapmak için bağlam, kalite ve kullanılabilirlik konusunda daha iyi netlik sağlamaya yardımcı olur. Bu da, modeldeki değişkenlerin veri kullanılabilirliğini geliştirmeye yardımcı olur.
S. Veri etiketleme şirketlerini kısa listeye alırken göz önünde bulundurulması gereken çeşitli unsurlar nelerdir?
A. Makine öğrenimi için veri etiketi hizmetlerini seçerken dikkate alınması gereken beş parametre vardır.
- Veri etiketleme sürecinin ölçeklenebilirliği
- Veri etiketleme hizmet maliyeti
- Veri güvenliği
- Veri etiketleme platformu