
SEO'da Robots.txt Nedir: Nasıl Oluşturulur ve Optimize Edilir
Yayınlanan: 2022-04-22Bugünün konusu doğrudan trafikten para kazanma ile ilgili değil. Ancak robots.txt, web sitenizin SEO'sunu ve nihayetinde aldığı trafik miktarını etkileyebilir. Birçok web yöneticisi, hatalı robots.txt girişleri nedeniyle web sitelerinin sıralamasını mahvetti. Bu kılavuz, tüm bu tuzaklardan kaçınmanıza yardımcı olacaktır. Sonuna kadar okumayı unutmayın!
- robots.txt dosyası nedir?
- Bir robots.txt dosyası nasıl görünür?
- robots.txt dosyanızı nasıl bulabilirsiniz?
- Robots.txt dosyası nasıl çalışır?
- Robots.txt sözdizimi
- Desteklenen yönergeler
- Kullanıcı aracısı*
- İzin vermek
- izin verme
- site haritası
- Desteklenmeyen yönergeler
- Tarama gecikmesi
- noindex
- Takip etme
- Bir robots.txt dosyasına mı ihtiyacınız var?
- robots.txt dosyası oluşturma
- Robots.txt dosyası: SEO için en iyi uygulamalar
- Her yönerge için yeni bir satır kullanın
- Talimatları basitleştirmek için joker karakterler kullanın
- Bir URL'nin sonunu belirtmek için dolar işaretini "$" kullanın
- Her kullanıcı aracısını yalnızca bir kez kullanın
- İstenmeyen hataları önlemek için özel talimatları kullanın
- Bir karma ile robots.txt dosyasına açıklama girin
- Her alt etki alanı için farklı robots.txt dosyaları kullanın
- İyi içeriği engelleme
- Tarama gecikmesini aşırı kullanmayın
- Büyük/küçük harf duyarlılığına dikkat edin
- Diğer en iyi uygulamalar:
- İçeriğin indekslenmesini önlemek için robots.txt'i kullanma
- Özel içeriği korumak için robots.txt'yi kullanma
- Kötü niyetli yinelenen içeriği gizlemek için robots.txt kullanma
- Tüm botlar için tam erişim
- Tüm botlara erişim yok
- Tüm botlar için bir alt dizini engelle
- Tüm botlar için bir alt dizini engelle (izin verilen bir dosyayla)
- Tüm botlar için bir dosyayı engelle
- Tüm botlar için bir dosya türünü (PDF) engelle
- Yalnızca Googlebot için tüm parametreli URL'leri engelle
- robots.txt dosyanızda hatalar için nasıl test edilir
- Gönderilen URL robots.txt tarafından engellendi
- robots.txt tarafından engellendi
- Dizine eklendi, ancak robots.txt tarafından engellendi
- Robots.txt vs meta robotlar vs x-robotlar
- daha fazla okuma
- toparlamak
robots.txt dosyası nedir?
robots.txt veya robot dışlama protokolü, arama motoru robotlarının o sayfadaki şema işaretlemelerine kadar her web sayfasını nasıl taradığını kontrol eden bir dizi web standardıdır. Web tarayıcılarının web sitenizin tamamına veya bölümlerine erişmesini bile engelleyebilen standart bir metin dosyasıdır.
SEO'yu ayarlarken ve teknik sorunları çözerken reklamlardan pasif gelir elde etmeye başlayabilirsiniz. Web sitenizdeki tek bir kod satırı, düzenli ödemeler getirir!
İçindekiler ↑Bir robots.txt dosyası nasıl görünür?
Sözdizimi basittir: Kullanıcı aracılarını ve yönergelerini belirterek botlara kurallar verirsiniz. Dosya aşağıdaki temel biçime sahiptir:
Site Haritası: [Site haritasının URL konumu]
Kullanıcı aracısı: [bot tanımlayıcı]
[yönerge 1]
[direktif 2]
[yönerge…]
Kullanıcı aracısı: [başka bir bot tanımlayıcısı]
[yönerge 1]
[direktif 2]
[yönerge…]
robots.txt dosyanızı nasıl bulabilirsiniz?
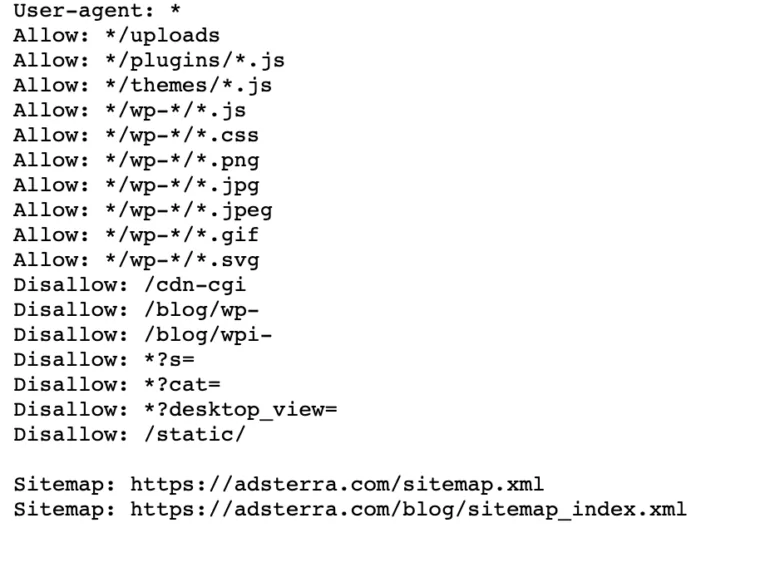
Web sitenizde zaten bir robot.txt dosyası varsa, bunu tarayıcınızda şu URL'ye giderek bulabilirsiniz: https://alanadiniz.com/robots.txt . Örneğin, işte dosyamız
Robots.txt dosyası nasıl çalışır?
Bir robots.txt dosyası, herhangi bir HTML biçimlendirme kodu (dolayısıyla .txt uzantısı) içermeyen düz bir metin dosyasıdır. Bu dosya, web sitesindeki diğer tüm dosyalar gibi web sunucusunda saklanır. Sayfalarınızın hiçbiriyle bağlantılı olmadığı için kullanıcıların bu sayfayı ziyaret etmesi olası değildir, ancak çoğu web tarayıcı botu, web sitesinin tamamını taramadan önce bu sayfayı arar.
Bir robots.txt dosyası, botlara talimatlar verebilir ancak bu talimatları uygulayamaz. Web tarayıcısı veya haber akışı botu gibi iyi bir bot, herhangi bir alan sayfasını ziyaret etmeden önce dosyayı kontrol eder ve talimatları uygular. Ancak kötü niyetli botlar, yasak web sayfalarını bulmak için dosyayı ya yok sayar ya da işler.
Bir robots.txt dosyasının çakışan komutlar içerdiği bir durumda, bot en spesifik talimat setini kullanır.
İçindekiler ↑Robots.txt sözdizimi
Bir robots.txt dosyası, her biri bir kullanıcı aracısı ile başlayan birkaç "yönerge" bölümünden oluşur. Kullanıcı aracısı, kodun iletişim kurduğu gezinme botunu belirtir. Tüm arama motorlarına aynı anda hitap edebilir veya tek tek arama motorlarını yönetebilirsiniz.
Bir bot bir web sitesini her taradığında, sitenin onu çağıran kısımlarına etki eder.
Kullanıcı aracısı: *
izin verme: /
Kullanıcı aracısı: Googlebot
İzin verme:
Kullanıcı aracısı: Bingbot
İzin verme: /bing için değil/
Desteklenen yönergeler
Yönergeler, beyan ettiğiniz kullanıcı aracılarının uymasını istediğiniz yönergelerdir. Google şu anda aşağıdaki yönergeleri desteklemektedir.
Kullanıcı aracısı*
Bir program bir web sunucusuna (bir robot veya normal bir web tarayıcısı) bağlandığında, kimliği hakkında temel bilgileri içeren “user-agent” adlı bir HTTP başlığı gönderir. Her arama motorunun bir kullanıcı aracısı vardır. Google'ın robotları Googlebot, Yahoo'lar - Slurp ve Bing's - BingBot olarak bilinir. Kullanıcı aracısı, belirli kullanıcı aracılarına veya tüm kullanıcı aracılarına uygulanabilecek bir dizi yönerge başlatır.
İzin vermek
İzin verme yönergesi, arama motorlarına bir sayfayı veya alt dizini, hatta kısıtlı bir dizini taramasını söyler. Örneğin, arama motorlarının biri hariç blogunuzun tüm gönderilerine erişememesini istiyorsanız, robots.txt dosyanız şöyle görünebilir:
Kullanıcı aracısı: *
İzin verme: /blog
İzin ver: /blog/izin verilen gönderi
Ancak, arama motorları /blog/allowed-post'a erişebilir, ancak şunlara erişemezler:
/blog/başka bir gönderi
/blog/henüz-başka-yazı
/blog/download-me.pd
izin verme
Disallow yönergesi (bir web sitesinin robots.txt dosyasına eklenir), arama motorlarına belirli bir sayfayı taramamalarını söyler. Çoğu durumda bu, bir sayfanın arama sonuçlarında görünmesini de engeller.
Bu yönergeyi, arama motorlarına, genel halktan gizlediğiniz belirli bir klasördeki dosyaları ve sayfaları taramamaları talimatını vermek için kullanabilirsiniz. Örneğin, üzerinde çalıştığınız ancak yanlışlıkla yayınladığınız içerik. Tüm arama motorlarının blogunuza erişmesini engellemek istiyorsanız robots.txt dosyanız şöyle görünebilir:
Kullanıcı aracısı: *
İzin verme: /blog
Bu, /blog dizininin tüm alt dizinlerinin de taranmayacağı anlamına gelir. Bu, Google'ın /blog içeren URL'lere erişmesini de engeller.
İçindekiler ↑site haritası
Site haritaları, arama motorlarının taramasını ve dizine eklemesini istediğiniz sayfaların bir listesidir. Site haritası yönergesini kullanırsanız, arama motorları XML site haritanızın konumunu bilecektir. En iyi seçenek, bunları arama motorlarının web yöneticisi araçlarına göndermektir, çünkü her biri ziyaretçiler için web siteniz hakkında değerli bilgiler sağlayabilir.
Her kullanıcı aracısı için site haritası yönergesini tekrar etmenin gereksiz olduğunu ve tek bir arama aracısı için geçerli olmadığını belirtmek önemlidir. Site haritası yönergelerinizi robots.txt dosyanızın başına veya sonuna ekleyin.
Dosyadaki site haritası yönergesine bir örnek:
Site Haritası: https://www.domain.com/sitemap.xml
Kullanıcı aracısı: Googlebot
İzin verme: /blog/
İzin ver: /blog/post-title/
Kullanıcı aracısı: Bingbot
İzin verme: /hizmetler/
İçindekiler ↑Desteklenmeyen yönergeler
Aşağıdakiler, Google'ın artık desteklemediği ve bazıları teknik olarak hiçbir zaman onaylanmayan yönergelerdir.
Tarama gecikmesi
Yahoo, Bing ve Yandex, web sitelerinin indekslenmesine hızla yanıt verir ve onları bir süre kontrol altında tutan tarama gecikmesi yönergesine tepki verir.
Bu satırı bloğunuza uygulayın:
Kullanıcı aracısı: Bingbot
Tarama gecikmesi: 10
Bu, arama motorlarının web sitesini taramadan önce on saniye veya taramadan sonra web sitesine yeniden erişmeden önce on saniye bekleyebileceği anlamına gelir; bu aynı şeydir, ancak kullanılan kullanıcı aracısına bağlı olarak biraz farklıdır.
noindex
noindex meta etiketi, arama motorlarının sayfalarınızdan birini dizine eklemesini önlemenin harika bir yoludur. Etiket, botların web sayfalarına erişmesine izin verir, ancak aynı zamanda robotları onları dizine eklememeleri konusunda bilgilendirir.
- noindex etiketli HTTP Yanıt başlığı. Bu etiketi iki şekilde uygulayabilirsiniz: X-Robots-Tag içeren bir HTTP yanıt başlığı veya <head> bölümüne yerleştirilmiş bir <meta> etiketi. <meta> etiketiniz şöyle görünmelidir:
<meta adı=”robotlar” içerik=”noindex”>
- 404 & 410 HTTP durum kodu. 404 ve 410 durum kodları, bir sayfanın artık mevcut olmadığını gösterir. 404/410 sayfayı taradıktan ve işledikten sonra, bunları otomatik olarak Google'ın dizininden kaldırırlar. 404 ve 410 hata sayfası riskini azaltmak için web sitenizi düzenli olarak tarayın ve gerektiğinde trafiği mevcut bir sayfaya yönlendirmek için 301 yönlendirmelerini kullanın.
Takip etme
Nofollow, arama motorlarını belirli bir yol altındaki sayfalardaki ve dosyalardaki bağlantıları takip etmemeye yönlendirir. 1 Mart 2020'den bu yana Google, nofollow özelliklerini yönerge olarak kabul etmemektedir. Bunun yerine, kurallı etiketler gibi ipuçları olacaklar. Bir sayfadaki tüm bağlantılar için bir "nofollow" özniteliği istiyorsanız, robotun meta etiketini, x-robots başlığını veya rel= "nofollow" bağlantı özniteliğini kullanın.
Önceden, Google'ın blogunuzdaki tüm bağlantıları izlemesini önlemek için aşağıdaki yönergeyi kullanabiliyordunuz:
Kullanıcı aracısı: Googlebot
Nofollow: /blog/
Bir robots.txt dosyasına mı ihtiyacınız var?
Daha az karmaşık birçok web sitesinin birine ihtiyacı yoktur. Google, robots.txt tarafından engellenen web sayfalarını genellikle dizine eklemese de, bu sayfaların arama sonuçlarında görünmeyeceğini garanti etmenin hiçbir yolu yoktur. Bu dosyaya sahip olmak, web sitenizdeki içeriğin arama motorları üzerinden daha fazla kontrolünü ve güvenliğini sağlar.
Robot dosyaları ayrıca aşağıdakileri gerçekleştirmenize yardımcı olur:
- Yinelenen içeriğin taranmasını önleyin.
- Farklı web sitesi bölümleri için gizliliği koruyun.
- Dahili arama sonuçlarının taranmasını kısıtlayın.
- Sunucu aşırı yüklenmesini önleyin.
- "Tarama bütçesi" israfını önleyin.
- Görselleri, videoları ve kaynak dosyalarını Google arama sonuçlarının dışında tutun.
Bu önlemler nihayetinde SEO taktiklerinizi etkiler. Örneğin, yinelenen içerik arama motorlarının kafasını karıştırır ve onları iki sayfadan hangisinin ilk sırada yer alacağını seçmeye zorlar. İçeriği kimin oluşturduğuna bakılmaksızın, Google, en iyi arama sonuçları için orijinal sayfayı seçmeyebilir.

Google, kullanıcıları aldatmaya veya sıralamaları manipüle etmeye yönelik yinelenen içerik tespit ettiğinde, web sitenizin dizine eklenmesini ve sıralamasını ayarlar. Sonuç olarak, sitenizin sıralaması zarar görebilir veya arama sonuçlarından kaybolarak Google'ın dizininden tamamen kaldırılabilir.
Farklı web sitesi bölümleri için gizliliği korumak, web sitenizin güvenliğini de artırır ve bilgisayar korsanlarından korur. Uzun vadede, bu önlemler web sitenizi daha güvenli, güvenilir ve karlı hale getirecektir.
Trafikten kazanç sağlamak isteyen bir web sitesi sahibi misiniz? Adsterra ile herhangi bir web sitesinden pasif gelir elde edeceksiniz!
İçindekiler ↑robots.txt dosyası oluşturma
Not Defteri gibi bir metin düzenleyiciye ihtiyacınız olacak.
- Yeni bir sayfa oluşturun, boş sayfayı 'robots.txt' olarak kaydedin ve boş .txt belgesine yönergeleri yazmaya başlayın.
- cPanel'inize giriş yapın, sitenin kök dizinine gidin, public_html klasörünü arayın.
- Dosyanızı bu klasöre sürükleyin ve ardından dosyanın izninin doğru ayarlanıp ayarlanmadığını iki kez kontrol edin.
Dosyayı sahibi olarak yazabilir, okuyabilir ve düzenleyebilirsiniz, ancak üçüncü şahıslara izin verilmez. Dosyada bir “0644” izin kodu görünmelidir. Değilse, dosyaya sağ tıklayın ve “dosya izni”ni seçin.
Robots.txt dosyası: SEO için en iyi uygulamalar
Her yönerge için yeni bir satır kullanın
Her yönergeyi ayrı bir satırda bildirmeniz gerekir. Aksi takdirde arama motorlarının kafası karışacaktır.
Kullanıcı aracısı: *
İzin verme: /dizin/
İzin verme: /başka-dizin/
Talimatları basitleştirmek için joker karakterler kullanın
Tüm kullanıcı aracıları için joker karakterler (*) kullanabilir ve yönergeleri bildirirken URL modellerini eşleştirebilirsiniz. Joker karakter, tek tip bir desene sahip URL'ler için iyi çalışır. Örneğin, URL'lerinde soru işareti (?) bulunan tüm filtre sayfalarının taranmasını engellemek isteyebilirsiniz.
Kullanıcı aracısı: *
İzin verme: /*?
Bir URL'nin sonunu belirtmek için dolar işaretini "$" kullanın
Arama motorları, .pdf gibi uzantılarla biten URL'lere erişemez. Bu, /file.pdf dosyasına erişemeyecekleri, ancak “.pdf” ile bitmeyen /file.pdf?id=68937586 dosyasına erişebilecekleri anlamına gelir. Örneğin, arama motorlarının web sitenizdeki tüm PDF dosyalarına erişmesini engellemek istiyorsanız robots.txt dosyanız şöyle görünebilir:
Kullanıcı aracısı: *
İzin verme: /*.pdf$
Her kullanıcı aracısını yalnızca bir kez kullanın
Google'da aynı user-agent'ı bir kereden fazla kullanmanız önemli değildir. Çeşitli bildirimlerdeki tüm kuralları tek bir yönergede derleyecek ve onu izleyecektir. Ancak, her kullanıcı aracısını yalnızca bir kez bildirmek daha az kafa karıştırıcı olduğundan mantıklıdır.
Yönergelerinizi düzenli ve basit tutmak, kritik hata riskini azaltır. Örneğin, robots.txt dosyanız aşağıdaki kullanıcı aracılarını ve yönergelerini içeriyorsa.
Kullanıcı aracısı: Googlebot
İzin verme: /a/
Kullanıcı aracısı: Googlebot
İzin verme: /b/
İstenmeyen hataları önlemek için özel talimatları kullanın
Yönergeleri ayarlarken, belirli talimatları vermemek, SEO'nuza zarar verebilecek hatalar oluşturabilir. Çok dilli bir siteniz olduğunu ve /de/ alt dizini için Almanca bir sürüm üzerinde çalıştığınızı varsayalım.
Henüz hazır olmadığı için arama motorlarının buna erişmesini istemezsiniz. Aşağıdaki robots.txt dosyası, arama motorlarının bu alt klasörü ve içeriğini dizine eklemesini engeller:
Kullanıcı aracısı: *
İzin verme: /de
Ancak, arama motorlarının /de ile başlayan sayfaları veya dosyaları taramasını kısıtlar. Bu durumda, sonuna eğik çizgi eklemek basit çözümdür.
Kullanıcı aracısı: *
İzin verme: /de/
İçindekiler ↑Bir karma ile robots.txt dosyasına açıklama girin
Yorumlar, geliştiricilerin ve muhtemelen sizin bile robots.txt dosyanızı anlamanıza yardımcı olur. Yorum eklemek için satırı bir kare (#) ile başlatın. Tarayıcılar, bir karma ile başlayan satırları yok sayar.
# Bu, Bing botuna sitemizi taramaması talimatını verir.
Kullanıcı aracısı: Bingbot
izin verme: /
Her alt etki alanı için farklı robots.txt dosyaları kullanın
Robots.txt yalnızca ana bilgisayar etki alanında taramayı etkiler. Farklı bir alt etki alanında taramayı kısıtlamak için başka bir dosyaya ihtiyacınız olacak. Örneğin, ana web sitenizi example.com'da ve blogunuzu blog.example.com'da barındırıyorsanız, iki robots.txt dosyasına ihtiyacınız olacaktır. Birini ana etki alanının kök dizinine yerleştirin, diğer dosya ise blogun kök dizininde olmalıdır.
İyi içeriği engelleme
SEO sonuçları üzerinde olumsuz etkilerden kaçınmak için herkese açık hale getirmek istediğiniz kaliteli içeriği engellemek için robots.txt dosyası veya noindex etiketi kullanmayın. Sayfalarınızdaki noindex etiketlerini iyice kontrol edin ve kurallara izin vermeyin.
Tarama gecikmesini aşırı kullanmayın
Tarama gecikmesini açıkladık, ancak botların tüm sayfaları taramasını sınırladığı için bunu sık kullanmamalısınız. Bazı web siteleri için işe yarayabilir, ancak büyük bir web siteniz varsa sıralamanıza ve trafiğinize zarar veriyor olabilirsiniz.
Büyük/küçük harf duyarlılığına dikkat edin
Robots.txt dosyası büyük/küçük harf duyarlıdır, bu nedenle doğru biçimde bir robots dosyası oluşturduğunuzdan emin olmanız gerekir. Robots dosyası, tamamı küçük harflerle 'robots.txt' olarak adlandırılmalıdır. Aksi takdirde, işe yaramaz.
Diğer en iyi uygulamalar:
- Web sitenizin içeriğinin veya bölümlerinin taranmasını engellemediğinizden emin olun.
- Hassas verileri (özel kullanıcı bilgileri) SERP sonuçlarının dışında tutmak için robots.txt dosyasını kullanmayın. Diğer sayfalar doğrudan özel sayfaya bağlanırsa erişimi kısıtlamak için veri şifreleme veya noindex meta yönergesi gibi farklı bir yöntem kullanın.
- Bazı arama motorlarında birden fazla kullanıcı aracısı bulunur. Örneğin Google, organik aramalar için Googlebot'u ve resimler için Googlebot-Image'ı kullanır. Aynı arama motorundaki çoğu kullanıcı aracısı aynı kuralları izlediğinden, her arama motorunun birden çok tarayıcısı için yönergeler belirtmek gerekli değildir.
- Bir arama motoru robots.txt içeriğini önbelleğe alır ancak bunları günlük olarak günceller. Dosyayı değiştirir ve daha hızlı güncellemek isterseniz dosya URL'sini Google'a gönderebilirsiniz.
İçeriğin indekslenmesini önlemek için robots.txt'i kullanma
Bir sayfayı devre dışı bırakmak, botların sayfayı doğrudan taramasını önlemenin en etkili yoludur. Ancak, aşağıdaki durumlarda çalışmayacaktır:
- Başka bir kaynağın sayfaya bağlantıları varsa, botlar onu taramaya ve dizine eklemeye devam eder.
- Yasa dışı botlar içeriği taramaya ve dizine eklemeye devam edecek.
Özel içeriği korumak için robots.txt'yi kullanma
PDF'ler veya teşekkür sayfaları gibi bazı özel içerikler, botları engelleseniz bile dizine eklenebilir. Tüm özel sayfalarınızı bir oturum açma işleminin arkasına yerleştirmek, izin vermeme yönergesini güçlendirmenin en iyi yollarından biridir. İçeriğiniz kullanılabilir durumda kalacak, ancak ziyaretçileriniz ona erişmek için fazladan bir adım atacak.
Kötü niyetli yinelenen içeriği gizlemek için robots.txt kullanma
Yinelenen içerik, aynı dildeki diğer içerikle aynı veya çok benzer. Google, benzersiz içeriğe sahip sayfaları dizine eklemeye ve göstermeye çalışır. Örneğin, sitenizde her makalenin "normal" ve "yazıcı" sürümleri varsa ve noindex etiketi hiçbirini engellemiyorsa, bunlardan birini listeler.
Örnek robots.txt dosyaları
Aşağıda birkaç örnek robots.txt dosyası bulunmaktadır. Bunlar öncelikle fikir amaçlıdır, ancak bunlardan biri ihtiyaçlarınızı karşılarsa, kopyalayıp bir metin belgesine yapıştırın, “robots.txt” olarak kaydedin ve uygun dizine yükleyin.
Tüm botlar için tam erişim
Boş bir robots.txt dosyasına sahip olmak veya hiçbir dosya olmaması da dahil olmak üzere, arama motorlarına tüm dosyalara erişmelerini söylemenin birkaç yolu vardır.
Kullanıcı aracısı: *
İzin verme:
Tüm botlara erişim yok
Aşağıdaki robots.txt dosyası, tüm arama motorlarına sitenin tamamına erişmekten kaçınmaları talimatını verir:
Kullanıcı aracısı: *
izin verme: /
Tüm botlar için bir alt dizini engelle
Kullanıcı aracısı: *
İzin verme: /klasör/
Tüm botlar için bir alt dizini engelle (izin verilen bir dosyayla)
Kullanıcı aracısı: *
İzin verme: /klasör/
İzin ver: /klasör/sayfa.html
Tüm botlar için bir dosyayı engelle
Kullanıcı aracısı: *
İzin verme: /this-is-a-file.pdf
Tüm botlar için bir dosya türünü (PDF) engelle
Kullanıcı aracısı: *
İzin verme: /*.pdf$
Yalnızca Googlebot için tüm parametreli URL'leri engelle
Kullanıcı aracısı: Googlebot
İzin verme: /*?
robots.txt dosyanızda hatalar için nasıl test edilir
Robots.txt dosyasındaki hatalar ciddi olabilir, bu nedenle bunları izlemek önemlidir. robot.txt ile ilgili sorunlar için Search Console'daki "Kapsam" raporunu düzenli olarak kontrol edin. Karşılaşabileceğiniz hatalardan bazıları, ne anlama geldikleri ve nasıl düzeltileceği aşağıda listelenmiştir.
Gönderilen URL robots.txt tarafından engellendi
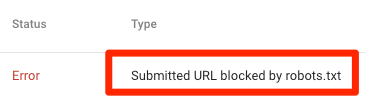
robots.txt dosyasının site haritalarınızdaki URL'lerden en az birini engellediğini gösterir. Site haritanız doğruysa ve kurallı, dizine eklenmemiş veya yeniden yönlendirilmiş sayfalar içermiyorsa, robots.txt gönderdiğiniz sayfaları engellememelidir. Varsa, etkilenen sayfaları belirleyin ve bloğu robots.txt dosyanızdan kaldırın.
Engelleme yönergesini belirlemek için Google'ın robots.txt test aracını kullanabilirsiniz. Robots.txt dosyanızı düzenlerken dikkatli olun çünkü bir hata diğer sayfaları veya dosyaları etkileyebilir.
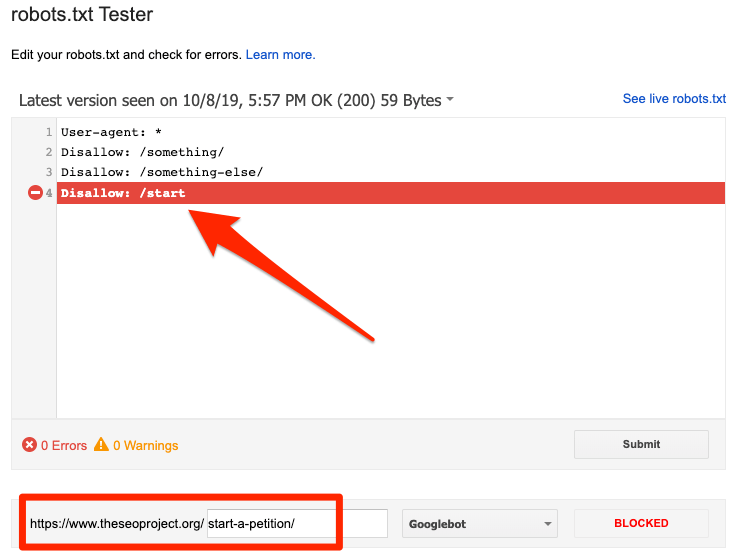
robots.txt tarafından engellendi
Bu hata, robots.txt dosyasının Google'ın dizine ekleyemediği içeriği engellediğini gösterir. Bu içerik çok önemliyse ve dizine eklenmesi gerekiyorsa, robots.txt dosyasındaki tarama bloğunu kaldırın. (Ayrıca, içeriğin indekslenmemiş olup olmadığını kontrol edin.)
İçeriği Google'ın dizininden hariç tutmak istiyorsanız, bir robotun meta etiketini veya x-robots-header'ını kullanın ve tarama bloğunu kaldırın. İçeriği Google dizininin dışında tutmanın tek yolu budur.
Dizine eklendi, ancak robots.txt tarafından engellendi
Bu, Google'ın robots.txt tarafından engellenen içeriğin bir kısmını hâlâ dizine eklediği anlamına gelir. Robots.txt, içeriğinizin Google arama sonuçlarında görüntülenmesini engellemenin çözümü değildir.
Dizine eklemeyi önlemek için tarama bloğunu kaldırın ve bir meta robots etiketi veya x-robots-tag HTTP başlığı ile değiştirin. Bu içeriği yanlışlıkla engellediyseniz ve Google'ın onu dizine eklemesini istiyorsanız, robots.txt dosyasındaki tarama bloğunu kaldırın. İçeriğin Google aramalarında görünürlüğünü artırmaya yardımcı olabilir.
Robots.txt vs meta robotlar vs x-robotlar
Bu üç robot komutunu farklı kılan nedir? Robots.txt basit bir metin dosyasıdır, meta ve x-robots ise meta yönergelerdir. Temel rollerinin ötesinde, üçünün farklı işlevleri vardır. Robots.txt, tüm web sitesi veya dizin için tarama davranışını belirtirken meta ve x-robots, tek tek sayfalar (veya sayfa öğeleri) için dizin oluşturma davranışını tanımlar.
daha fazla okuma
Yararlı kaynaklar
- Vikipedi: Robotları Dışlama Protokolü
- Google'ın Robots.txt ile ilgili belgeleri
- Robots.txt üzerinde Bing (ve Yahoo) Belgeleri
- Direktifler açıklandı
- Robots.txt ile ilgili Yandex belgeleri
toparlamak
Robot.txt dosyasının önemini ve genel SEO uygulamanıza ve web sitesi karlılığına katkılarını tam olarak anladığınızı umuyoruz. Hala web sitenizden gelir elde etmekte zorlanıyorsanız, Adsterra reklamlarıyla kazanmaya başlamak için kodlamaya ihtiyacınız olmayacak. HTML, WordPress veya Blogger web sitenize bir reklam kodu koyun ve bugün kâr etmeye başlayın!