
使用 Python 进行动态网页抓取 – 操作指南
已发表: 2024-06-08动态网页抓取涉及从通过 JavaScript 或 Python 实时生成内容的网站检索数据。 与静态网页不同,动态内容是异步加载的,这使得传统的抓取技术效率低下。
动态网页抓取用途:
- 基于 AJAX 的网站
- 单页应用程序 (SPA)
- 具有延迟加载元素的网站
关键工具和技术:
- Selenium – 自动化浏览器交互。
- BeautifulSoup – 解析 HTML 内容。
- 请求– 获取网页内容。
- lxml – 解析 XML 和 HTML。
动态网络抓取Python需要更深入地了解网络技术才能有效地收集实时数据。
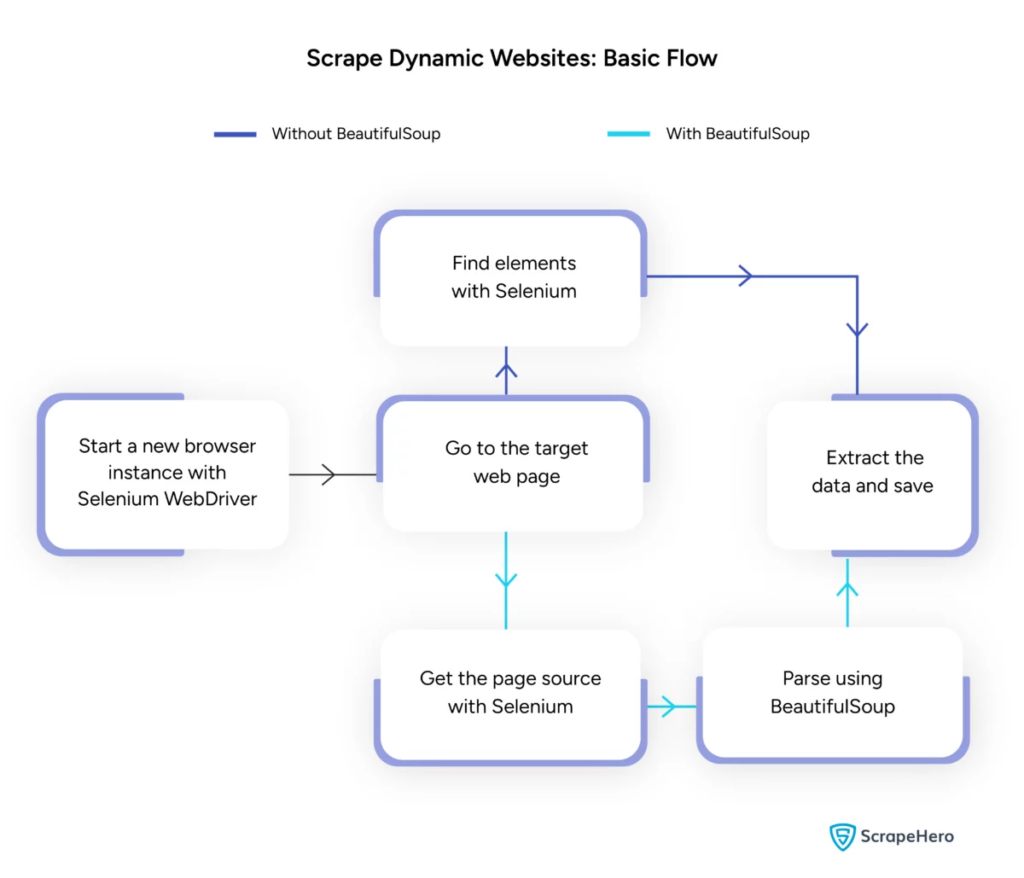
图片来源:https://www.scrapehero.com/scrape-a-dynamic-website/
设置Python环境
要开始动态 Web 抓取 Python,必须正确设置环境。 按着这些次序:
- 安装 Python :确保机器上安装了 Python。 最新版本可以从Python官方网站下载。
- 创建虚拟环境:

激活虚拟环境:

- 安装所需的库:

- 设置代码编辑器:使用 PyCharm、VSCode 或 Jupyter Notebook 等 IDE 来编写和运行脚本。
- 熟悉 HTML/CSS :了解网页结构有助于有效导航和提取数据。
这些步骤为动态网页抓取 Python 项目奠定了坚实的基础。
了解 HTTP 请求的基础知识
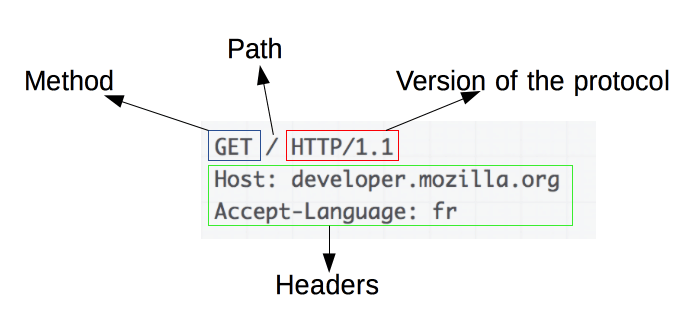
图片来源:https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
HTTP 请求是网页抓取的基础。 当客户端(例如 Web 浏览器或 Web scraper)想要从服务器检索信息时,它会发送 HTTP 请求。 这些请求遵循特定的结构:
- Method :要执行的操作,例如 GET 或 POST。
- URL :资源在服务器上的地址。
- headers :有关请求的元数据,例如内容类型和用户代理。
- Body :随请求发送的可选数据,通常与 POST 一起使用。
了解如何解释和构建这些组件对于有效的网络抓取至关重要。 像 requests 这样的 Python 库简化了这个过程,允许对请求进行精确控制。
安装Python库
图片来源:https://ajaytech.co/what-are-python-libraries/
对于使用 Python 进行动态网页抓取,请确保安装了 Python。 打开终端或命令提示符并使用 pip 安装必要的库:
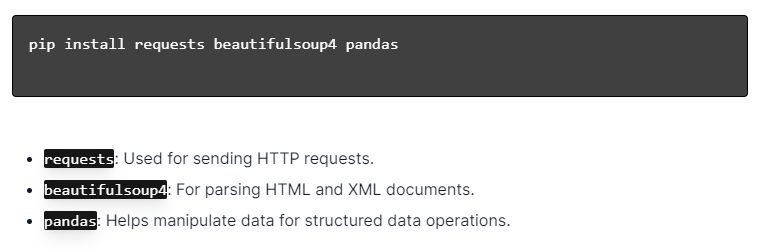
接下来,将这些库导入到您的脚本中:

通过这样做,每个库都可用于网络抓取任务,例如发送请求、解析 HTML 和有效管理数据。

构建简单的网页抓取脚本
要使用 Python 构建基本的动态网页抓取脚本,必须首先安装必要的库。 “requests”库处理 HTTP 请求,而“BeautifulSoup”则解析 HTML 内容。
遵循的步骤:
- 安装依赖项:

- 导入库:

- 获取 HTML 内容:
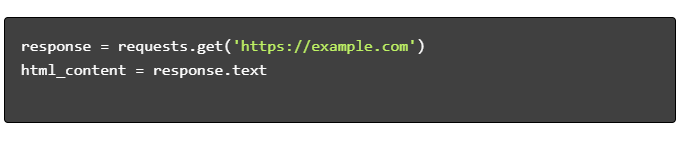
- 解析 HTML:

- 提取数据:

使用 Python 处理动态网页抓取
动态网站动态生成内容,通常需要更复杂的技术。
考虑以下步骤:
- 识别目标元素:检查网页以查找动态内容。
- 选择 Python 框架:利用 Selenium 或 Playwright 等库。
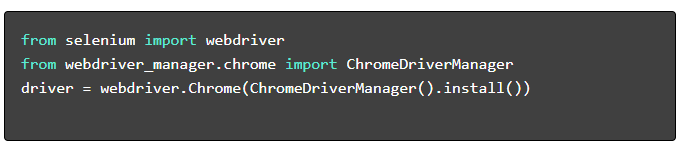
- 安装所需的软件包:
- 设置网络驱动程序:

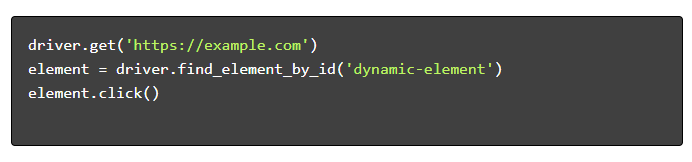
- 导航和交互:
网页抓取最佳实践
建议遵循网络抓取最佳实践,以确保效率和合法性。 以下是关键准则和错误处理策略:
- 尊重 Robots.txt :始终检查目标站点的 robots.txt 文件。
- 限制:实施延迟以防止服务器过载。
- User-Agent :使用自定义的 User-Agent 字符串以避免潜在的阻塞。
- 重试逻辑:使用 try- except 块并设置重试逻辑来处理服务器超时。
- 日志记录:维护全面的日志以进行调试。
- 异常处理:专门捕获网络错误、HTTP错误和解析错误。
- 验证码检测:结合检测和解决或绕过验证码的策略。
常见的动态网页抓取挑战
验证码
许多网站使用验证码来防止自动机器人。 要绕过这个:
- 使用 2Captcha 等验证码解决服务。
- 实施人为干预来解决验证码。
- 使用代理来限制请求率。
IP封锁
站点可能会阻止发出过多请求的 IP。 通过以下方式解决这个问题:
- 使用轮换代理。
- 实施请求限制。
- 采用用户代理轮换策略。
JavaScript 渲染
有些网站通过 JavaScript 加载内容。 通过以下方式应对这一挑战:
- 使用 Selenium 或 Puppeteer 实现浏览器自动化。
- 使用 Scrapy-splash 渲染动态内容。
- 探索无头浏览器与 JavaScript 交互。
法律问题
网络抓取有时会违反服务条款。 通过以下方式确保合规性:
- 咨询法律意见。
- 抓取可公开访问的数据。
- 遵守 robots.txt 指令。
数据解析
处理不一致的数据结构可能具有挑战性。 解决方案包括:
- 使用 BeautifulSoup 等库进行 HTML 解析。
- 使用正则表达式进行文本提取。
- 使用 JSON 和 XML 解析器处理结构化数据。
存储和分析抓取的数据
存储和分析抓取的数据是网络抓取的关键步骤。 决定数据的存储位置取决于数据的容量和格式。 常见的存储选项包括:
- CSV 文件:易于处理小型数据集和简单分析。
- 数据库:用于结构化数据的 SQL 数据库; NoSQL 用于非结构化。
存储后,可以使用 Python 库来分析数据:
- Pandas :非常适合数据操作和清理。
- NumPy :高效的数值运算。
- Matplotlib 和 Seaborn :适合数据可视化。
- Scikit-learn :提供机器学习工具。
正确的数据存储和分析可以提高数据的可访问性和洞察力。
结论和后续步骤
在了解了动态 Web 抓取 Python 后,有必要微调对突出显示的工具和库的理解。
- 检查代码:查阅最终脚本并尽可能模块化以增强可重用性。
- 其他库:探索 Scrapy 或 Splash 等高级库以满足更复杂的需求。
- 数据存储:考虑强大的存储选项 - SQL 数据库或用于管理大型数据集的云存储。
- 法律和道德考虑:及时了解有关网络抓取的法律准则,以避免潜在的侵权行为。
- 下一个项目:处理具有不同复杂性的新网络抓取项目将进一步巩固这些技能。
希望将专业的动态网页抓取与 Python 集成到您的项目中? 对于那些需要大规模数据提取而又无需复杂的内部处理的团队,PromptCloud 提供了量身定制的解决方案。 探索 PromptCloud 的服务以获得强大、可靠的解决方案。 今天就联系我们吧!