
集市之声
已发表: 2024-04-24这篇关于遗留系统现代化的文章是我最近在面向软件公司的 AWS 数据峰会上发表的演讲的姊妹篇,内容是通过利用我们的最佳实践从数据中创造价值,以确保机器学习项目的成功。 如果您愿意,可以直接跳到底部观看。
让我们面对现实吧:软件编写起来比维护起来容易。 这就是为什么我们作为软件工程师更喜欢“把它撕下来并重新开始”,而不是试图理解另一个开发人员(或我们过去的自己)的想法。 我们似乎集体忘记了“程序必须编写供人阅读,并且只是顺便供机器执行”。
你知道这是真的——我们都必须费尽心力地追溯一锅意大利面条式的代码和薄薄的、旧世界风格的抽象,挖掘程序的核心内容,结果却发现除了盘子底部的一团糟之外什么也没有。
人们很容易大喊“WTF”并责怪以前的开发人员,但事实往往更加复杂。 我们看不到未来,因此当我们设计一个全新的系统时,不可能了解需求、技术或业务目标将如何增长。 因此,随着系统范围的扩大以及业务对系统的依赖,系统可能会变得不可读。 这有点自相矛盾:较旧、难以维护的系统往往提供最大的价值。 他们很难工作,因为他们与公司一起成长,也很可怕,因为打破它可能是一场灾难。
这就是我要提醒你的地方:如果你喜欢困难的、有回报的问题……那就试试吧。 采用您拥有的最旧的系统并使其可维护。 你知道我正在谈论的那个——没有人会“拥有”的那个。 其他部门依赖但工程师讨厌的那个。 您必须首先修补 Log4Shell 的那个。 做吧。 我赌你。
我最近有这样的机会更新 Bazaarvoice 已有十年历史的机器学习系统。 从表面上看,这听起来并不令人兴奋:这东西甚至没有神经网络! 谁在乎! 嗯……这很重要。 该系统几乎处理 Bazaarvoice 收到的所有用户生成的产品评论(每月近 900 万条),并对机器学习模型进行 9000 万次推理调用。 是的——9000 万次推论! 规模很大,我迫不及待地想潜入其中。
在这篇文章中,我将分享如何通过重新架构(而不是重写)对遗留系统进行现代化改造,使我们能够使其具有可扩展性和成本效益,而无需删除所有代码并重新开始。 由此产生的系统是无服务器、容器化且可维护的,同时将我们的托管成本降低了近 80%。
什么是遗留系统?
遗留系统是指仍在运行的老化计算软件和/或硬件。 虽然它仍然可以实现其最初的目的,但缺乏未来增长的可扩展性。
旧的遗留系统
首先,让我们看一下我们正在处理的事情。 我的团队正在更新的旧系统负责管理所有 Bazaarvoice 的用户生成内容。 具体来说,它确定每条内容是否适合我们客户的网站。

这听起来很简单——消除仇恨言论、粗俗语言或招揽等明显的违规行为——但在实践中,情况要微妙得多。 每个客户对于他们认为合适的东西都有独特的要求。 例如,啤酒品牌希望讨论酒精问题,但儿童品牌可能不会。 当我们加入新客户时,我们会捕获这些特定于客户的选项,并且我们的客户服务团队将它们编码到管理数据库中。
为了增加一些复杂性,我们还对一部分内容进行采样,由人工审核员进行审核。 这使我们能够不断衡量模型的性能并发现构建更多模型的机会。
我们遗留系统的完整架构如下所示:
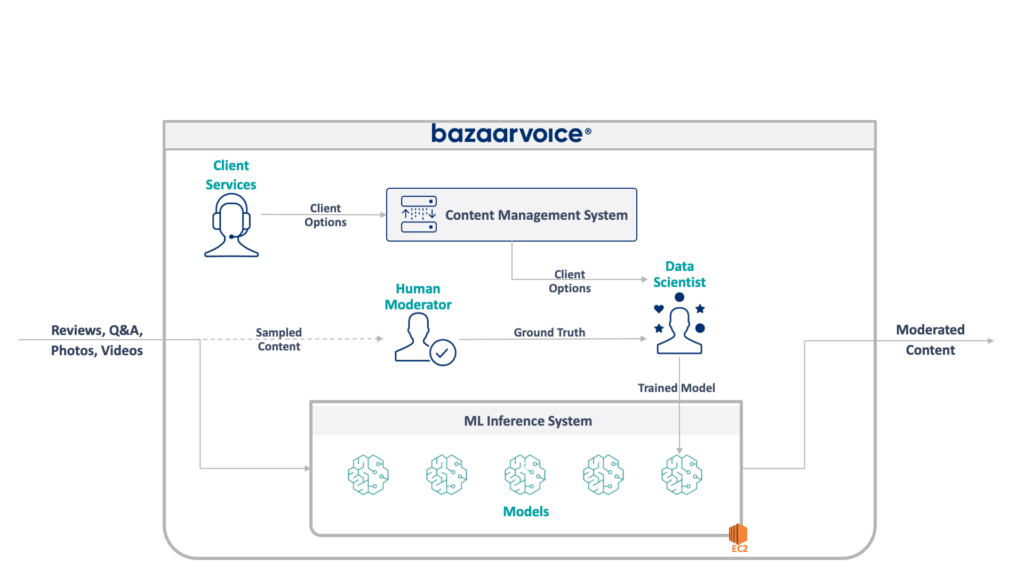
该系统有一些严重的缺点。 具体来说,所有模型都托管在单个 EC2 实例上。 这并不是由于糟糕的工程设计,而是由于最初的程序员无法预见公司所需的规模。 没有人想到它会成长到如此程度。
此外,该系统还遭到了开发人员的拒绝:它是用 Scala 编写的,很少有工程师能理解。 因此,它经常被忽视,因为没有人愿意碰它。
结果,系统继续以持续增长的方式增长。 一旦我们开始重新构建它,它就在单个 x1e.8xlarge 实例上运行。 这个东西有近 1 TB 的内存,每月运行成本约为 5,000 美元(未预留)。 不过,不用担心,我们刚刚推出了第二个用于冗余的产品和第三个用于质量检查的产品。
该系统的运行成本很高,并且失败的风险很高(一个错误的模型可能会导致整个服务瘫痪)。 此外,代码库尚未得到积极开发,因此与现代数据科学包相比明显过时,并且不遵循我们用 Scala 编写的服务的标准实践。
新系统
在重新设计这个系统时,我们有一个明确的目标:使其可扩展。 降低运营成本是次要目标,简化模型和代码管理也是如此。
我们提出的新设计如下图所示:

我们解决所有这些问题的方法是将每个机器学习模型放在一个隔离的 SageMaker Serverless 端点上。 与 AWS Lambda 函数一样,无服务器端点在不使用时会关闭,从而为我们节省不常用模型的运行时成本。 它们还可以快速扩展以响应流量的增加。

此外,我们将客户端选项公开给单个微服务,该微服务将内容路由到适当的模型。 这是我们必须编写的大部分新代码:一个易于维护的小型 API,可以让我们的数据科学家更轻松地更新和部署新模型。
这种方法有以下好处:
- 将实现价值的时间缩短了 6 倍以上。 具体来说,将流量路由到现有模型是即时的,并且部署新模型可以在 5 分钟内完成,而不是 30 分钟
- 规模无限制——我们目前有 400 个模型,但计划扩展到数千个,以继续增加我们可以自动调节的内容量
- 迁移 EC2 后成本降低了 82%,因为功能在不使用时关闭,而且我们不会为未充分利用的顶级机器付费
然而,简单地设计一个理想的架构并不是重建遗留系统真正有趣的困难部分——您必须迁移到它。
我们迁移中的第一个挑战是弄清楚如何将 Java WEKA 模型迁移到 SageMaker 上运行,更不用说 SageMaker Serverless 了。
幸运的是,SageMaker 在 Docker 容器中部署模型,因此至少我们可以冻结 Java 和依赖项版本以匹配我们的旧代码。 这将有助于确保新系统中托管的模型返回与旧系统相同的结果。

为了使容器与 SageMaker 兼容,您所需要做的就是实现一些特定的 HTTP 端点:
-
POST /invocation— 接受输入、执行推理并返回结果。 -
GET /ping— 如果 JVM 服务器正常则返回 200
(我们选择忽略 BYO 多模型容器和 SageMaker 推理工具包周围的所有问题。)
围绕 com.sun.net.httpserver.HttpServer 进行一些快速抽象,我们就可以开始了。
你知道吗? 这其实很有趣。 摆弄 Docker 容器并将已有 10 年历史的东西强行引入 SageMaker Serverless 中,有一点修补的感觉。 当我们让它工作时,这是非常令人兴奋的——特别是当我们使用遗留系统代码在新的 sbt 堆栈而不是 Maven 中构建它时。
新的 sbt 堆栈使其易于使用,容器化确保我们在 SageMaker 环境中运行时可以获得正确的行为。
迁移到新系统
因此,我们将模型放在容器中,并且可以将它们部署到 SageMaker——差不多完成了,对吧? 不完全的。
迁移到新架构的惨痛教训是,您必须构建三倍于实际系统的数据才能支持迁移。 除了新系统之外,我们还必须构建:
- 旧系统中的数据捕获管道用于记录模型的输入和输出。 我们用这些来确认新系统会返回相同的结果
- 新系统中的数据处理管道用于计算结果并将其与旧系统中的数据进行比较。 这涉及使用 Datadog 进行大量测量,并且需要在发现差异时提供重播数据的能力
- 完整的模型部署系统,以避免影响旧系统的用户(只需将模型上传到 S3)。 我们知道我们最终希望将它们转移到 API,但对于初始版本,我们需要无缝地做到这一点
所有这些都是一次性代码,我们知道一旦完成所有用户的迁移就可以扔掉,但我们仍然必须构建它并确保新系统的输出与旧系统相匹配。
预先期待这一点。
虽然在这个项目上构建迁移工具和系统确实花费了我们 60% 以上的工程时间,但这也是一次有趣的体验。 单元测试变得更像数据科学实验:我们编写了整个套件以确保我们的输出完全匹配。 正是这种不同的思维方式让工作变得更加有趣。 如果你愿意的话,这是我们正常框框之外的一步。
通过重新架构实现遗留系统的现代化
下次当您想从代码开始重建系统时,我想鼓励您尝试迁移架构而不是代码。 您会发现有趣且有益的技术挑战,并且可能比调试新代码的意外边缘情况更喜欢它。
想了解更多吗? 请观看下面我在 AWS 数据峰会上发表的演讲,其中深入探讨了 MLOps 方面的问题。