
ChatGPT 可能如何影响网络抓取格局
已发表: 2023-09-15近年来,网络抓取已成为增长的代名词。
这是因为对于组织来说,这是一种非常有益的方法来收集市场情报并利用它来改进产品。
随着 ChatGPT 等新技术的进步,网络抓取领域似乎有可能发生更多变化。
让我们来看看这些影响、挑战以及对网络抓取未来的担忧。
网页抓取 ChatGPT
ChatGPT 是 OpenAI 开发的一种语言模型,能够生成看似由人类编写的文本。 它接受了大量互联网文本的训练,使其能够理解并生成连贯且上下文相关的响应。 这使其成为对话式人工智能应用程序和客户支持聊天机器人的极其强大的工具。
然而,ChatGPT 的引入也对网络抓取产生了更广泛的影响,网络抓取是一种广泛用于从网站提取数据的技术。 网络抓取涉及从网页中自动提取数据,使组织能够收集信息以进行分析、市场研究或竞争情报。

图片来源:Medium
让我们更深入地研究 ChatGPT 如何影响网络抓取领域。
对数据可访问性的影响
随着 ChatGPT 的出现,从网站访问和提取数据可能变得更具挑战性。 传统的网页抓取技术依赖于从网站的 HTML 结构中解析和提取数据。 然而,ChatGPT 生成类似人类响应的能力对传统的抓取方法提出了挑战。
由于 ChatGPT 可以理解并响应查询,因此网站可以实现对话界面,用户可以在其中与 ChatGPT 支持的系统交互以检索数据或执行操作。 这种被称为“ChatGPT 抓取”的方法可能会受到网站所有者的欢迎,因为它为访问者提供了更加用户友好和互动的体验。

虽然这可以提高用户参与度,但它为依赖解析 HTML 的传统网络抓取技术带来了潜在的障碍。 ChatGPT 的对话性质使得传统的抓取工具很难导航这些新界面并提取所需的数据。
网络抓取的挑战增加
ChatGPT 的兴起给网络抓取带来了一系列挑战。 首先,ChatGPT 界面的动态性和交互性使得抓取过程更加复杂。 这些界面通常利用 JavaScript 来动态加载内容、修改 DOM 并处理用户交互。 这对传统的抓取工具提出了重大挑战——背离了最佳实践——因为它们主要是为了提取静态 HTML 内容而设计的。
此外,ChatGPT 的响应可以是上下文驱动的,从而导致生成的 HTML 结构发生变化。 底层 HTML 的这种可变性会使网络抓取变得更加困难,因为抓取工具需要适应这些动态变化以一致地提取所需的数据。
另一个问题是网站所有者越来越多地使用复杂的反抓取技术,这使得抓取过程进一步复杂化。 这些技术包括验证码挑战、IP 阻止、请求限制等。 由于 ChatGPT 使网站能够实现对话界面,我们可以预期对用户交互的重视程度会越来越高,这使得传统的抓取工具更难绕过这些障碍。
道德问题和影响
与任何技术进步一样,ChatGPT 对网络抓取的影响也存在伦理问题。 主要担忧之一是对数据所有权和隐私的潜在影响。
随着 ChatGPT 抓取的兴起,网站可以更好地控制其数据的访问和使用方式。 虽然这使网站所有者能够为其数据提供更安全和受控的环境,但它也可能限制出于合法抓取目的的数据可访问性。 这可能会对严重依赖公开数据的学术研究、市场分析和公共利益组织等行业产生负面影响。
此外,使用 ChatGPT 进行抓取可以模糊人类生成的内容和人工智能生成的内容之间的界限。 这引发了对通过抓取收集的数据的准确性、可靠性和真实性的质疑。 对于组织来说,确保数据收集过程的透明度和问责制以维持用户和利益相关者之间的信任变得至关重要。
网页抓取的未来
尽管 ChatGPT 带来了挑战,但网络抓取将继续在数据采集和分析中发挥至关重要的作用。 然而,传统的抓取技术可能需要发展以适应不断变化的环境。
为了克服 ChatGPT 带来的挑战,抓取工具可能需要结合先进的技术,例如基于浏览器的抓取和人工智能驱动的解析算法。 这些高级工具可以从动态 Web 界面中提取数据,并准确解释 ChatGPT 生成的内容中的上下文变化。
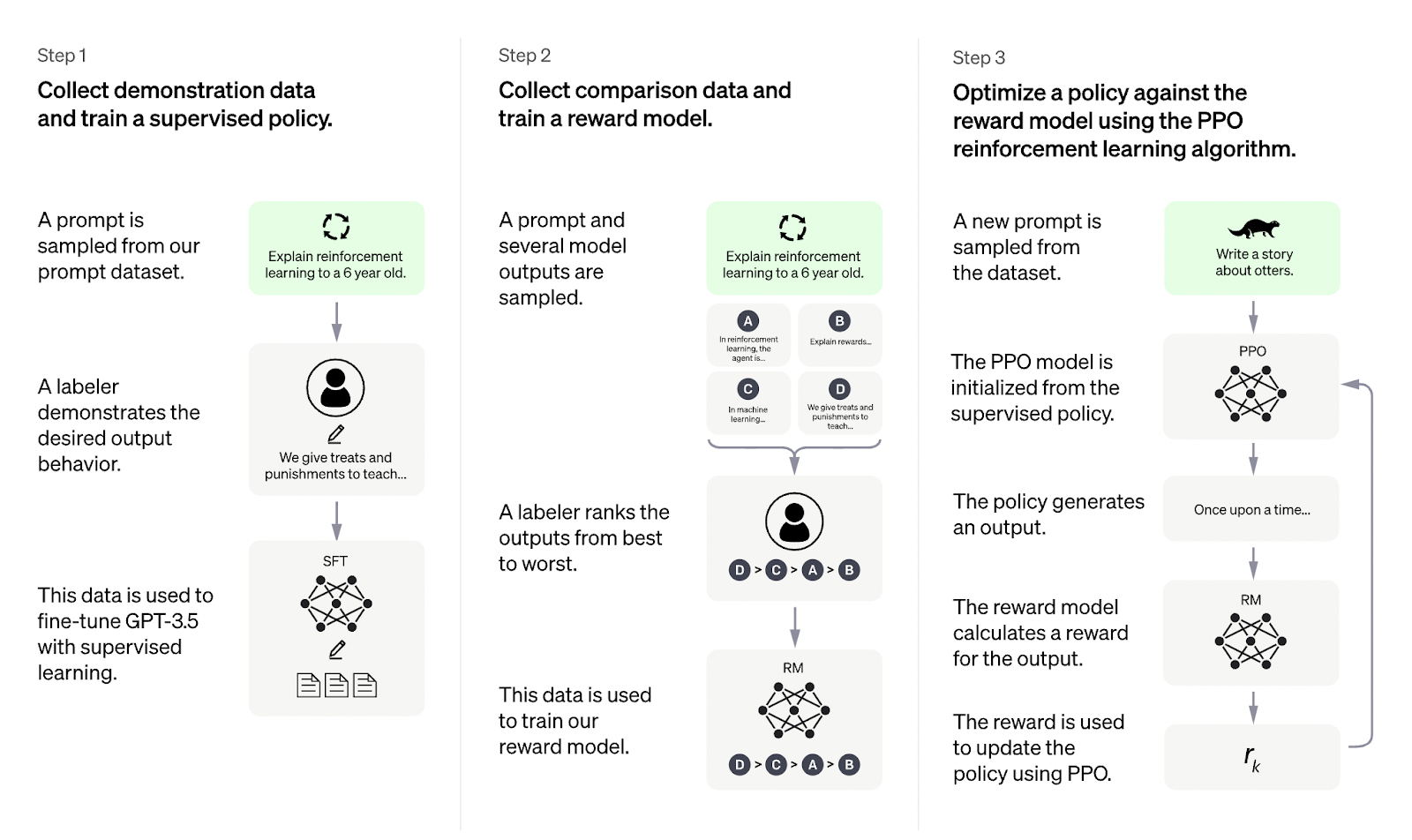
图片来源:Apify 博客
此外,网络抓取工具开发人员和语言模型研究人员之间的合作可以创建特定的方法和工具,以有效地抓取 ChatGPT 支持的界面。
结论
ChatGPT 的引入无疑给网络抓取格局带来了重大变化。
虽然它可能带来挑战,但它也为刮擦技术的创新和进步开辟了新的机会。 随着技术的不断发展,企业、组织和研究人员必须适应并找到合乎道德的方式来驾驭不断变化的网络抓取环境,确保人工智能驱动的世界中的数据可访问性、隐私性和数据准确性。