
网络爬虫如何工作
已发表: 2023-12-05网络爬虫在对互联网上存在的大量信息进行索引和结构化方面发挥着至关重要的作用。 他们的角色包括遍历网页、收集数据并使其可搜索。 本文深入研究网络爬虫的机制,深入了解其组件、操作和不同类别。 让我们深入了解网络爬虫的世界吧!
什么是网络爬虫
网络爬虫,称为蜘蛛或机器人,是一种自动化脚本或程序,旨在有条不紊地浏览互联网网站。 它以种子 URL 开始,然后沿着 HTML 链接访问其他网页,形成一个可以索引和分析的互连页面网络。
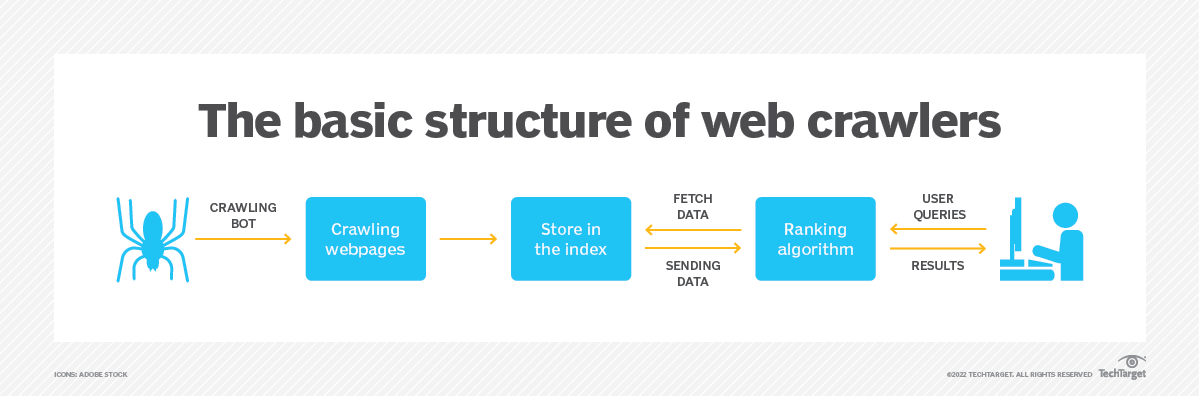
图片来源:https://www.techtarget.com/
网络爬虫的目的
网络爬虫的主要目标是从网页收集信息并生成可搜索索引以进行有效检索。 Google、Bing 和 Yahoo 等主要搜索引擎严重依赖网络爬虫来构建搜索数据库。 通过对网络内容的系统检查,搜索引擎可以向用户提供相关且最新的搜索结果。
值得注意的是,网络爬虫的应用范围超出了搜索引擎的范围。 它们还被各种组织用于数据挖掘、内容聚合、网站监控甚至网络安全等任务。
网络爬虫的组成部分
网络爬虫由多个组件组成,这些组件协同工作以实现其目标。 以下是网络爬虫的关键组件:
- URL Frontier:该组件管理等待抓取的 URL 集合。 它根据相关性、新鲜度或网站重要性等因素对 URL 进行优先级排序。
- 下载器:下载器根据URL前沿提供的URL检索网页。 它将 HTTP 请求发送到 Web 服务器、接收响应并保存获取的 Web 内容以供进一步处理。
- 解析器:解析器处理下载的网页,提取有用的信息,例如链接、文本、图像和元数据。 它分析页面的结构并提取要添加到 URL 前沿的链接页面的 URL。
- 数据存储:数据存储组件存储收集到的数据,包括网页、提取的信息和索引数据。 该数据可以以各种格式存储,例如数据库或分布式文件系统。
网络爬虫如何工作
了解了所涉及的元素后,让我们深入研究阐明网络爬虫功能的顺序过程:

- 种子 URL:爬网程序从种子 URL 开始,该种子可以是任何网页或 URL 列表。 该 URL 将添加到 URL 前沿以启动爬网过程。
- 抓取:爬虫从URL边界中选择一个URL,并向相应的Web服务器发送HTTP请求。 服务器响应网页内容,然后由下载器组件获取。
- 解析:解析器处理获取的网页,提取相关信息,例如链接、文本和元数据。 它还识别页面上找到的新 URL 并将其添加到 URL 边界。
- 链接分析:爬虫根据相关性、新鲜度或重要性等特定标准对提取的 URL 进行优先级排序并将其添加到 URL 前沿。 这有助于确定爬网程序访问和爬网页面的顺序。
- 重复过程:爬虫通过从 URL 前沿选择 URL、获取其 Web 内容、解析页面并提取更多 URL 来继续该过程。 重复此过程,直到没有更多的 URL 可供爬网,或达到预定义的限制。
- 数据存储:在整个爬取过程中,采集到的数据都存储在数据存储组件中。 该数据稍后可用于索引、分析或其他目的。
网络爬虫的类型
网络爬虫有不同的变体并具有特定的用例。 以下是一些常用的网络爬虫类型:
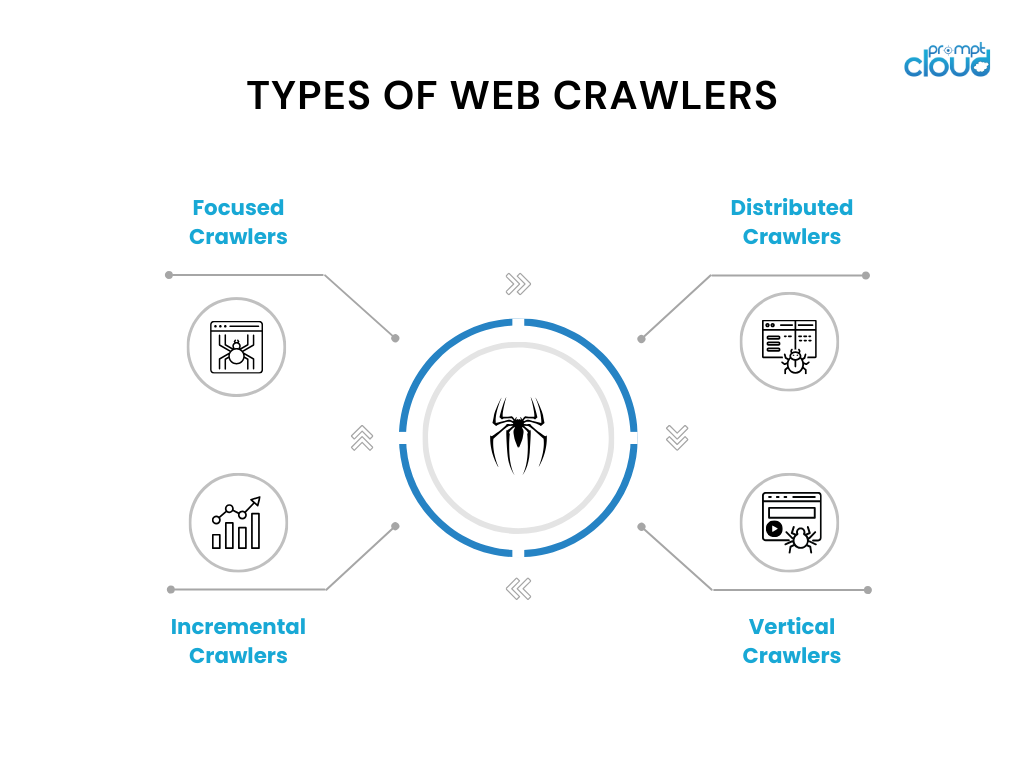
- 聚焦爬虫:这些爬虫在特定域或主题内运行,并爬行与该域相关的页面。 示例包括用于新闻网站或研究论文的主题爬虫。
- 增量爬虫:增量爬虫专注于爬行自上次爬行以来的新内容或更新内容。 他们利用时间戳分析或更改检测算法等技术来识别和抓取修改的页面。
- 分布式爬虫:在分布式爬虫中,多个爬虫实例并行运行,分担爬取大量页面的工作量。 这种方法可以加快抓取速度并提高可扩展性。
- 垂直爬虫:垂直爬虫针对网页中特定类型的内容或数据,例如图像、视频或产品信息。 它们旨在为专门的搜索引擎提取和索引特定类型的数据。
您应该多久抓取一次网页?
抓取网页的频率取决于几个因素,包括网站的大小和更新频率、页面的重要性以及可用资源。 某些网站可能需要频繁爬网以确保将最新信息编入索引,而其他网站可能不那么频繁地爬网。
对于高流量网站或内容快速变化的网站,更频繁的爬网对于维护最新信息至关重要。 另一方面,较小的网站或更新不频繁的页面可以不那么频繁地爬行,从而减少所需的工作量和资源。
内部网络爬虫与网络爬虫工具
在考虑创建网络爬虫时,评估复杂性、可扩展性和必要的资源至关重要。 从头开始构建爬虫可能是一项耗时的工作,包括管理并发、监督分布式系统和解决基础设施障碍等活动。 另一方面,选择网络爬行工具或框架可以提供更快、更有效的解决方案。
或者,使用网络爬虫工具或框架可以提供更快、更有效的解决方案。 这些工具提供可定制的爬行规则、数据提取功能和数据存储选项等功能。 通过利用现有工具,开发人员可以专注于他们的特定需求,例如数据分析或与其他系统的集成。
然而,考虑与使用第三方工具相关的限制和成本至关重要,例如定制限制、数据所有权和潜在定价模型。
结论
搜索引擎严重依赖网络爬虫,网络爬虫有助于对互联网上存在的大量信息进行整理和编目。 掌握网络爬虫的机制、组件和不同类别可以更深入地了解支撑这一基本过程的复杂技术。
无论是选择从头开始构建网络爬虫还是利用现有的网络爬虫工具,都必须采用符合您特定需求的方法。 这需要考虑可扩展性、复杂性和您可以使用的资源等因素。 通过考虑这些因素,您可以有效地利用网络爬行来收集和分析有价值的数据,从而推动您的业务或研究工作向前发展。
在 PromptCloud,我们专注于网络数据提取,从公开可用的在线资源中获取数据。 请通过sales@promptcloud.com与我们联系