
如何阻止人工智能抓取您的内容
已发表: 2023-10-24人工智能生成工具(例如 Google Bard 和 Bing Chat)是根据包括网络在内的许多内容源构建的。 令许多人感到惊讶的是,搜索引擎一直在悄悄地根据他们在爬行传统网络搜索时找到的所有内容来训练他们的人工智能模型。
必应和谷歌现已宣布阻止内容用于人工智能训练的方法,同时保留网络搜索索引。
那么,你应该阻止人工智能吗?你该如何阻止呢?
- 你应该阻止人工智能吗?
- 如何阻止人工智能机器人?
- 如何阻止 Bing 的 AI
- 如何阻止谷歌的人工智能
- 如何阻止 ChatGPT
- 测试
你应该阻止人工智能吗?
制造自己产品的公司可能会认为将其内容包含在人工智能模型中是有好处的。 技术规格或产品支持等信息可能有助于销售并降低客户支持成本。
但对于许多其他在线企业来说,内容就是他们的产品。 人们担心,投入在内容创作上的精力将被用来改进大型科技公司拥有的人工智能产品,而不会以流量的形式提供任何价值。
谷歌和必应正在尝试寻找方法来信任来源并提供一些推荐流量,但它可能比传统的网络搜索要少,而且更有可能是交易性的而不是信息性的搜索查询。
需要注意的是,阻止这些 AI 的内容不会影响爬行行为。 谷歌表示,“robots.txt 用户代理令牌用于控制能力。” 机器人将正常抓取您的网站以构建搜索索引。
如果搜索引擎已经被阻止抓取某些页面,则无需专门针对 AI 来阻止它们。
如何阻止人工智能机器人?
目前可以使用大多数 SEO 熟悉的方法、robots.txt 文件和页面级 robots 指令来阻止 Google、Bing 和 ChatGPT。
Google 和 ChatGPT 选择了 robots.txt 方法,该方法允许您指定 URL 模式,而 Bing 选择使用应用于各个页面的 robots 指令。
robots.txt 的优点是可以轻松地在一个地方为整个网站进行配置。 与页面级机器人指令相比,哪些 URL 被阻止是非常透明的,必须通过获取每个页面进行测试。
如何阻止 Bing 的 AI
Bing 会查找 nocache 或 noarchive robots 指令,这些指令可以作为元标记或 X-Robots-Tag 响应标头添加到页面中。
Nocache 将允许在训练 Microsoft 的 AI 模型时仅使用 URL、标题和片段将页面包含在 Bing Chat 答案中。
Noarchive 不允许将页面包含在 Bing Chat 中,并且不会使用任何内容来训练 Microsoft 的 AI 模型。
如果页面同时具有 Nocache 和 Noarchive,则限制较少的 Nocache 将优先。
“ robots ”标记会将指令应用于所有爬虫。 这包括 Google,它将阻止带有缓存链接的页面出现在搜索结果中。
<元名称=“机器人”内容=“noarchive”>
您可以使用更具体的“ bingbot ”或“ msnbot ”标记来避免影响其他搜索引擎。
<元名称=”bingbot”内容=”nocache”>
如何阻止谷歌的人工智能
Google 选择了 robots.txt 方法,该方法允许您指定 URL 模式来匹配您不想在 Bard 及其 Vertex API 等效项中使用的页面。 它目前不适用于搜索生成体验 (SGE)。
它们将与 Google 扩展的用户代理令牌进行匹配。 令牌的大小写并不重要。
用户代理:Google 扩展
不允许: /
如果没有专门针对 google 扩展令牌的规则块,它将与通配符令牌 (*) 匹配。
用户代理: *
不允许: /
如果您有针对 Googlebot 的特定规则块和单独的通配符块,请务必小心。 Google-extend 将匹配通配符块,而不是 Googlebot 块。
用户代理:Googlebot
允许: /
用户代理: *
不允许: /
为了更精确,您可以在规则块之前列出多个用户代理。
用户代理:Google 扩展
用户代理:Googlebot
允许: /

用户代理: *
不允许: /
如何阻止 ChatGPT
ChatGPT 还选择了 robots.txt 方法。
Chat GPT 有两种不同的用户代理令牌,ChatGPT-User 用于代表 ChatGPT 用户进行查询,GPTBot 是 OpenAI 的网络爬虫,用于构建模型。
目前,选择退出系统对两个用户代理一视同仁,因此任何不允许一个代理的 robots.txt 都将涵盖这两个代理。 这将来可能会改变,因此我们建议单独阻止它们。
用户代理:GPTBot
用户代理:ChatGPT-User
不允许: /
测试
如果您阻止整个网站,测试很简单。
要检查 Google 和 ChatGPT 是否被阻止,您需要查看您的 robots.txt 是否对您要阻止的机器人有禁止一切规则。
用户代理:Google 扩展
用户代理:GPTbot
不允许: /
如果您只想阻止某些 URL,则可能需要一组更复杂的 robots.txt 指令。 您可以考虑测试一些您预计会被阻止和未被阻止的 URL。
Tomo 是我们的免费 robots.txt 工具,可以帮助您测试 robots.txt 中是否阻止了特定网址。 您可以以 URL 列表的形式定义测试,以及每个 URL 的预期禁止状态。
可以使用 Google-Extended、GPTBot 和 ChatGPT-User 用户代理令牌对其进行配置,以显示每个 URL 被阻止,以及是否与预期的测试结果匹配。
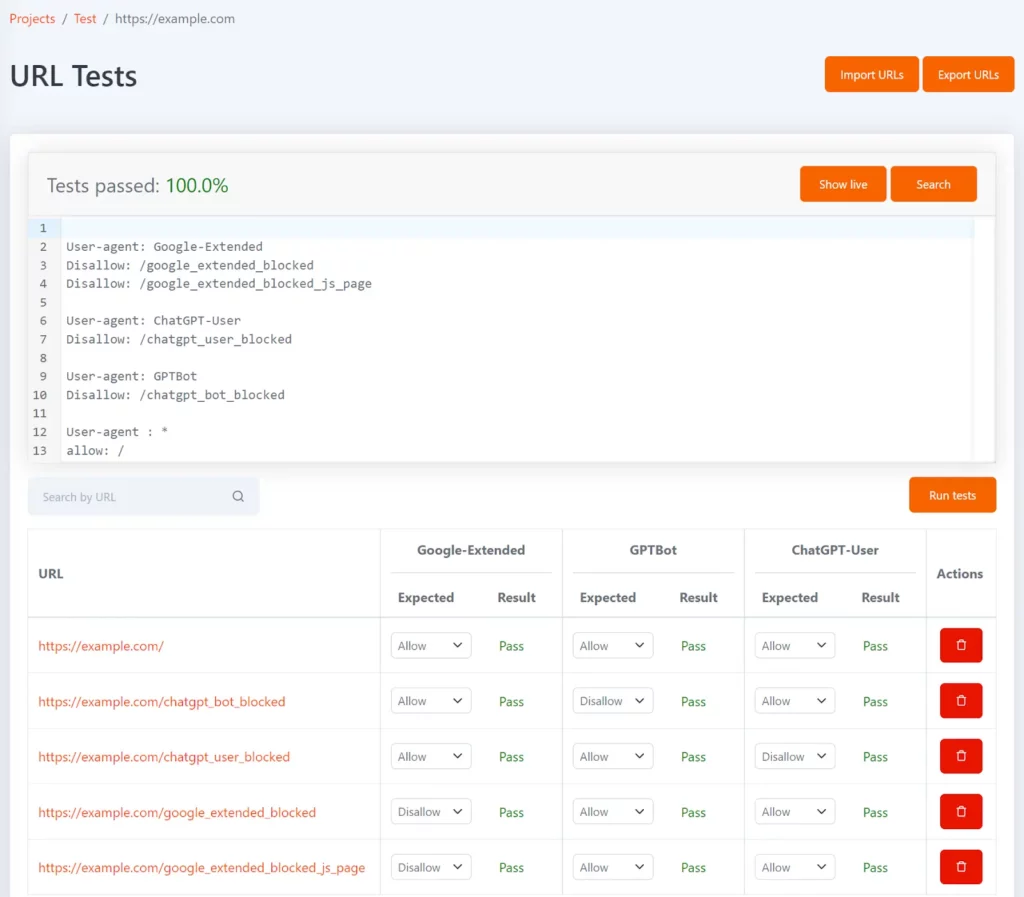
每当您的 robots.txt 文件更新时,测试都会重新运行,如果结果与预期不符,您将会收到通知。
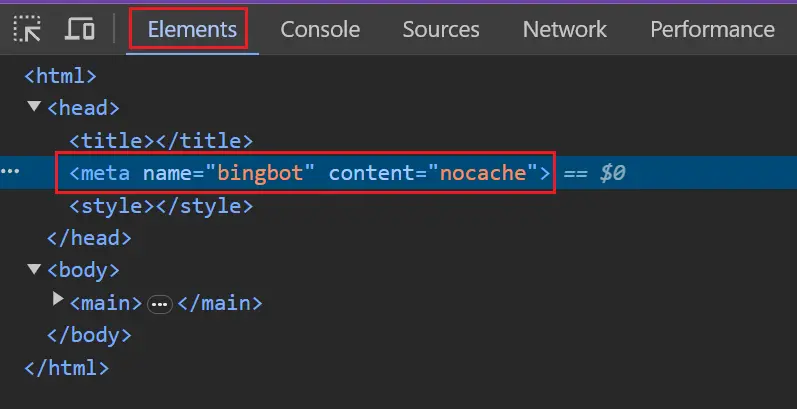
要测试 Bing 是否被阻止,您可以在浏览器中检查关键页面模板并确认它具有 robots 标记。
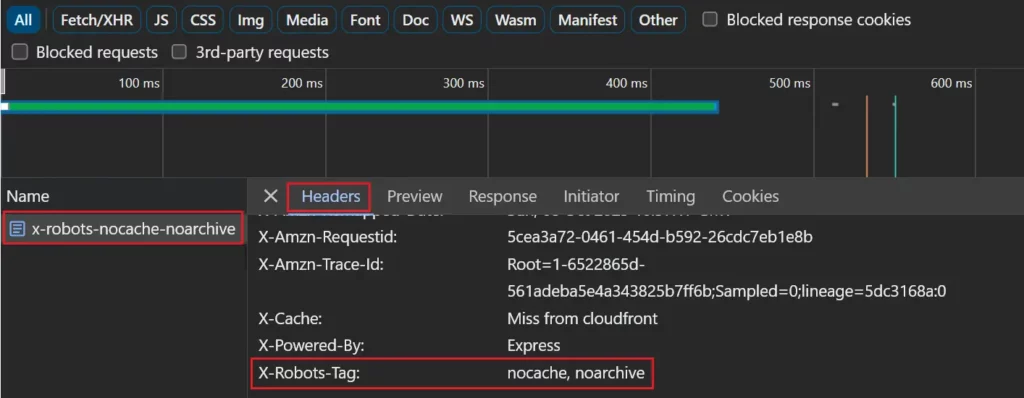
如果您使用 X-Robots-Tag 响应标头,则可以通过选择网络请求列表中的页面并查看“标头”选项卡,在网络选项卡中看到它。
如果您阻止一组特定的页面,测试将会更加复杂,但是有一些工具可以提供帮助。
Lumar 爬虫现在还将自动报告 Google 和 Bing 的 AI 被阻止的所有页面。
您需要额外的技术支持吗? 了解有关Semetrical 技术产品的更多信息或联系以获取更多信息!