
掌握网页抓取工具:提取在线数据的初学者指南
已发表: 2024-04-09什么是网页抓取工具?
网页抓取工具是一种旨在从网站中提取数据的工具。 它模拟人类导航来收集特定内容。 初学者经常利用这些爬虫来完成各种任务,包括市场研究、价格监控和机器学习项目的数据编译。
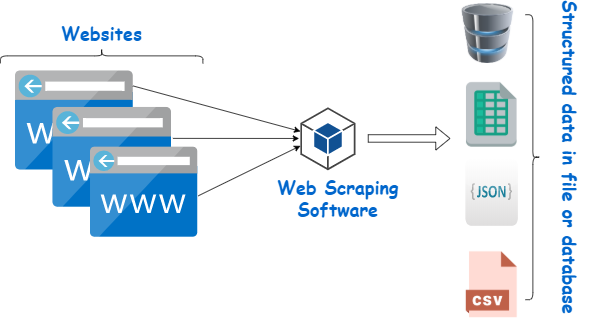
图片来源:https://www.webharvy.com/articles/what-is-web-scraping.html
- 易于使用:它们用户友好,允许具有最低技术技能的个人有效地捕获网络数据。
- 效率:爬虫可以快速收集大量数据,远远超过手动数据收集工作。
- 准确性:自动抓取降低了人为错误的风险,提高了数据准确性。
- 成本效益:无需手动输入,节省人工成本和时间。
了解网页抓取工具的功能对于任何想要利用网络数据力量的人来说至关重要。
使用 Python 创建简单的网页抓取工具
要开始用 Python 创建网页抓取工具,需要安装某些库,即向网页发出 HTTP 请求的 requests,以及用于解析 HTML 和 XML 文档的 bs4 的 BeautifulSoup。
- 采集工具:
- 库:使用请求来获取网页并使用 BeautifulSoup 来解析下载的 HTML 内容。
- 定位网页:
- 定义包含我们要抓取的数据的网页的 URL。
- 下载内容:
- 使用请求,下载网页的 HTML 代码。
- 解析 HTML:
- BeautifulSoup 会将下载的 HTML 转换为结构化格式,以便于导航。
- 提取数据:
- 识别包含我们所需信息的特定 HTML 标签(例如,<div> 标签内的产品标题)。
- 使用 BeautifulSoup 方法,提取并处理您需要的数据。
请记住定位与您要抓取的信息相关的特定 HTML 元素。
抓取网页的分步过程
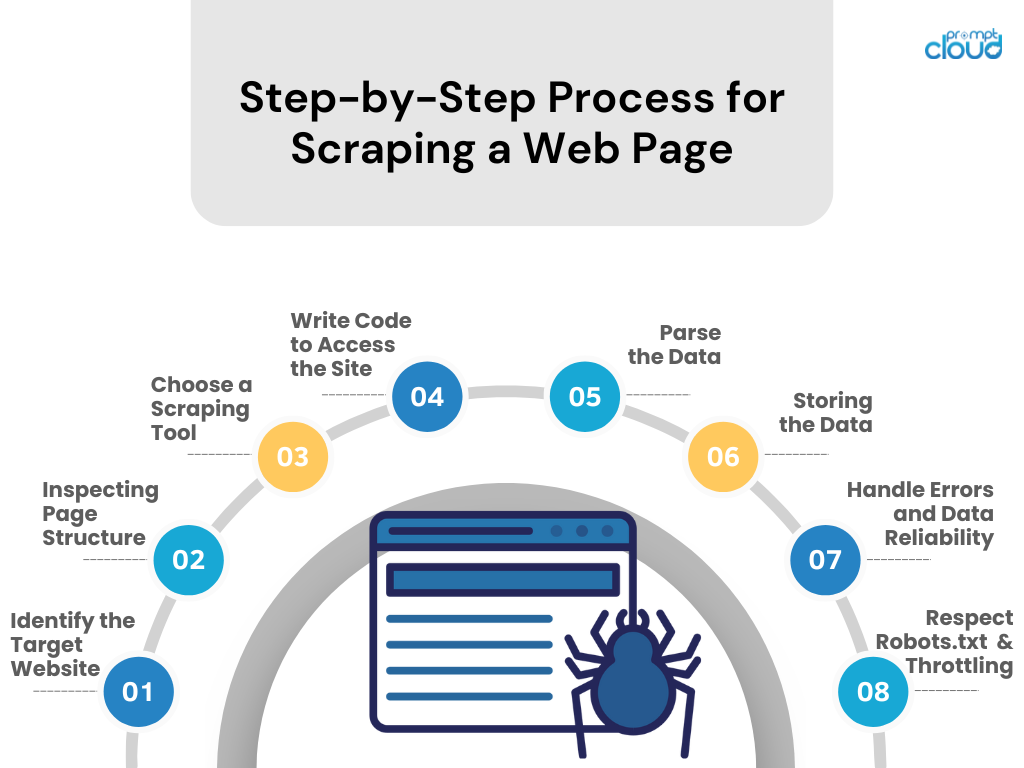
- 确定目标网站
研究您想要抓取的网站。 确保这样做是合法和道德的。 - 检查页面结构
使用浏览器的开发人员工具检查 HTML 结构、CSS 选择器和 JavaScript 驱动的内容。 - 选择一个抓取工具
选择您熟悉的编程语言的工具或库(例如,Python 的 BeautifulSoup 或 Scrapy)。 - 编写代码来访问该站点
编写一个脚本,使用 API 调用(如果可用)或 HTTP 请求从网站请求数据。 - 解析数据
通过解析HTML/CSS/JavaScript从网页中提取相关数据。 - 存储数据
以结构化格式(例如 CSV、JSON)保存抓取的数据,或直接保存到数据库。 - 处理错误和数据可靠性
实施错误处理来管理请求失败并维护数据完整性。 - 尊重 Robots.txt 和限制
遵守网站的 robots.txt 文件规则,并通过控制请求速率避免服务器不堪重负。
选择适合您需求的理想网页抓取工具
在抓取网页时,选择符合您的熟练程度和目标的工具至关重要。 初学者应该考虑:

- 易于使用:选择具有视觉辅助和清晰文档的直观工具。
- 数据要求:评估目标数据的结构和复杂性,以确定是否需要简单的扩展或强大的软件。
- 预算:权衡成本与功能; 许多有效的抓取工具都提供免费套餐。
- 定制:确保工具适合特定的抓取需求。
- 支持:访问有用的用户社区有助于排除故障和改进。
明智地选择,以获得顺利的刮擦旅程。
优化网页抓取工具的提示和技巧
- 使用 Python 中的 BeautifulSoup 或 Lxml 等高效解析库来加快 HTML 处理速度。
- 实施缓存以避免重新下载页面并减少服务器负载。
- 尊重 robots.txt 文件并使用速率限制来防止被目标网站禁止。
- 轮换用户代理和代理服务器来模仿人类行为并避免检测。
- 在非高峰时段安排抓取工具,以尽量减少对网站性能的影响。
- 如果可用,请选择 API 端点,因为它们提供结构化数据并且通常更高效。
- 通过选择性查询来避免抓取不必要的数据,从而减少所需的带宽和存储。
- 定期更新您的抓取工具以适应网站结构的变化并保持数据完整性。
处理网页抓取中的常见问题和故障排除
在使用网页抓取工具时,初学者可能会遇到几个常见问题:
- 选择器问题:确保选择器与网页的当前结构匹配。 浏览器开发人员工具等工具可以帮助识别正确的选择器。
- 动态内容:某些网页使用 JavaScript 动态加载内容。 在这种情况下,请考虑使用无头浏览器或渲染 JavaScript 的工具。
- 阻止的请求:网站可能会阻止抓取工具。 采用轮换用户代理、使用代理和尊重 robots.txt 等策略来减轻阻塞。
- 数据格式问题:提取的数据可能需要清理或格式化。 使用正则表达式和字符串操作来标准化数据。
请记住查阅文档和社区论坛以获取具体的故障排除指南。
结论
初学者现在可以通过网页抓取工具方便地从网络收集数据,使研究和分析更加高效。 在考虑法律和道德方面的同时了解正确的方法可以让用户充分利用网络抓取的潜力。 遵循这些指南可以顺利介绍网页抓取,其中充满了宝贵的见解和明智的决策。
常见问题解答:
什么是抓取页面?
网络抓取,也称为数据抓取或网络收集,包括使用模仿人类导航行为的计算机程序自动从网站提取数据。 使用网页抓取工具,可以快速对大量信息进行排序,只关注重要部分,而不是手动编译它们。
企业将网络抓取应用于检查成本、管理声誉、分析趋势和执行竞争分析等功能。 实施网络抓取项目需要验证所访问的网站是否批准所有相关 robots.txt 和 no-follow 协议的操作和遵守。
如何抓取整个页面?
要抓取整个网页,通常需要两个组件:一种在网页中定位所需数据的方法,以及一种将该数据保存在其他地方的机制。 许多编程语言都支持网络抓取,尤其是 Python 和 JavaScript。
两者都存在各种开源库,进一步简化了流程。 Python 开发人员中的一些流行选择包括 BeautifulSoup、Requests、LXML 和 Scrapy。 或者,ParseHub 和 Octoparse 等商业平台使技术水平较低的人员能够直观地构建复杂的网络抓取工作流程。 安装必要的库并了解选择 DOM 元素背后的基本概念后,首先确定目标网页中感兴趣的数据点。
利用浏览器开发人员工具检查 HTML 标签和属性,然后将这些结果转换为所选库或平台支持的相应语法。 最后,指定输出格式首选项(无论是 CSV、Excel、JSON、SQL 还是其他选项)以及保存的数据所在的目标。
如何使用谷歌抓取工具?
与普遍看法相反,尽管 Google 提供了 API 和 SDK 来促进与多个产品的无缝集成,但它本身并不直接提供公共网络抓取工具。 尽管如此,熟练的开发人员还是创建了基于 Google 核心技术的第三方解决方案,有效地扩展了本机功能之外的功能。 例如 SerpApi,它抽象了 Google Search Console 的复杂方面,并提供了一个易于使用的界面,用于关键字排名跟踪、有机流量估计和反向链接探索。
虽然在技术上与传统的网络抓取不同,但这些混合模型模糊了传统定义的界限。 其他实例展示了用于重建驱动 Google 地图平台、YouTube 数据 API v3 或 Google 购物服务的内部逻辑的逆向工程工作,产生的功能与原始对应项非常接近,尽管存在不同程度的合法性和可持续性风险。 最终,有抱负的网页抓取者应该在选择特定途径之前探索不同的选择并评估相对于特定要求的优点。
Facebook 抓取合法吗?
正如 Facebook 开发者政策中所述,未经授权的网络抓取行为明显违反了其社区标准。 用户同意不开发或运行旨在规避或超过指定 API 速率限制的应用程序、脚本或其他机制,也不得尝试对网站或服务的任何方面进行破译、反编译或逆向工程。 此外,它还强调了对数据保护和隐私的期望,在允许的环境之外共享个人身份信息之前需要明确的用户同意。
任何不遵守概述原则的行为都会引发不断升级的纪律措施,从警告开始,根据严重程度逐步推进到限制访问或完全撤销特权。 尽管为根据批准的漏洞赏金计划开展工作的安全研究人员制定了例外情况,但普遍共识主张避免未经批准的 Facebook 抓取举措,以避免不必要的复杂情况。 相反,请考虑寻求与平台认可的现行规范和惯例兼容的替代方案。