
Python 网络爬虫 – 分步教程
已发表: 2023-12-07网络爬虫是数据收集和网络抓取领域中令人着迷的工具。 它们自动化了浏览网络以收集数据的过程,这些数据可用于各种目的,例如搜索引擎索引、数据挖掘或竞争分析。 在本教程中,我们将踏上使用 Python 构建基本网络爬虫的信息之旅,Python 是一种以其简单性和处理网络数据的强大功能而闻名的语言。
Python 拥有丰富的库生态系统,为开发网络爬虫提供了一个优秀的平台。 无论您是初露头角的开发人员、数据爱好者,还是只是对网络爬虫的工作原理感到好奇,本分步指南都旨在向您介绍网络爬虫的基础知识,并让您具备创建自己的爬虫程序的技能。
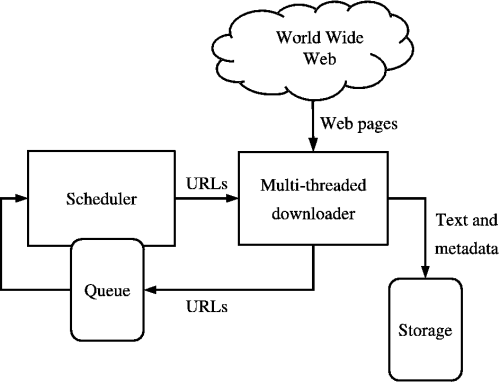
来源:https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Python 网络爬虫 – 如何构建网络爬虫
第 1 步:了解基础知识
网络爬虫,也称为蜘蛛,是一种以有条理和自动化的方式浏览万维网的程序。 对于我们的爬虫,我们将使用 Python,因为它简单且具有强大的库。
第 2 步:设置您的环境
安装 Python :确保您已安装 Python。 您可以从 python.org 下载它。
安装库:您需要 requests 来发出 HTTP 请求,并需要 bs4 中的 BeautifulSoup 来解析 HTML。 使用 pip 安装它们:
pip install 请求 pip install beautifulsoup4
第三步:编写基本爬虫
导入库:
从 bs4 导入 BeautifulSoup 导入请求
获取网页:
在这里,我们将获取网页的内容。 将“URL”替换为您要抓取的网页。
url = 'URL' 响应 = requests.get(url) 内容 = response.content
解析 HTML 内容:
汤 = BeautifulSoup(内容, 'html.parser')
提取信息:
例如,要提取所有超链接,您可以执行以下操作:
for soup.find_all('a') 中的链接: print(link.get('href'))
第四步:扩展你的爬虫
处理相对 URL :
使用 urljoin 处理相对 URL。
从 urllib.parse 导入 urljoin
避免两次抓取同一页面:
维护一组已访问的 URL 以避免冗余。
添加延迟:
尊重的爬行包括请求之间的延迟。 使用 time.sleep()。
第 5 步:尊重 Robots.txt
确保您的抓取工具尊重网站的 robots.txt 文件,该文件指示不应抓取网站的哪些部分。
第 6 步:错误处理
实施 try- except 块来处理潜在的错误,例如连接超时或拒绝访问。
第七步:更深入
您可以增强爬网程序以处理更复杂的任务,例如表单提交或 JavaScript 渲染。 对于 JavaScript 较多的网站,请考虑使用 Selenium。
第 8 步:存储数据
决定如何存储您抓取的数据。 选项包括简单的文件、数据库,甚至直接将数据发送到服务器。
第 9 步:保持道德
- 不要让服务器超载; 在您的请求中添加延迟。
- 遵守网站的服务条款。
- 未经许可,请勿抓取或存储个人数据。
被阻止是网络爬行时的一个常见挑战,特别是在处理具有检测和阻止自动访问措施的网站时。 以下是一些可帮助您在 Python 中解决此问题的策略和注意事项:

了解您被阻止的原因
频繁请求:来自同一 IP 的快速、重复请求可能会触发阻止。
非人类模式:机器人通常表现出与人类浏览模式不同的行为,例如访问页面速度过快或以可预测的顺序访问页面。
标头管理不善: HTTP 标头丢失或不正确可能会使您的请求看起来可疑。
忽略 robots.txt:不遵守网站 robots.txt 文件中的指令可能会导致被阻止。
避免被阻止的策略
尊重 robots.txt :始终检查并遵守网站的 robots.txt 文件。 这是一种道德实践,可以防止不必要的阻塞。
轮换用户代理:网站可以通过您的用户代理识别您的身份。 通过轮换它,您可以降低被标记为机器人的风险。 使用 fake_useragent 库来实现这一点。
from fake_useragent import UserAgent ua = UserAgent() headers = {'User-Agent': ua.random}
添加延迟:在请求之间实现延迟可以模仿人类行为。 使用 time.sleep() 添加随机或固定延迟。
import time time.sleep(3) # 等待3秒
IP 轮换:如果可能,请使用代理服务来轮换您的 IP 地址。 为此提供免费和付费服务。
使用会话:Python 中的 requests.Session 对象可以帮助维护一致的连接并在请求之间共享标头、cookie 等,使您的爬虫看起来更像常规的浏览器会话。
将 requests.Session() 作为会话: session.headers = {'User-Agent': ua.random} response = session.get(url)
处理 JavaScript :一些网站严重依赖 JavaScript 来加载内容。 Selenium 或 Puppeteer 等工具可以模仿真实的浏览器,包括 JavaScript 渲染。
错误处理:实施强大的错误处理,以优雅地管理和响应块或其他问题。
道德考虑
- 始终尊重网站的服务条款。 如果网站明确禁止网页抓取,最好遵守。
- 请注意您的爬网程序对网站资源的影响。 服务器过载可能会给网站所有者带来问题。
先进技术
- Web 抓取框架:考虑使用 Scrapy 等框架,它具有处理各种抓取问题的内置功能。
- 验证码解决服务:对于存在验证码挑战的网站,有一些服务可以解决验证码,尽管它们的使用会引起道德问题。
Python 中的最佳网络爬行实践
从事网络爬虫活动需要在技术效率和道德责任之间取得平衡。 使用 Python 进行网络爬虫时,遵守尊重数据及其来源网站的最佳实践非常重要。 以下是使用 Python 进行网络爬行的一些关键注意事项和最佳实践:
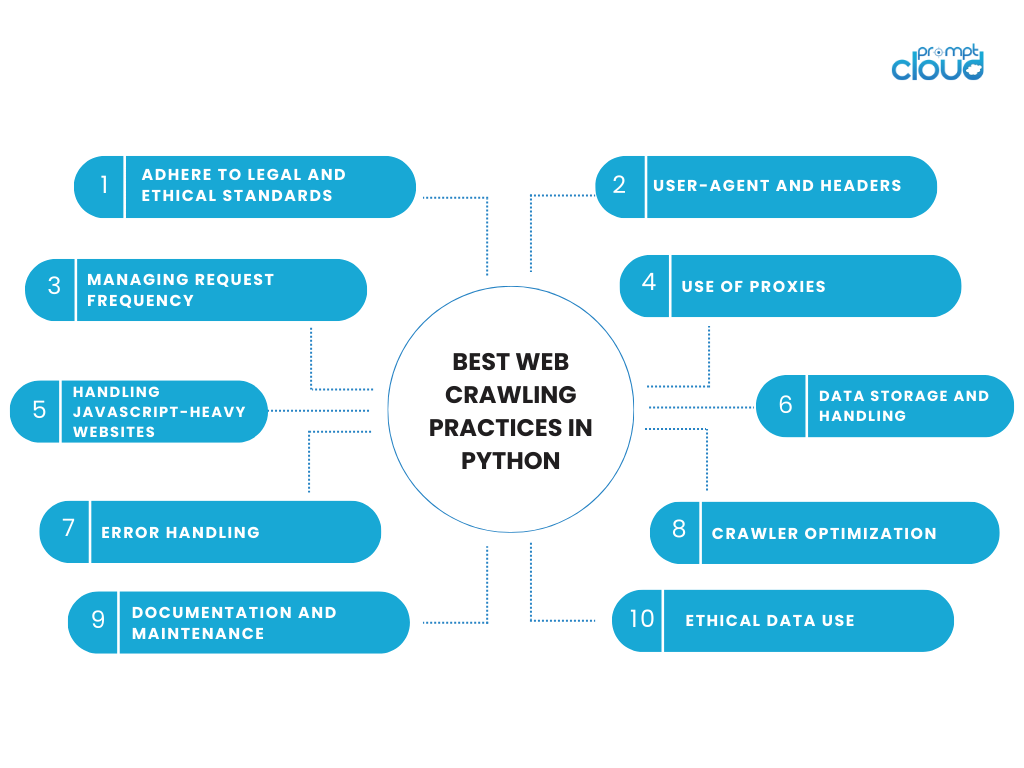
遵守法律和道德标准
- 尊重 robots.txt:始终检查网站的 robots.txt 文件。 该文件概述了网站所有者不希望被抓取的网站区域。
- 遵循服务条款:许多网站的服务条款中都包含有关网络抓取的条款。 遵守这些条款既符合道德又符合法律规定。
- 避免服务器过载:以合理的速度发出请求,以避免网站服务器负载过重。
用户代理和标头
- 识别您自己的身份:使用包含您的联系信息或爬网目的的用户代理字符串。 这种透明度可以建立信任。
- 正确使用标头:配置良好的 HTTP 标头可以降低被阻止的可能性。 它们可以包括用户代理、接受语言等信息。
管理请求频率
- 添加延迟:在请求之间实现延迟以模仿人类浏览模式。 使用 Python 的 time.sleep() 函数。
- 速率限制:了解在给定时间范围内向网站发送的请求数量。
使用代理
- IP 轮换:使用代理轮换您的 IP 地址可以帮助避免基于 IP 的封锁,但应以负责任且合乎道德的方式进行。
处理 JavaScript 密集型网站
- 动态内容:对于使用 JavaScript 动态加载内容的网站,Selenium 或 Puppeteer(与 Python 的 Pyppeteer 结合使用)等工具可以像浏览器一样呈现页面。
数据存储和处理
- 数据存储:考虑数据隐私法律法规,负责任地存储爬取的数据。
- 最大限度地减少数据提取:仅提取您需要的数据。 除非绝对必要且合法,否则避免收集个人或敏感信息。
错误处理
- 强大的错误处理:实施全面的错误处理来管理超时、服务器错误或无法加载的内容等问题。
爬虫优化
- 可扩展性:设计您的爬网程序以应对规模的增加,无论是在爬行的页面数量还是处理的数据量方面。
- 效率:优化代码以提高效率。 高效的代码可以减少系统和目标服务器上的负载。
文档和维护
- 保留文档:记录您的代码和爬取逻辑,以供将来参考和维护。
- 定期更新:保持爬行代码更新,特别是当目标网站的结构发生变化时。
符合道德的数据使用
- 道德利用:以道德方式使用您收集的数据,尊重用户隐私和数据使用规范。
综上所述
在结束我们对用 Python 构建网络爬虫的探索时,我们了解了自动化数据收集的复杂性以及随之而来的道德考虑。 这项努力不仅提高了我们的技术技能,还加深了我们对广阔的数字环境中负责任的数据处理的理解。
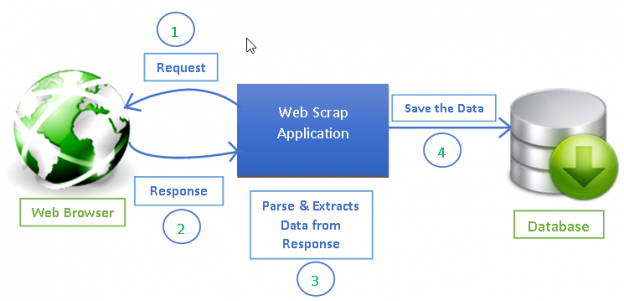
来源:https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
然而,创建和维护网络爬虫可能是一项复杂且耗时的任务,特别是对于具有特定大规模数据需求的企业而言。 这就是 PromptCloud 的自定义网页抓取服务发挥作用的地方。 如果您正在寻找适合您的 Web 数据需求的定制、高效且合乎道德的解决方案,PromptCloud 可以提供一系列服务来满足您的独特需求。 从处理复杂的网站到提供干净的结构化数据,他们确保您的网络抓取项目顺利进行并与您的业务目标保持一致。
对于可能没有时间或技术专业知识来开发和管理自己的网络爬虫的企业和个人来说,将此任务外包给 PromptCloud 等专家可能会改变游戏规则。 他们的服务不仅节省时间和资源,还能确保您获得最准确和相关的数据,同时遵守法律和道德标准。
有兴趣详细了解 PromptCloud 如何满足您的特定数据需求? 请通过 sales@promptcloud.com 与他们联系,了解更多信息,并讨论他们的定制网页抓取解决方案如何帮助推动您的业务发展。
在网络数据的动态世界中,拥有像 PromptCloud 这样可靠的合作伙伴可以增强您的业务能力,让您在数据驱动的决策中占据优势。 请记住,在数据收集和分析领域,正确的合作伙伴至关重要。
快乐的数据狩猎!