
为法学硕士选择和配置推理引擎
已发表: 2024-04-02推理机简介
人们开发了许多优化技术来减轻推理过程不同阶段发生的低效率问题。 使用普通的变压器/技术很难大规模地扩展推理。 推理引擎将优化打包到一个包中,简化了我们的推理过程。
对于非常小的一组临时测试或快速参考,我们可以使用普通变压器代码来进行推理。
推理引擎的格局正在迅速发展,因为我们有多种选择,因此针对特定用例进行测试并列出最佳选择非常重要。 下面是我们所做的一些推理引擎实验以及我们发现它适用于我们的案例的原因。
对于我们微调的 Vicuna-7B 模型,我们尝试过
- TGI
- 法学硕士
- 阿佛洛狄忒
- 最佳-Nvidia
- 功率推断
- LLAMACPP
- 翻译2
我们浏览了 github 页面及其快速入门指南来设置这些引擎,PowerInfer、LlaamaCPP、Ctranslate2 不是很灵活,并且与其他提到的引擎相比,不支持许多优化技术,例如连续批处理、分页注意力和保持低于标准的性能。
为了获得更高的吞吐量,推理引擎/服务器应该最大化内存和计算能力,并且客户端和服务器都必须以并行/异步的方式工作来服务请求,以保持服务器始终工作。 如前所述,如果没有 PagedAttention、Flash Attention、连续批处理等优化技术的帮助,它总是会导致性能不佳。
在这方面,TGI、vLLM 和 Aphrodite 是更合适的候选者,通过进行下述多次实验,我们找到了最佳配置,以从推理中获得最大性能。 默认情况下启用连续批处理和分页注意力等技术,需要在推理引擎中手动启用推测解码以进行以下测试。
推理机对比分析
TGI
要使用TGI,我们可以浏览github页面的“入门”部分,这里docker是配置和使用TGI引擎的最简单方法。
文本生成启动器参数 -> 此列表列出了我们可以在服务器端使用的不同设置。 几个重要的,
- –max-input-length :确定模型输入的最大长度,这在大多数情况下需要更改,默认值为 1024。
- –最大总令牌数:最大 总令牌,即输入+输出令牌长度。
- –speculate、–quantiz、–max-concurrent-requests -> 默认值为 128,这显然要少一些。
要启动本地微调模型,
docker run –gpus device=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text- Generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –最大输入长度3600 –最大总令牌4000 –推测2
要从集线器启动模型,
型号=”lmsys/vicuna-7b-v1.5”; 体积=$PWD/数据; 令牌=”<hf_token>”; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text- Generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –最大输入长度3600 –最大总令牌4000 –推测2
你可以请chatGPT解释一下上面的命令,以获得更详细的理解。 这里我们在 9091 端口启动推理服务器。 我们可以使用任何语言的客户端向服务器发出请求。 文本生成推理 API -> 提及用于请求的所有端点和负载参数。
例如
Payload=”<此处提示>”
curl -XPOST“0.0.0.0:9091/generate”-H“内容类型:application/json”-d“{“输入”:$payload,“参数”:{“max_new_tokens”:400,“do_sample”:false ,“best_of”:空,“repetition_penalty”:1,“return_full_text”:假,“seed”:空,“stop_sequences”:空,“温度”:0.1,“top_k”:100,“top_p”:0.3,”截断”:空,“典型_p”:空,“水印”:假,“decoder_input_details”:假}}”
很少观察,
- 延迟随着 max-token-tokens 的增加而增加,很明显,如果我们处理长文本,那么总体时间将会增加。
- 推测有帮助,但它取决于用例和输入输出分布。
- Eetq 量化对提高吞吐量有最大帮助。
- 如果您有一个多 GPU,则在每个 GPU 上运行 1 个 API 并将这些多 GPU API 放在负载均衡器后面会比 TGI 本身的分片带来更高的吞吐量。
法学硕士
要启动 vLLM 服务器,我们可以使用 OpenAI 兼容的 REST API 服务器/docker。 开始非常简单,按照 Deploying with Docker — vLLM 进行操作,如果您要使用本地模型,则附加卷并使用路径作为模型名称,
docker run –runtime nvidia –gpus device=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=主机 vllm/vllm-openai:latest –型号/型号
上面将在提到的 8000 端口上启动 vLLM 服务器,一如既往,您可以使用参数。
发出帖子请求,
“`壳
Payload=”<此处提示>”
curl -XPOST -m 1200“0.0.0.0:8000/v1/completions”-H“内容类型:application/json”-d“{“prompt”:$payload,“model”:“/model”,“max_tokens ”:400,“top_p”:0.3,“top_k”:100,“温度”:0.1}”
“`
阿佛洛狄忒
“`壳

pip 安装阿芙罗狄蒂引擎
python -m aphrodite.endpoints.openai.api_server –模型 PygmalionAI/pygmalion-2-7b
“`
或者
“`
docker run -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus device=1 –ipc 主机 alpindale/aphrodite-engine
“`
Aphrodite 提供 pip 和 docker 安装,如入门部分所述。 Docker 通常相对更容易启动和测试。 使用选项、服务器选项帮助我们如何发出请求。
- Aphrodite 和 vLLM 都使用基于 openAI 服务器的有效负载,因此您可以查看其文档。
- 我们尝试了 deepspeed-mii,因为它处于从旧代码库到新代码库的过渡状态(当我们尝试时),它看起来并不可靠且易于使用。
- Optimum-NVIDIA 不支持其他主要优化并导致性能次优,参考链接。
- 添加了一个要点,即我们用来执行临时并行请求的代码。
指标和测量
我们想尝试并发现:
- 最佳编号客户端/推理引擎服务器的线程数。
- 吞吐量如何随着内存的增加而增长
- 张量核心的吞吐量如何增长。
- 线程与客户端并行请求的影响。
观察利用率的非常基本的方法是通过 linux utils nvidia-smi、nvtop 进行观察,这将告诉我们占用的内存、计算利用率、数据传输速率等。
另一种方法是使用 GPU 和 nsys 来分析进程。
| 序列号 | 图形处理器 | 显存 | 推理机 | 线程数 | 时间(秒) | 推测 |
| 1 | A6000 | 48 /48GB | TGI | 24 | 第664章 | – |
| 2 | A6000 | 48 /48GB | TGI | 64 | 第561章 | – |
| 3 | A6000 | 48 /48GB | TGI | 128 | 第554章 | – |
| 4 | A6000 | 48 /48GB | TGI | 256 | 第568章 | – |
根据以上实验,128/ 256 线程优于较低线程数,超过 256 开销开始导致吞吐量降低。 这个发现是依赖CPU和GPU的,需要自己实验。 | ||||||
| 5 | A6000 | 48 /48GB | TGI | 128 | 第596章 | 2 |
| 6 | A6000 | 48 /48GB | TGI | 128 | 第945章 | 8 |
较高的推测值会导致我们的微调模型被更多拒绝,从而降低吞吐量。 1 / 2 因为推测值很好,这取决于模型,并且不能保证在不同用例中都能正常工作。 但结论是推测解码提高了吞吐量。 | ||||||
| 7 | 3090 | 24/24GB | TGI | 128 | 第741章 | 2 |
| 7 | 4090 | 24/24GB | TGI | 128 | 第481章 | 2 |
尽管与 A6000 相比,4090 的 vRAM 较少,但由于张量核心数量和内存带宽速度更高,它的性能更胜一筹。 | ||||||
| 8 | A6000 | 24/48GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2 个 24/48GB | TGI | 128 | 1205 | 2 |
设置和配置 TGI 以实现高吞吐量
使用选择的脚本语言(例如 python/ruby)设置异步请求,并使用我们发现的相同文件进行配置:
- 所花费的时间增加了序列生成的最大输出长度。
- 客户端和服务器上的 128/ 256 线程优于 24、64、512。当使用较低线程时,计算利用率不足,超过 128 等阈值时,开销会变得更高,因此吞吐量会降低。
- 使用“GNU 并行”而不是 Go、Python/Ruby 等语言中的线程从异步请求跳转到并行请求时,性能提高了 6%。
- 4090 的吞吐量比 A6000 高 12%。 尽管与 A6000 相比,4090 的 vRAM 较少,但由于张量核心数量和内存带宽速度更高,它的性能更胜一筹。
- 由于 A6000 具有 48GB vRAM,为了断定额外的 RAM 是否有助于提高吞吐量,我们在表的实验 8 中尝试使用部分 GPU 内存,我们发现额外的 RAM 有助于提高,但不是线性的。 此外,当尝试拆分(即在同一 GPU 上托管 2 个 API,每个 API 使用一半内存)时,它的行为就像 2 个顺序 API 运行,而不是并行接受请求。
观察和指标
下面是一些实验的图表以及完成固定输入集所需的时间,所用时间越短越好。
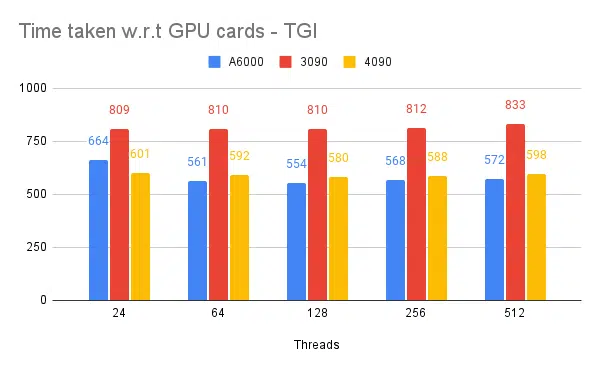
- 提到的是客户端线程。 在启动推理引擎时我们需要提到服务器端。
推测测试:

多个推理引擎测试:
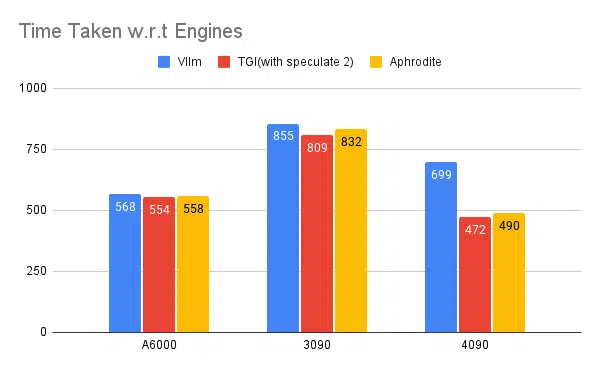
使用 vLLM 和 Aphrodite 等其他引擎进行相同类型的实验,我们观察到类似的结果,截至撰写本文时,vLLM 和 Aphrodite 尚不支持推测解码,这使我们选择 TGI,因为它提供的吞吐量高于其他引擎推测性解码。
此外,您可以配置 GPU 分析器来增强可观察性,帮助识别资源使用过多的区域并优化性能。 进一步阅读:Nvidia Nsight 开发者工具 — Max Katz
结论
我们看到推理生成的前景在不断发展,提高 LLM 的吞吐量需要充分了解 GPU、性能指标、优化技术以及与文本生成任务相关的挑战。 这有助于为工作选择正确的工具。 通过了解 GPU 内部结构以及它们如何对应 LLM 推理,例如利用张量核心和最大化内存带宽,开发人员可以选择经济高效的 GPU 并有效优化性能。
不同的 GPU 卡提供不同的功能,了解差异对于为特定任务选择最合适的硬件至关重要。 连续批处理、分页注意力、内核融合和闪存注意力等技术为克服出现的挑战和提高效率提供了有前景的解决方案。 根据我们获得的实验和结果,TGI 看起来是我们用例的最佳选择。
阅读与大语言模型相关的其他文章:
了解 LLM 推理优化的 GPU 架构
提高 LLM 吞吐量的先进技术