
构建网络爬虫的分步指南
已发表: 2023-12-05在错综复杂的互联网中,信息分散在无数的网站上,网络爬虫成为无名英雄,努力组织、索引这些丰富的数据并使之可供访问。 本文开始对网络爬虫进行探索,阐明其基本工作原理,区分网络爬虫和网络抓取,并提供实用的见解,例如制作简单的基于 Python 的网络爬虫的分步指南。 随着我们深入研究,我们将揭示 Scrapy 等高级工具的功能,并了解 PromptCloud 如何将网络爬行提升到工业规模。
什么是网络爬虫
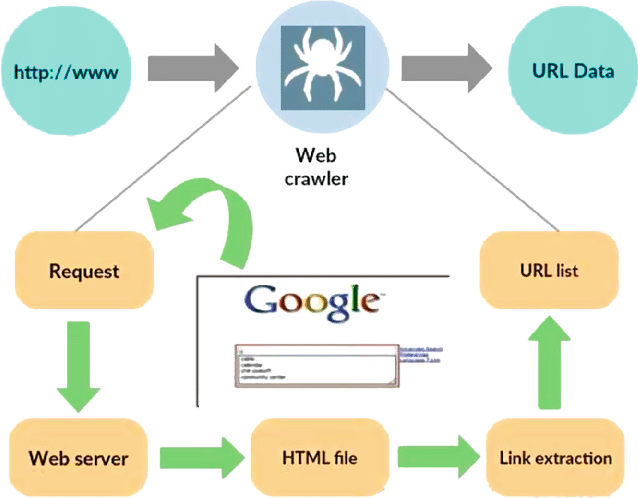
资料来源: https ://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
网络爬虫,也称为蜘蛛或机器人,是一种专门的程序,旨在系统地、自主地导航广阔的万维网。 其主要功能是为了各种目的遍历网站、收集数据和索引信息,例如搜索引擎优化、内容索引或数据提取。
网络爬虫的核心是模仿人类用户的行为,但速度更快、效率更高。 它从指定的起点(通常称为种子 URL)开始其旅程,然后沿着超链接从一个网页到另一个网页。 跟踪链接的过程是递归的,允许爬虫探索互联网的很大一部分。
当爬虫访问网页时,它会系统地提取并存储相关数据,其中可以包括文本、图像、元数据等。 然后对提取的数据进行组织和索引,使搜索引擎在查询时更容易检索并向用户呈现相关信息。
网络爬虫在 Google、Bing 和 Yahoo 等搜索引擎的功能中发挥着关键作用。 通过持续、系统地抓取网络,他们确保搜索引擎索引是最新的,为用户提供准确且相关的搜索结果。 此外,网络爬虫还用于各种其他应用,包括内容聚合、网站监控和数据挖掘。
网络爬虫的有效性取决于其导航不同网站结构、处理动态内容以及遵守网站通过 robots.txt 文件设置的规则的能力,该文件概述了可以爬网的网站的哪些部分。 了解网络爬虫的运作方式对于理解它们在使庞大的信息网络可访问和组织起来方面的重要性至关重要。
网络爬虫如何工作
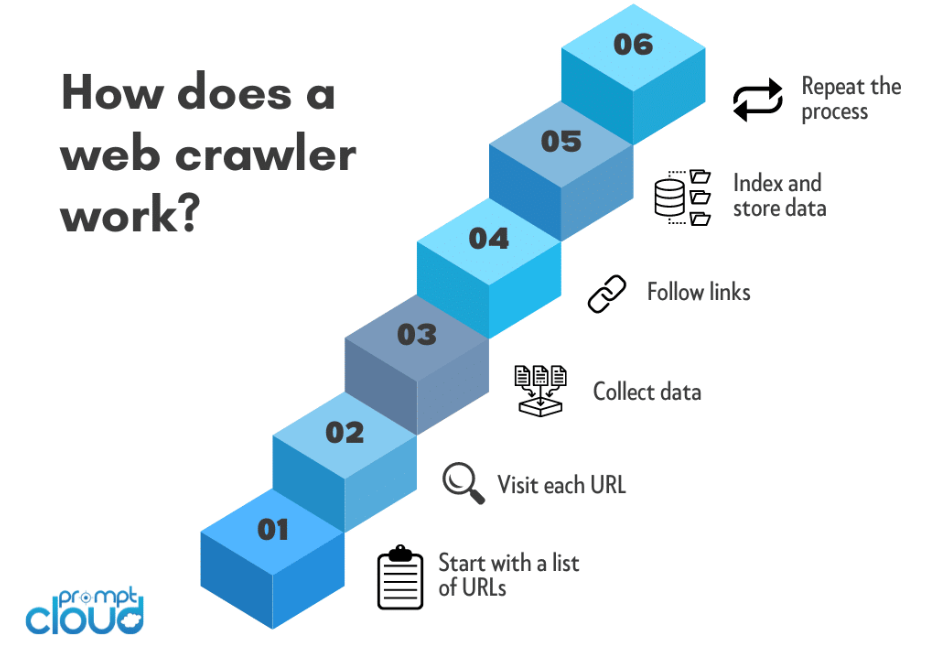
网络爬虫,也称为蜘蛛或机器人,通过导航万维网从网站收集信息的系统过程进行操作。 以下是网络爬虫如何工作的概述:
种子网址选择:
网络爬行过程通常从种子 URL 开始。 这是爬虫开始其旅程的初始网页或网站。
HTTP 请求:
爬虫向种子 URL 发送 HTTP 请求以检索网页的 HTML 内容。 此请求类似于网络浏览器访问网站时发出的请求。
HTML 解析:
一旦获取 HTML 内容,爬虫就会解析它以提取相关信息。 这涉及将 HTML 代码分解为爬虫可以导航和分析的结构化格式。
网址提取:
爬虫识别并提取 HTML 内容中存在的超链接 (URL)。 这些 URL 代表爬虫随后将访问的其他页面的链接。
队列和调度器:
提取的 URL 将添加到队列或调度程序中。 队列确保爬网程序按特定顺序访问 URL,通常首先优先考虑新的或未访问的 URL。
递归:
爬虫沿着队列中的链接,重复发送 HTTP 请求、解析 HTML 内容和提取新 URL 的过程。 这种递归过程允许爬虫浏览多层网页。
数据提取:
当爬虫遍历网络时,它会从每个访问的页面中提取相关数据。 提取的数据类型取决于爬虫的目的,可能包括文本、图像、元数据或其他特定内容。
内容索引:
对收集到的数据进行组织和索引。 索引涉及创建一个结构化数据库,以便在用户提交查询时可以轻松搜索、检索和呈现信息。
尊重机器人.txt:
网络爬虫通常遵守网站的 robots.txt 文件中指定的规则。 此文件提供了有关可以对网站的哪些区域进行爬网以及应该排除哪些区域的指南。
抓取延迟和礼貌:
为了避免服务器超载并造成中断,爬虫通常会采用爬行延迟和礼貌机制。 这些措施确保爬虫以尊重且不造成干扰的方式与网站进行交互。
网络爬虫系统地浏览网络、跟踪链接、提取数据并构建有组织的索引。 此过程使搜索引擎能够根据用户的查询向用户提供准确且相关的结果,使网络爬虫成为现代互联网生态系统的基本组成部分。
网络爬行与网络抓取

来源:https://research.aimultiple.com/web-crawling-vs-web-scraping/

虽然网络爬行和网络抓取经常互换使用,但它们具有不同的目的。 网络爬行涉及系统地浏览网络以索引和收集信息,而网络抓取则侧重于从网页中提取特定数据。 本质上,网络爬行是关于探索和绘制网络,而网络抓取是关于收集目标信息。
构建网络爬虫
用Python构建一个简单的网络爬虫涉及几个步骤,从设置开发环境到编写爬虫逻辑。 下面是一个详细的指南,可帮助您使用 Python 创建基本的网络爬虫,利用 requests 库发出 HTTP 请求,并使用 BeautifulSoup 进行 HTML 解析。
第 1 步:设置环境
确保您的系统上安装了 Python。 您可以从 python.org 下载它。 此外,您还需要安装所需的库:
pip install requests beautifulsoup4
第2步:导入库
创建一个新的 Python 文件(例如 simple_crawler.py)并导入必要的库:
import requests from bs4 import BeautifulSoup
第三步:定义爬虫函数
创建一个函数,将 URL 作为输入,发送 HTTP 请求,并从 HTML 内容中提取相关信息:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
第四步:测试爬虫
提供示例 URL 并调用 simple_crawler 函数来测试爬虫:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
第 5 步:运行爬网程序
在终端或命令提示符中执行 Python 脚本:
python simple_crawler.py
爬虫将获取所提供的 URL 的 HTML 内容,对其进行解析并打印标题。 您可以通过添加更多功能来扩展爬网程序以提取不同类型的数据。
使用 Scrapy 进行网页爬行
使用 Scrapy 进行网页抓取打开了通向强大而灵活的框架的大门,该框架专为高效且可扩展的网页抓取而设计。 Scrapy 简化了构建网络爬虫的复杂性,为构建可以导航网站、提取数据并以系统方式存储的蜘蛛提供了一个结构化环境。 以下是使用 Scrapy 进行网络爬行的详细介绍:
安装:
在开始之前,请确保您已安装 Scrapy。 您可以使用以下方式安装它:
pip install scrapy
创建一个 Scrapy 项目:
启动一个 Scrapy 项目:
打开终端并导航到要在其中创建 Scrapy 项目的目录。 运行以下命令:
scrapy startproject your_project_name
这将创建一个带有必要文件的基本项目结构。
定义蜘蛛:
在项目目录中,导航到 Spiders 文件夹并为您的 Spider 创建一个 Python 文件。 通过子类化 scrapy.Spider 并提供名称、允许的域和起始 URL 等基本详细信息来定义蜘蛛类。
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
提取数据:
使用选择器:
Scrapy 利用强大的选择器从 HTML 中提取数据。 您可以在蜘蛛的解析方法中定义选择器来捕获特定元素。
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
此示例提取 <title> 标签的文本内容。
以下链接:
Scrapy 简化了跟踪链接的过程。 使用follow方法可以跳转到其他页面。
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
运行蜘蛛:
使用项目目录中的以下命令执行蜘蛛:
scrapy crawl your_spider
Scrapy 将启动蜘蛛,跟踪链接,并执行 parse 方法中定义的解析逻辑。
使用 Scrapy 进行网络抓取提供了一个强大且可扩展的框架,用于处理复杂的抓取任务。 其模块化架构和内置功能使其成为从事复杂 Web 数据提取项目的开发人员的首选。
大规模网络爬行
大规模网络爬行带来了独特的挑战,尤其是在处理分布在众多网站上的大量数据时。 PromptCloud 是一个专门的平台,旨在大规模简化和优化网络爬行过程。 以下是 PromptCloud 如何协助处理大规模网络爬行计划:
- 可扩展性
- 数据提取和丰富
- 数据质量和准确性
- 基础设施管理
- 使用方便
- 合规与道德
- 实时监控和报告
- 支持与维护
PromptCloud 是一个强大的解决方案,适合寻求大规模网络爬行的组织和个人。 通过解决与大规模数据提取相关的关键挑战,该平台提高了网络爬行计划的效率、可靠性和可管理性。
总之
网络爬虫是广阔的数字领域中的无名英雄,勤奋地在网络中导航以索引、收集和组织信息。 随着网络爬虫项目规模的扩大,PromptCloud 作为解决方案介入,提供可扩展性、数据丰富性和道德合规性,以简化大规模计划。 请通过sales@promptcloud.com与我们联系