
了解 LLM 推理优化的 GPU 架构
已发表: 2024-04-02LLM 简介和 GPU 优化的重要性
在当今自然语言处理 (NLP) 不断进步的时代,大型语言模型 (LLM) 已成为执行各种任务(从文本生成到问答和摘要)的强大工具。 这些不仅仅是下一个可能的代币生成器。 然而,这些模型不断增长的复杂性和规模对计算效率和性能提出了重大挑战。
在这篇博客中,我们深入研究了 GPU 架构的复杂性,探索不同的组件如何促进 LLM 推理。 我们将讨论关键性能指标,例如内存带宽和张量核心利用率,并阐明各种 GPU 卡之间的差异,使您能够在为大型语言模型任务选择硬件时做出明智的决策。
在快速发展的环境中,NLP 任务需要不断增加的计算资源,优化 LLM 推理吞吐量至关重要。 加入我们,踏上这段旅程,通过 GPU 优化技术释放法学硕士的全部潜力,并深入研究使我们能够有效提高性能的各种工具。
法学硕士的 GPU 架构要点 – 了解您的 GPU 内部结构
凭借执行高效并行计算的性质,GPU 成为运行所有深度学习任务的首选设备,因此了解 GPU 架构的高级概述对于了解推理阶段出现的潜在瓶颈非常重要。 Nvidia卡因CUDA(计算统一设备架构)而受到青睐,CUDA是NVIDIA开发的专有并行计算平台和API,它允许开发人员用C编程语言指定线程级并行性,提供对GPU虚拟指令集和并行性的直接访问计算元素。
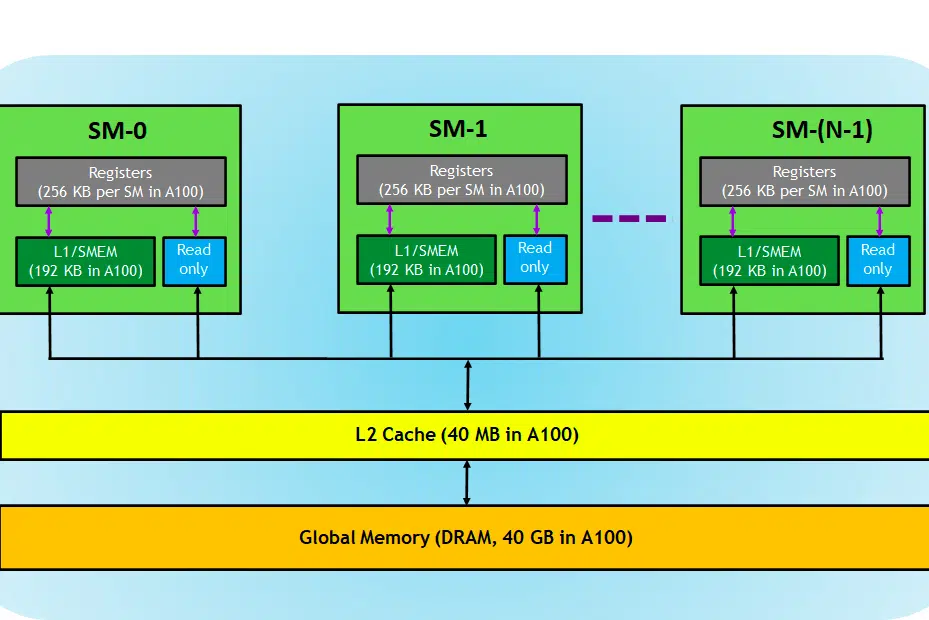
在上下文中,我们使用 NVIDIA 卡进行解释,因为如前所述,它广泛用于深度学习任务,并且很少有其他术语(例如张量核心)适用于此。
让我们看一下 GPU 卡,在图像中,我们可以看到 GPU 设备的三个主要部分和(一个主要的隐藏部分)
- SM(流式多处理器)
- 二级缓存
- 内存带宽
- 全局内存(DRAM)
就像 CPU 和 RAM 一起发挥作用一样,RAM 是数据驻留的地方(即内存),CPU 是处理任务的地方(即进程)。 在GPU中,高带宽全局存储器(DRAM)保存加载到存储器中的模型(例如LLAMA 7B)权重,并且在需要时,这些权重被传输到处理单元(即SM处理器)进行计算。
流式多处理器
流式多处理器或 SM 是称为 CUDA 核心(NVIDIA 专有并行计算平台)的较小执行单元的集合,以及负责指令获取、解码、调度和分派的附加功能单元。 每个 SM 独立运行并包含自己的寄存器文件、共享内存、L1 缓存和纹理单元。 SM 高度并行化,允许它们同时处理数千个线程,这对于在 GPU 计算任务中实现高吞吐量至关重要。 处理器的性能通常以 FLOPS 来衡量,即 FLOPS。 它每秒可以执行的浮动操作。
深度学习任务主要由张量运算组成,即矩阵-矩阵乘法,nvidia 在新一代 GPU 中引入了张量核心,这些核心专门设计用于以高效的方式执行这些张量运算。 如前所述,张量核心在深度学习任务中非常有用,我们必须检查张量核心以确定 GPU 执行 LLM 训练/推理的效率,而不是 CUDA 核心。
二级缓存
L2 缓存是一种在 SM 之间共享的高带宽内存,旨在优化系统内的内存访问和数据传输效率。 与 DRAM 相比,它是一种更小、更快的内存类型,更靠近处理单元(例如流式多处理器)。 它减少了每个内存请求访问速度较慢的 DRAM 的需要,从而有助于提高整体内存访问效率。
内存带宽
因此,性能取决于我们将权重从内存传输到处理器的速度以及处理器处理给定计算的效率和速度。
当计算能力高于/快于内存到SM之间的数据传输速率时,SM将缺乏数据来处理,因此计算未得到充分利用,这种内存带宽低于消耗率的情况被称为内存限制阶段。 值得注意的是,这是推理过程中普遍存在的瓶颈。
相反,如果计算花费更多时间进行处理并且更多数据排队等待计算,则此状态是计算限制阶段。
为了充分利用 GPU,我们必须处于计算密集状态,同时尽可能高效地进行计算。
内存
DRAM 充当 GPU 中的主存储器,提供大量内存来存储计算所需的数据和指令。 它通常按层次结构组织,具有多个存储体和通道以实现高速访问。
对于推理任务,GPU 的 DRAM 决定了我们可以加载多大的模型,计算 FLOPS 和带宽决定了我们可以获得的吞吐量。
比较用于 LLM 任务的 GPU 卡
要获取有关张量核心数量、带宽速度的信息,可以查看 GPU 制造商发布的白皮书。 这是一个例子,

| RTX A6000 | RTX 4090 | RTX 3090 | |
| 内存大小 | 48GB | 24GB | 24GB |
| 内存类型 | GDDR6 | GDDR6X | |
| 带宽 | 768.0GB/秒 | 1008 GB/秒 | 936.2GB/秒 |
| CUDA 核心/GPU | 10752 | 16384 | 10496 |
| 张量核心 | 第336章 | 第512章 | 328 |
| 一级缓存 | 128 KB(每个 SM) | 128 KB(每个 SM) | 128 KB(每个 SM) |
| FP16 非张量 | 38.71 万亿次浮点运算 (1:1) | 82.6 | 35.58 万亿次浮点运算 (1:1) |
| FP32 非张量 | 38.71 万亿次浮点运算 | 82.6 | 35.58 万亿次浮点运算 |
| FP64 非张量 | 1,210 GFLOPS (1:32) | 556.0 GFLOPS (1:64) | |
| 具有 FP16 累加的峰值 FP16 张量 TFLOPS | 154.8/309.6 | 330.3/660.6 | 142/284 |
| 具有 FP32 累加的峰值 FP16 张量 TFLOPS | 154.8/309.6 | 165.2/330.4 | 71/142 |
| 带有 FP32 的峰值 BF16 张量 TFLOPS | 154.8/309.6 | 165.2/330.4 | 71/142 |
| 峰值 TF32 张量 TFLOPS | 77.4/154.8 | 82.6/165.2 | 35.6/71 |
| 峰值 INT8 张量 TOPS | 309.7/619.4 | 660.6/1321.2 | 284/568 |
| 峰值 INT4 张量 TOPS | 619.3/1238.6 | 1321.2/2642.4 | 568/1136 |
| 二级缓存 | 6MB | 72MB | 6MB |
| 内存总线 | 384位 | 384位 | 384位 |
| TMU | 第336章 | 第512章 | 328 |
| ROP | 112 | 176 | 112 |
| SM计数 | 84 | 128 | 82 |
| RT 核心 | 84 | 128 | 82 |
在这里我们可以看到 FLOPS 是针对张量运算专门提到的,这些数据将帮助我们比较不同的 GPU 卡并筛选出适合我们用例的 GPU 卡。 从表中可以看出,虽然A6000的内存是4090的两倍,但4090的张量触发器和内存带宽在数量上更胜一筹,因此对于大型语言模型的推理能力更强。
进一步阅读:100 秒了解 Nvidia CUDA
结论
在快速发展的 NLP 领域,推理任务的大型语言模型(LLM)优化已成为一个关键的关注领域。 正如我们所探索的,GPU 架构在这些任务中实现高性能和高效率方面发挥着关键作用。 了解 GPU 的内部组件,例如流式多处理器 (SM)、L2 缓存、内存带宽和 DRAM,对于识别 LLM 推理过程中的潜在瓶颈至关重要。
不同 NVIDIA GPU 卡(RTX A6000、RTX 4090 和 RTX 3090)之间的比较揭示了内存大小、带宽以及 CUDA 和 Tensor Core 数量等因素的显着差异。 这些区别对于就哪种 GPU 最适合特定的 LLM 任务做出明智的决定至关重要。 例如,虽然 RTX A6000 提供更大的内存,但 RTX 4090 在张量 FLOPS 和内存带宽方面表现出色,使其成为要求苛刻的 LLM 推理任务的更有效选择。
优化 LLM 推理需要一种平衡的方法,既要考虑 GPU 的计算能力,又要考虑当前 LLM 任务的具体要求。 选择合适的 GPU 需要了解内存容量、处理能力和带宽之间的权衡,以确保 GPU 能够有效处理模型的权重并执行计算,而不会成为瓶颈。 随着 NLP 领域的不断发展,对于那些希望突破大型语言模型的极限的人来说,了解最新的 GPU 技术及其功能至关重要。
使用的术语
- 吞吐量:
在推理的情况下,吞吐量是在给定时间段内处理多少请求/提示的度量。 吞吐量通常通过两种方式来衡量:
- 每秒请求数 (RPS) :
- RPS 衡量模型在一秒钟内可以处理的推理请求数量。 推理请求通常涉及基于输入数据生成响应或预测。
- 对于 LLM 生成,RPS 表示模型响应传入提示或查询的速度。 RPS 值越高,表明实时或近实时应用程序的响应能力和可扩展性越好。
- 实现高 RPS 值通常需要高效的部署策略,例如将多个请求一起批处理以分摊开销并最大限度地利用计算资源。
- 每秒令牌数 (TPS) :
- TPS 衡量模型在文本生成过程中处理和生成标记(单词或子词)的速度。
- 在LLM生成的背景下,TPS反映了模型在生成文本方面的吞吐量。 它表明模型能够多快地产生连贯且有意义的响应。
- TPS 值越高意味着文本生成速度越快,从而允许模型在给定时间内处理更多输入数据并生成更长的响应。
- 实现高 TPS 值通常涉及优化模型架构、并行计算以及利用 GPU 等硬件加速器来加快令牌生成。
- 潜伏:
LLM 中的延迟是指推理期间输入和输出之间的时间延迟。 最大限度地减少延迟对于增强用户体验并在利用法学硕士的应用程序中实现实时交互至关重要。 根据我们需要提供的服务,在吞吐量和延迟之间取得平衡至关重要。 对于实时交互聊天机器人/副驾驶等情况需要低延迟,但对于内部数据重新处理等批量数据处理情况则不需要。
在此处阅读有关提高 LLM 吞吐量的高级技术的更多信息。