
如何使用 R 和 Python 将数据上传到 BigQuery
已发表: 2023-06-06网络分析世界继续朝着 7 月 1 日这个决定性的日期前进,届时 Universal Analytics 将停止处理数据并被 Google Analytics 4 (GA4) 取代。 其中一项关键变化是,在 GA4 中,您最多只能在平台中保留数据 14 个月。 这是 UA 的重大变化,但作为交换,您可以免费将 GA4 数据推送到 BigQuery 中,但有限制。
BigQuery 是超越 GA4 的数据存储的极其有用的资源。 随着它在几个月内变得比以往任何时候都更加重要,现在是开始使用它来满足您所有数据存储需求的最佳时机。 通常,最好在上传之前以某种方式处理数据。 为此,我们建议使用用 R 或 Python 编写的脚本,尤其是在需要重复执行此类操作的情况下。 您还可以直接从这些脚本将数据上传到 BigQuery,而这正是本博客将指导您完成的内容。
从 R 上传到 BigQuery
R 是一种非常强大的数据科学语言,也是最容易用于将数据上传到 BigQuery 的语言。 第一步是导入所有必要的库。 对于本教程,我们将需要以下库:
library(googleAuthR)
library(bigQueryR)
如果您以前没有使用过这些库,请在控制台中运行install.packages(<PACKAGE NAME>)来安装它们。
接下来,我们必须解决使用 API 时通常最棘手、最令人沮丧的部分——授权。 幸运的是,有了 R,这就相对简单了。 您将需要一个包含授权凭据的 JSON 文件。 这可以在 Google Cloud Console 中找到,BigQuery 位于同一位置。 首先,导航到 Google Cloud Console,然后单击“API 和服务”。
接下来,单击边栏中的“凭据”。
在 Credentials 页面上,您可以查看现有的 API 密钥、OAuth 2.0 客户端 ID 和服务帐户。 为此,您需要一个 OAuth 2.0 客户端 ID,因此请点击您 ID 相关行末尾的下载按钮,或者通过单击页面顶部的“创建凭据”来创建一个新 ID。 确保您的 ID 有权查看和编辑相关的 BigQuery 项目——为此,打开侧边栏,将鼠标悬停在“IAM 和管理”上,然后点击“IAM”。 在此页面上,您可以使用页面顶部的“授予访问权限”按钮授予您的服务帐户对相关项目的访问权限。
获取并保存 JSON 文件后,您可以使用 gar_set_client() 函数将路径传递给它以设置您的凭据。 完整的授权代码如下:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
显然,您需要将 gar_set_client() 函数中的路径替换为您自己的 JSON 文件的路径,并将用于访问 BigQuery 的电子邮件地址插入到 bqr_auth() 函数中。
授权设置完成后,我们需要一些数据上传到 BigQuery。 我们需要将这些数据放入数据框中。 出于本文的目的,我将创建一些包含多个位置和销售数量的虚构数据,但您很可能会从 .csv 文件或电子表格中读取真实数据。 要从 .csv 文件中读取数据,您可以简单地使用 read.csv() 函数,将文件路径作为参数传递:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
或者,如果您将数据存储在电子表格中,则您的方法将根据电子表格所在的位置而有所不同。 如果您的电子表格存储在 Google 表格中,您可以使用 googlesheets4 库将其数据读入 R:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
和以前一样,如果您以前没有使用过这个包,则必须在运行代码之前在控制台中运行 install.packages(“googlesheets4”)。
如果您的电子表格在 Excel 中,您将需要使用 readxl 库,它是 tidyverse 库的一部分——我推荐使用它。 它包含大量函数,使 R 中的数据操作变得更加容易:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
再一次,确保运行 install.package(“tidyverse”) 如果您之前没有运行过!
最后一步是将数据上传到 BigQuery。 为此,您需要在 BigQuery 中有一个位置来上传它。 您的表将位于一个数据集中,该数据集将位于一个项目中,并且您需要采用以下格式的所有这三个名称:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
就我而言,这意味着我的代码如下:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
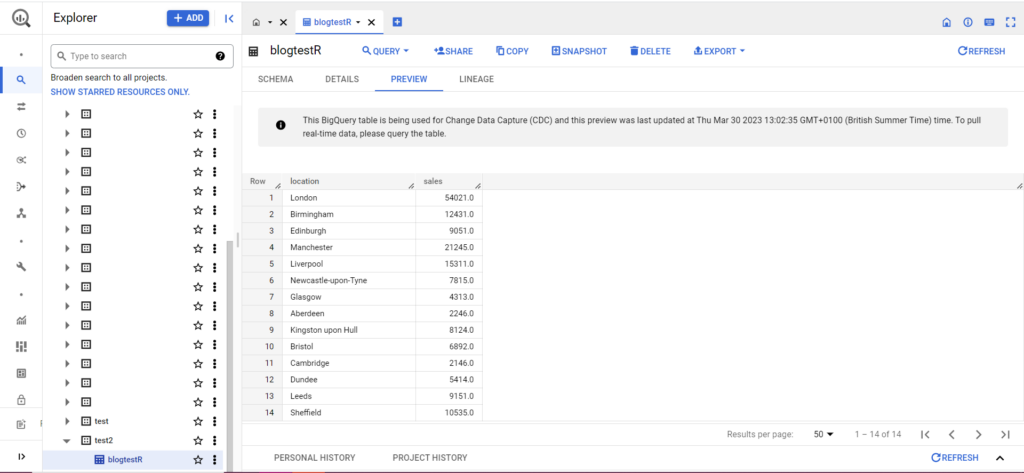
如果您的表还不存在,请不要担心,代码会为您创建它。 不要忘记将您的项目、数据集和表的名称插入到上面的代码中(在引号内),并确保您上传的是正确的数据框! 完成后,您应该会在 BigQuery 中看到您的数据,如下所示:
作为最后一步,假设您有其他数据要添加到 BigQuery。 例如,在我上面的数据中,假设我忘记包含来自大陆的几个位置,我想上传到 BigQuery,但我不想覆盖现有数据。 为此,bqr_upload_data 有一个名为 writeDisposition 的参数。 writeDisposition 有两个设置,“WRITE_TRUNCATE”和“WRITE_APPEND”。 前者告诉 bqr_upload_data() 覆盖表中的现有数据,而后者告诉它追加新数据。 因此,要上传这个新数据,我会写:

bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
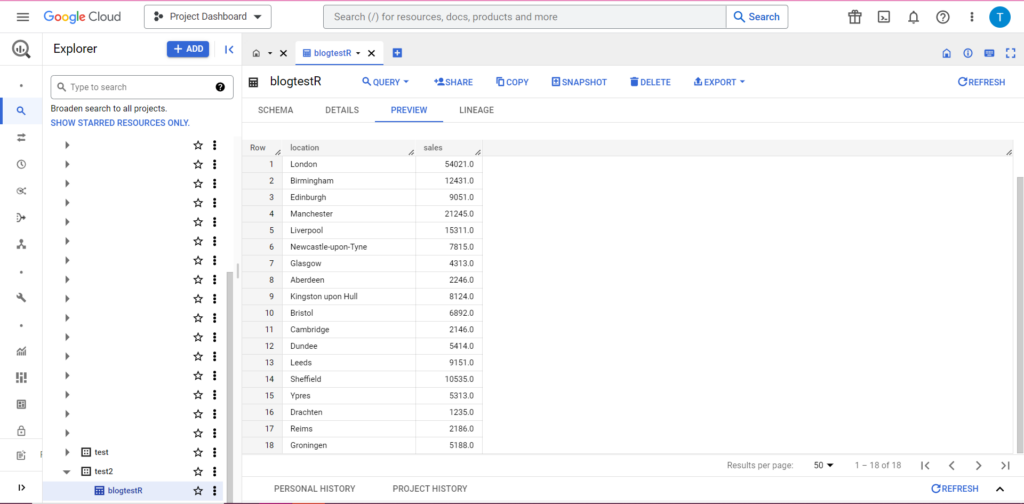
果然,在 BigQuery 中我们可以看到我们的数据有一些新室友:
从 Python 上传到 BigQuery
在 Python 中,情况有些不同。 再一次,我们需要导入一些包,所以让我们从这些开始:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
授权很复杂。 我们将再次需要一个包含凭据的 JSON 文件。 如上所述,我们将导航到 Google Cloud Console 并点击“APIs and Services”,然后点击侧边栏中的“Credentials”。 这一次,在页面底部,将有一个名为“服务帐户”的部分。
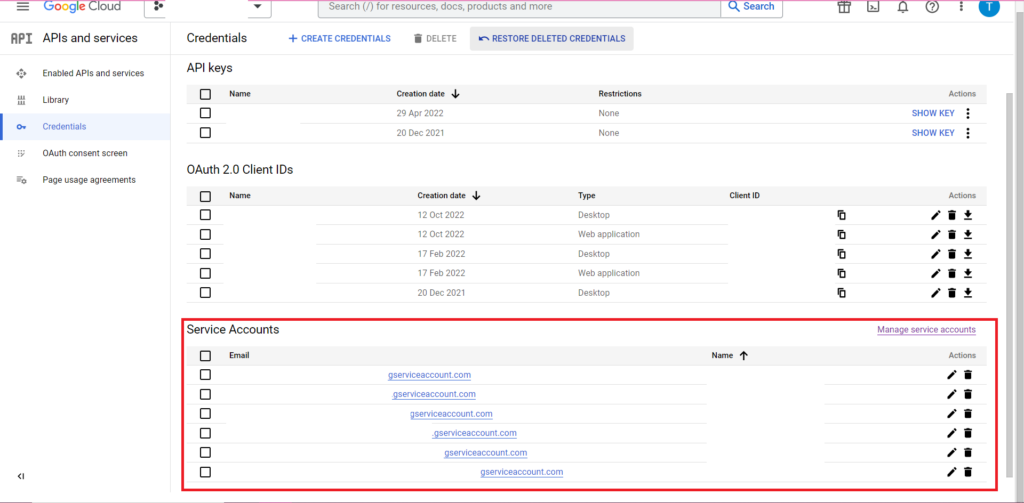
在那里,您可以将密钥下载到您的服务帐户,或者通过单击“管理服务帐户”,您可以创建一个新密钥或一个新的服务帐户,您可以为其下载凭据。
然后,您需要确保您的服务帐户有权访问和编辑您的 BigQuery 项目。 再次导航到边栏中“IAM 和管理”下的 IAM 页面,您可以在此处使用页面顶部的“授予访问权限”按钮授予您的服务帐户对相关项目的访问权限。
整理好后,您可以编写授权代码:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
接下来,您必须将数据放入数据框中。 Dataframes 属于 pandas 包,创建起来非常简单。 要从 CSV 中读入,请按照以下示例操作:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
显然,您需要将上面的路径替换为您自己的 CSV 文件。 要从 Excel 文件中读取,请按照以下示例操作:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
从谷歌表格中读取是很棘手的,需要另一轮授权。 我们将需要导入一些新包,并使用我们在上面的 R 教程中检索到的 JSON 凭据文件。 您可以按照此代码授权和读取您的数据:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
将数据放入数据框中后,就可以再次上传到 BigQuery 了! 您可以按照此模板执行此操作:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
例如,这是我刚刚编写的用于上传我之前制作的数据的代码:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
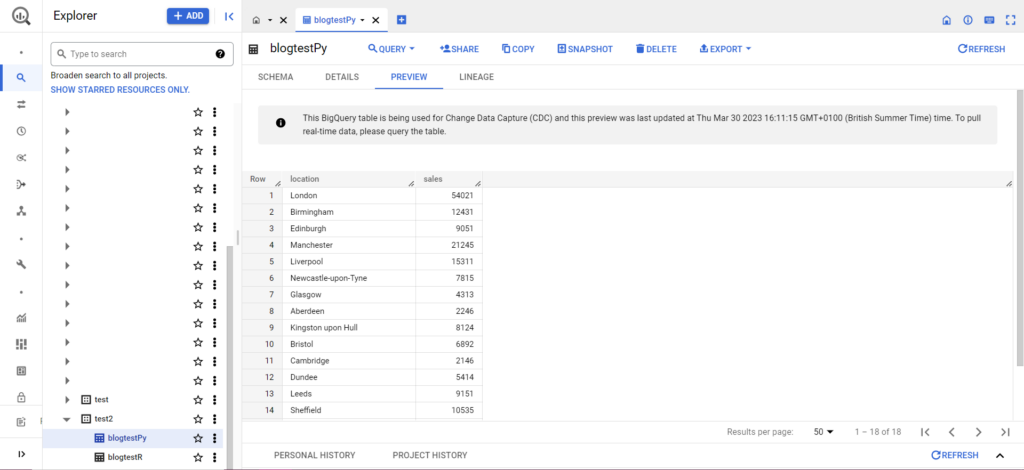
一旦完成,数据应该立即出现在 BigQuery 中!
一旦掌握了这些功能,您可以使用它们做更多的事情。 如果您想更好地控制您的分析设置,Semetrical 可以为您提供帮助! 查看我们的博客,了解有关如何充分利用数据的更多信息。 或者,要获得有关所有事物分析的更多支持,请访问 Web Analytics 以了解我们如何为您提供帮助。