
搜索引擎使用什么技术来抓取网站?
已发表: 2023-03-02
如果您曾经想知道搜索引擎使用什么技术来抓取网站,那么请准备好最终让您的问题得到解答。 您将了解到网络爬虫是什么、主要搜索引擎使用的许多不同类型的网络爬虫,以及搜索索引过程的全部内容。 您还将了解所有这些将如何影响搜索引擎结果,以及网站所有者如何告诉搜索引擎网络爬虫根据他们的意愿为内容编制索引。 让我们进一步了解搜索引擎使用的这项技术,它可以将数十亿个相关搜索结果准确地提供给在万维网上寻找信息的人们。
什么是网络爬虫或搜索引擎机器人?
网络爬虫机器人也称为蜘蛛,是一种自动化程序,谷歌和微软等公司使用这些程序来教他们的搜索引擎他们可以在互联网上找到的每个网站的每个可访问网页上显示的内容。 只有通过了解网页上包含哪些信息,这些搜索引擎才能在其用户之一键入请求了解特定主题的搜索查询时准确检索此信息。
网络爬虫机器人的类型
每个搜索引擎都有自己的网络爬虫。 这里有一些最广泛使用的。
谷歌机器人
谷歌是地球上最流行的搜索引擎,它使用两个版本的网络爬虫来索引数千亿个网页。 GoogleBot Desktop 将查看模仿某人使用台式计算机浏览互联网的行为的页面,而 GoogleBot Mobile 将对智能手机用户执行相同的操作。
GoogleBot 是有史以来最有效的搜索机器人之一,可以快速抓取网页并为其编制索引。 然而,它在爬行非常复杂的网站结构时确实存在一些问题。 此外,GoogleBot 通常需要几天或几周的时间来抓取新发布的网页,这意味着它暂时不会出现在相关结果中。
冰棒
Bingbot 是微软在自己的搜索引擎 Bing 上对谷歌的回应。 这与 Google 的网络爬虫类似,甚至包括一个抓取工具,指示机器人将如何抓取页面,让您查看此处是否存在任何问题。
吸食机器人
Slurp Bot 是雅虎使用的网络爬虫,尽管他们也使用 Bingbot 来提供他们的搜索引擎结果。 如果网站所有者希望其网页内容出现在雅虎移动搜索结果中,则必须允许 Slurp Bot 访问。 此外,Slurp Bot 还可以访问雅虎的合作伙伴网站,将内容添加到他们的雅虎新闻、雅虎体育和雅虎财经网站。
鸭鸭机器人
这是 DuckDuckGo 使用的网络爬虫,DuckDuckGo 是一种搜索引擎,以通过不像许多流行的那样跟踪用户的活动而为其用户提供无与伦比的隐私级别而闻名。 他们提供从 DuckDuckBot 以及维基百科等众包网站和其他搜索引擎获得的搜索结果。
百度蜘蛛和 Yandex Bot
这些是中国搜索引擎百度和俄罗斯 Yandex 分别使用的爬虫机器人。 百度在中国大陆搜索引擎市场占有率超过80%。
网络抓取、搜索索引和搜索引擎排名的工作原理
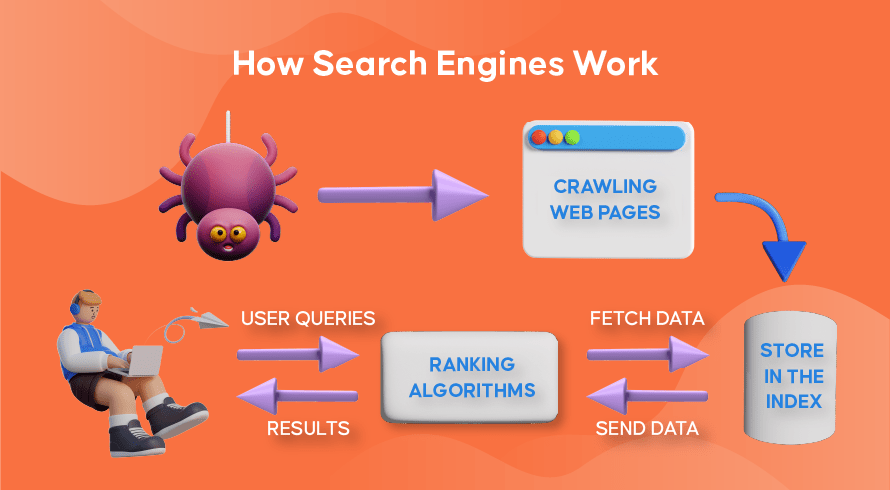
现在让我们探讨一下大多数搜索引擎如何使用网络爬虫来查找、存储、组织和检索网站中包含的信息。
网络爬虫的工作原理
在网站上查找新内容和更新内容的过程称为“网络爬行”,执行此功能的软件程序因此得名。 机器人将首先开始抓取一些网页,找到其内容,然后跟随该网页上包含的超链接来发现新的 URL,从而获得更多内容。
搜索引擎索引的工作原理
在机器人通过网络爬行发现新的或更新的内容后,他们发现的所有内容都会被添加到一个名为“搜索引擎索引”的庞大数据库中。 这就像一个图书馆,其中的书籍就像网页一样,经过组织以便以后轻松检索。 每本书中包含我们可以看到的网页上包含的大部分文本(不包括“a”、“an”和“the”等词)以及只有爬虫才能看到的元数据。 元数据是搜索引擎用来理解网页内容的。 元标题和元描述是元数据的示例。
搜索排名如何运作
每当用户输入搜索查询时,相应的搜索引擎将检查其索引,找到与该请求最相关的信息,组织包含相关内容的网络链接列表,并将其呈现给搜索引擎中的用户结果页面 (SERP)。
SERP 的这种组织称为“搜索排名”,由搜索算法执行,该算法考虑了收集的数据,包括元数据、网站(权威)的可信度以及关键字和链接。 被认为是非常可靠的来源并包含对用户有用的高度相关内容的网站将排名很高,在 SERP 上获得最高结果。 这就是为什么每个网站所有者都有策略在 SERP 上对他们的网站进行排名。
搜索引擎优化 (SEO) 如何进入图片
网站所有者可以优化其页面上的内容,使搜索引擎更容易将其识别为对用户相关且有用。 这会将这些页面推到 SERP 的顶部,为网站带来更多自然流量。 战略性地在页面副本、链接构建以及使用原始图像和视频中包含相关关键字是可以利用 SEO 技术的一些方式。
此外,网站还可以使用 SEMrush 等各种工具来查找和修复其页面上的各种问题,例如断开的链接,这将进一步提高其在搜索引擎眼中的排名。
告诉搜索引擎如何抓取您的网站

有时您会发现网络爬虫没有充分发挥其功能,导致索引中缺少您网站的重要页面。 这意味着相关搜索查询不会随您的内容一起显示,从而使潜在客户难以找到访问您页面的方式。 幸运的是,有一些方法可以与搜索引擎进行通信,让您可以对哪些内容被编入索引以及哪些内容被忽略进行一些控制。
存储在您网站根目录中的 robots.txt 文件会告诉网络爬虫您要抓取哪些页面、要忽略哪些页面以及您的网站架构是如何安排的。 如果特定页面用于测试、特殊促销和电子商务中使用的重复 URL,您可能希望阻止它们被编入索引。
例如,如果不存在 robots.txt 文件,GoogleBot 仍将继续抓取完整的网站。 当检测到您的 robots.txt 文件时,GoogleBot 会在抓取时按照您的指示进行操作。 如果它在检测文件时遇到问题或遇到错误,它可能不会抓取您的网站。 您必须正确使用 robots.txt 文件,组织您的网站架构,并使用页面 SEO 最佳实践来避免任何抓取问题。 您可以执行网站审核来分析和识别困扰您网站的任何问题。
您的网站需要 SEO 服务吗?
如果您正在寻找了解网络爬虫和搜索索引如何提高网站排名的服务提供商,那么 Inquivix 就是您一直在寻找的 SEO 合作伙伴。 我们提供从内容创建到网站架构优化和网站性能分析的一整套页面搜索引擎优化服务,以不断提高您的网站体验质量。 要了解更多信息,请立即访问 Inquivix On-Page SEO 服务!
常见问题
搜索引擎使用称为“网络爬虫”(也称为“蜘蛛”或“机器人”)的程序来发现网站页面上的新内容和更新内容。 然后它将按照页面中包含的链接查找更多页面。 在页面上找到的内容保存在索引中,该索引用于在用户请求时检索搜索结果的信息。

GoogleBot Desktop 和 GoogleBot Mobile 是大多数国家/地区最流行的网络抓取工具,其次是 Bingbot、Slurp Bot 和 DuckDuckBot。 Baiduspider 主要在中国使用,而 Yandex Bot 在俄罗斯使用。