
提升 LLM 吞吐量的先進技術
已發表: 2024-04-02在快節奏的科技世界中,大型語言模型 (LLM) 已成為我們與數位資訊互動方式的關鍵角色。 這些強大的工具可以撰寫文章、回答問題,甚至進行對話,但它們並非沒有挑戰。 當我們對這些模型提出更多要求時,我們就會遇到障礙,特別是在讓它們更快、更有效率地工作時。 這個部落格就是關於正面解決這些障礙的。
我們正在深入研究一些明智的策略,旨在提高這些模型的運行速度,同時又不損失其輸出的品質。 想像一下,嘗試提高賽車的速度,同時確保它仍然可以完美地通過急彎 - 這就是我們使用大型語言模型的目標。 我們將研究諸如連續批處理之類的方法,它有助於更順利地處理信息,以及諸如分頁和 Flash Attention 之類的創新方法,這使得法學碩士在數字推理中更加專注和更快。
因此,如果您對突破這些人工智慧巨頭的極限感到好奇,那麼您來對地方了。 讓我們一起探討這些先進技術如何塑造法學碩士的未來,使它們比以往更快、更好。
法學碩士實現更高吞吐量的挑戰
在大型語言模型 (LLM) 中實現更高的吞吐量面臨著幾個重大挑戰,每個挑戰都會阻礙這些模型運行的速度和效率。 一個主要障礙是處理和儲存這些模型所使用的大量資料所需的絕對記憶體需求。 隨著法學碩士複雜性和規模的成長,對運算資源的需求不斷增加,使得維持處理速度變得困難,更不用說提高處理速度了。
另一個主要挑戰是法學碩士的自回歸性質,特別是在用於生成文本的模型中。 這意味著每個步驟的輸出都依賴先前的輸出,從而創建了順序處理要求,該要求本質上限制了任務的執行速度。 這種順序依賴性通常會導致瓶頸,因為每個步驟都必須等待其前一個步驟完成才能繼續,從而阻礙了實現更高吞吐量的努力。
此外,準確性和速度之間的平衡是一個微妙的平衡。 在不影響輸出品質的情況下提高吞吐量就像走鋼絲,需要能夠駕馭運算效率和模型有效性的複雜環境的創新解決方案。
這些挑戰構成了法學碩士優化進步的背景,突破了自然語言處理及其他領域的可能性界限。
記憶體需求
解碼階段在每個時間步驟產生單一令牌,但每個令牌取決於所有先前令牌的鍵和值張量(包括預先填充時計算的輸入令牌的KV 張量,以及當前時間步之前計算的任何新KV 張量) 。
因此,為了最大限度地減少每次的冗餘計算,並避免在每個時間步重新計算所有標記的所有這些張量,可以將它們緩存在 GPU 記憶體中。 每次迭代,當計算新元素時,它們都會簡單地添加到正在運行的快取中,以便在下一次迭代中使用。 這本質上稱為 KV 快取。
這大大減少了所需的運算量,但引入了記憶體需求,而且大型語言模型的記憶體需求已經很高,這使得在商用 GPU 上運行變得困難。 隨著模型參數大小(7B 到 33B)的增加和精確度的提高(fp16 到 fp32),記憶體需求也隨之增加。 讓我們來看一個所需記憶體容量的範例,
眾所周知,兩個主要的記憶體佔用者是
- 模型本身的權重在記憶體中,這個自帶的沒有。 7B 等參數和每個參數的資料類型,例如,fp16 中的 7B(2 位元組)~= 記憶體中的 14GB
- KV快取:用於self-attention階段的key值的緩存,避免冗餘計算。
每個令牌的 KV 快取大小(以位元組為單位) = 2 * (num_layers) * (hidden_size) * precision_in_bytes
第一個因數 2 說明 K 和 V 矩陣。 這些hidden_size和dim_head可以從模型的卡片或設定檔中取得。
上面的公式是針對每個 token 的,因此對於輸入序列,它將是 seq_len * size_of_kv_per_token。 所以上面的公式就會轉換為,
KV 快取的總大小(以位元組為單位) = (sequence_length) * 2 * (num_layers) * (hidden_size) * precision_in_bytes
例如,對於 fp16 中的 LLAMA 2,大小將為 (4096) * 2 * (32) * (4096) * 2,即 ~2GB。
以上是針對單一輸入的,如果沒有導致記憶體不足和碎片問題,那麼這種動態記憶體分配和管理將成為實現最佳效能的關鍵步驟。
有時,記憶體需求超過了 GPU 的容量,在這種情況下,我們需要研究模型並行性、張量並行性,這裡沒有討論,但您可以朝這個方向探索。
自回歸和記憶體限制操作
正如我們所看到的,大型語言模型的輸出產生部分本質上是自回歸的。 表示要產生任何新令牌,它取決於所有先前的令牌及其中間狀態。 由於在輸出階段並非所有令牌都可用於進一步計算,並且它只有一個向量(用於下一個令牌)和前一階段的區塊,因此這就像矩陣向量運算,在以下情況下未充分利用GPU 運算能力:與預填充階段相比。 資料(權重、鍵、值、啟動)從記憶體傳輸到 GPU 的速度決定了延遲,而不是計算實際發生的速度。 換句話說,這是一個記憶體限制操作。

克服吞吐量挑戰的創新解決方案
連續配料
減少解碼階段記憶體限制的非常簡單的步驟是對輸入進行批次處理並同時對多個輸入進行計算。 但是,由於生成的序列長度不同,簡單的常數批次會導致效能不佳,而這裡批次的延遲取決於批次中產生的最長序列,並且由於多個輸入是不斷增長的,因此記憶體需求也不斷增長。現在立即處理。
因此,單純的靜態配料效果不佳,出現了連續配料。 其本質在於動態聚合傳入的請求批次,適應波動的到達率,並在可行的情況下利用並行處理的機會。 這也透過將每個批次中相似長度的序列分組在一起來優化記憶體利用率,從而最大限度地減少較短序列所需的填充量,並避免在過度填充上浪費計算資源。
它根據當前記憶體容量、計算資源和輸入序列長度等因素自適應調整批次大小。 這可確保模型在不同條件下以最佳方式運行,而不會超出記憶體限制。 這有助於分頁注意力(如下所述)有助於減少延遲並提高吞吐量。
進一步閱讀:連續批次如何在 LLM 推理中實現 23 倍吞吐量,同時減少 p50 延遲
分頁關注
當我們透過批次來提高吞吐量時,它也會以增加 KV 快取記憶體需求為代價,因為我們現在一次處理多個輸入。 這些序列可能超出可用運算資源的儲存容量,從而使得對其整體進行處理是不切實際的。
我們還觀察到,KV 快取的簡單記憶體分配會導致大量記憶體碎片,就像我們在電腦系統中觀察到的那樣,由於記憶體分配不均勻。 vLLM 引入了 Paged Attention,這是一種受作業系統分頁和虛擬記憶體概念啟發的記憶體管理技術,可有效處理 KV 快取不斷增長的需求。
分頁注意力透過將注意力機制劃分為更小的頁面或段來解決記憶體限制,每個頁面或段覆蓋輸入序列的子集。 該模型不是一次計算整個輸入序列的注意力分數,而是一次關註一頁,按順序處理它。
在推理或訓練期間,模型迭代輸入序列的每一頁,計算注意力分數並相應地產生輸出。 處理完一個頁面後,其結果將被存儲,並且模型將移至下一頁。
透過將注意力機制劃分為頁面,分頁注意力允許大型語言模型在不超出記憶體限制的情況下處理任意長度的輸入序列。 它有效地減少了處理長序列所需的記憶體佔用,從而可以處理大型文件和批次。
進一步閱讀:使用 vLLM 和 PagedAttention 進行快速 LLM 服務
閃關注
由於注意力機制對於大型語言模型所基於的 Transformer 模型至關重要,因此它有助於模型在進行預測時專注於輸入文字的相關部分。 然而,隨著基於 Transformer 的模型變得越來越大、越來越複雜,自註意力機制變得越來越慢並且佔用大量內存,從而導致前面提到的內存瓶頸問題。 Flash Attention 是另一種最佳化技術,旨在透過優化注意力操作來緩解此問題,從而實現更快的訓練和推理。
Flash Attention 的主要特色:
核心融合:重要的是不僅要最大化 GPU 運算使用率,還要使其能夠實現高效操作。 Flash Attention 將多個運算步驟合併到一個作業中,減少了重複資料傳輸的需要。 這種簡化的方法簡化了實施過程並提高了計算效率。
平鋪:Flash Attention 將載入的資料分割為更小的區塊,有助於並行處理。 該策略優化了記憶體使用,為具有更大輸入大小的模型提供了可擴展的解決方案。
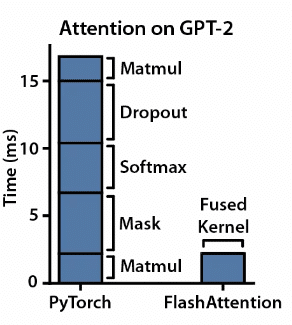
(融合的 CUDA 核心描述了平鋪和融合如何減少運算所需的時間,圖片來源:FlashAttention:Fast and Memory-Efficient Exact Attention with IO-Awareness)
記憶體最佳化:Flash Attention 僅載入過去幾個令牌的參數,重複使用最近計算的令牌的啟動。 這種滑動視窗方法減少了載入權重的 IO 請求數量並最大化快閃記憶體吞吐量。
減少資料傳輸:Flash Attention 可最大程度地減少高頻寬記憶體 (HBM) 和 SRAM(靜態隨機存取記憶體)等記憶體類型之間的來回資料傳輸。 透過僅載入所有資料(查詢、鍵和值)一次,可以減少重複資料傳輸的開銷。
案例研究 - 透過推測解碼優化推理
在自迴歸語言模型中用於加速文字產生的另一種方法是推測解碼。 推測性解碼的主要目標是加快文字生成速度,同時將生成文字的品質保持在與目標分佈相當的水平。
推測性解碼引入了一個小型/草稿模型,該模型預測序列中的後續標記,然後主模型根據預先定義的標準接受/拒絕這些標記。 將較小的草稿模型與目標模型整合可以顯著提高文字生成的速度,這是由於記憶體需求的本質。 由於草稿模型較小,因此要求較少。 要載入的神經元權重和數量。 與主模型相比,現在的計算量也更少,這減少了延遲並加快了輸出生成過程。 然後,主模型評估產生的結果並確保其符合下一個可能標記的目標分佈。
從本質上講,推測性解碼透過利用更小、更快的草稿模型來預測後續標記,從而簡化了文本生成過程,從而加快了文本生成的整體速度,同時保持生成內容的品質接近目標分佈。
非常重要的是,較小模型產生的令牌並不總是不斷被拒絕,這種情況會導致性能下降而不是提高。 透過實驗和用例的性質,我們可以選擇較小的模型/在推理過程中引入推測解碼。
結論
透過增強大語言模型 (LLM) 吞吐量的先進技術的旅程照亮了自然語言處理領域的前進道路,不僅展示了挑戰,還展示了可以正面應對這些挑戰的創新解決方案。 這些技術,從連續批次到分頁和 Flash Attention,以及有趣的推測解碼方法,不僅僅是漸進式改進。 它們代表了我們使大型語言模型更快、更有效率並最終更容易被廣泛應用程式存取的能力的重大飛躍。
這些進步的重要性怎麼強調都不為過。 在優化 LLM 吞吐量和提高效能時,我們不僅僅是調整這些強大模型的引擎; 我們正在重新定義處理速度和效率方面的可能性。 這反過來又為大型語言模型的應用開闢了新的視野,從可以以對話速度運行的即時語言翻譯服務,到能夠以前所未有的速度處理海量資料集的高級分析工具。
此外,這些技術強調了大型語言模型最佳化的平衡方法的重要性——一種仔細考慮速度、準確性和計算資源之間相互作用的方法。 當我們突破法學碩士能力的界限時,保持這種平衡對於確保這些模型能夠繼續作為跨眾多行業的多功能且可靠的工具至關重要。
增強大語言模型吞吐量的先進技術不僅僅是技術成果; 它們是人工智慧不斷發展的里程碑。 他們承諾使法學碩士更具適應性、更有效率、更強大,為未來的創新鋪平道路,從而繼續改變我們的數位格局。
在我們最近的部落格文章中了解有關大型語言模型推理優化的 GPU 架構的更多信息