
從網站抓取資料的最佳實踐和用例
已發表: 2023-12-28從網站抓取資料時,必須遵守目標網站的規定和框架。 遵守最佳實踐不僅是道德問題,而且還可以避免法律複雜性並保證資料提取的可靠性。 以下是主要考慮因素:
- 遵守 robots.txt :始終首先檢查此文件,以了解網站所有者設定的抓取禁區。
- 利用 API :如果可用,請使用網站的官方 API,這是一種更穩定且經過認可的資料存取方法。
- 注意請求率:過多的資料抓取可能會給網站伺服器帶來負擔,因此請謹慎調整您的請求速度。
- 識別自己:透過您的用戶代理字串,在抓取時對您的身分和目的保持透明。
- 負責任地處理資料:根據隱私權法和資料保護法規儲存和使用抓取的資料。
遵循這些做法可確保道德抓取,並維護線上內容的完整性和可用性。
了解法律框架
從網站上抓取資料時,了解相互交織的法律限制至關重要。 主要立法文本包括:
- 電腦詐欺和濫用法案 (CFAA):美國立法 未經適當授權存取電腦是非法的。
- 歐盟的《一般資料保護規範》(GDPR) :強制要求同意個人資料的使用並授予個人對其資料的控制權。
- 數位千禧年版權法 (DMCA) :防止未經許可分發受版權保護的內容。
抓取者還必須尊重網站的「使用條款」協議,這通常會限制資料提取。 確保遵守這些法律和政策對於以道德和合法的方式廢棄網站資料至關重要。
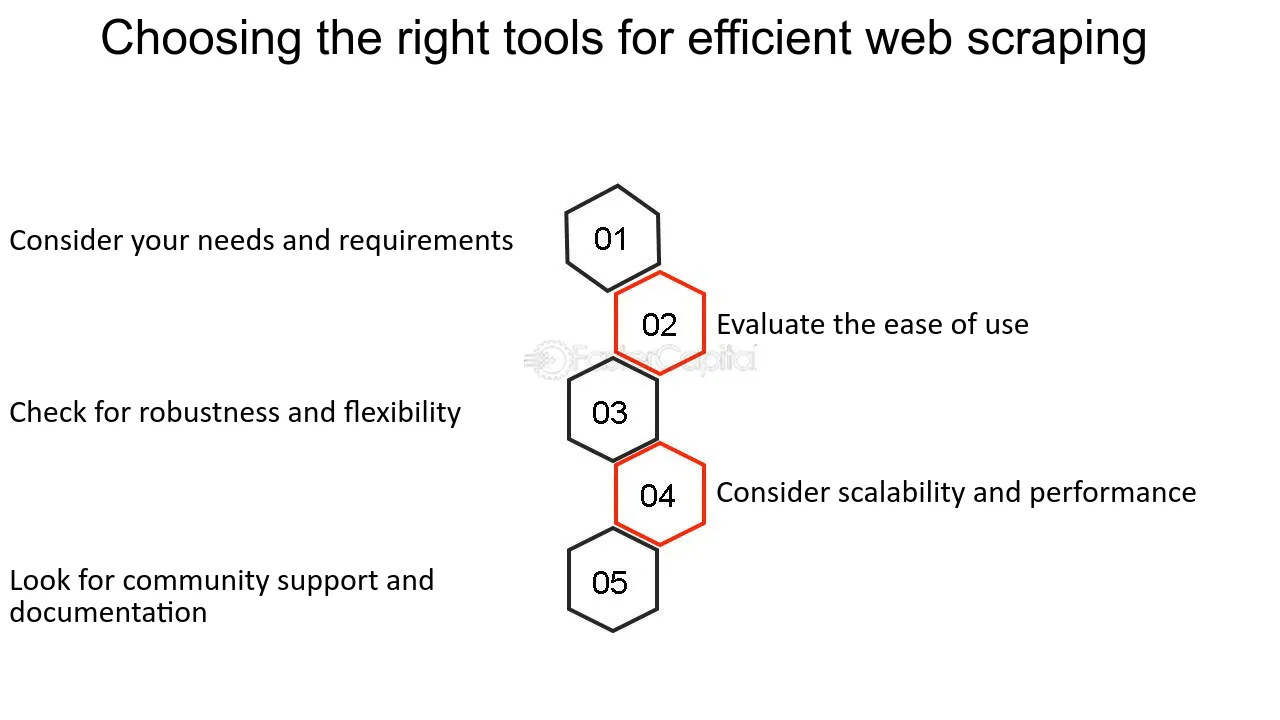
選擇正確的抓取工具
在啟動網頁抓取專案時,選擇正確的工具至關重要。 需要考慮的因素包括:
- 網站的複雜度:動態網站可能需要像 Selenium 這樣可以與 JavaScript 互動的工具。
- 資料量:對於大規模抓取,建議使用具有分散式抓取功能的工具,例如Scrapy。
- 合法性和道德:選擇具有尊重 robots.txt 和設定使用者代理字串功能的工具。
- 易於使用:新手可能更喜歡 Octoparse 等軟體中的使用者友善介面。
- 程式設計知識:非編碼人員可能傾向於帶有 GUI 的軟體,而程式設計師可以選擇 BeautifulSoup 等函式庫。
圖片來源:https://fastercapital.com/
有效從網站抓取資料的最佳實踐
若要有效率、負責任地從網站上抓取數據,請遵循以下準則:
- 尊重 robots.txt 檔案和網站條款以避免法律問題。
- 使用標頭並旋轉用戶代理來模仿人類行為。
- 在請求之間實施延遲以減少伺服器負載。
- 利用代理來防止 IP 封鎖。
- 在非尖峰時段進行抓取,以最大程度地減少網站中斷。
- 始終有效地儲存數據,避免重複條目。
- 透過定期檢查確保抓取資料的準確性。
- 儲存和使用資料時請注意資料隱私法。
- 保持您的抓取工具處於最新狀態以應對網站變更。
- 如果網站更新其結構,請隨時準備好調整抓取策略。
跨產業的資料抓取用例
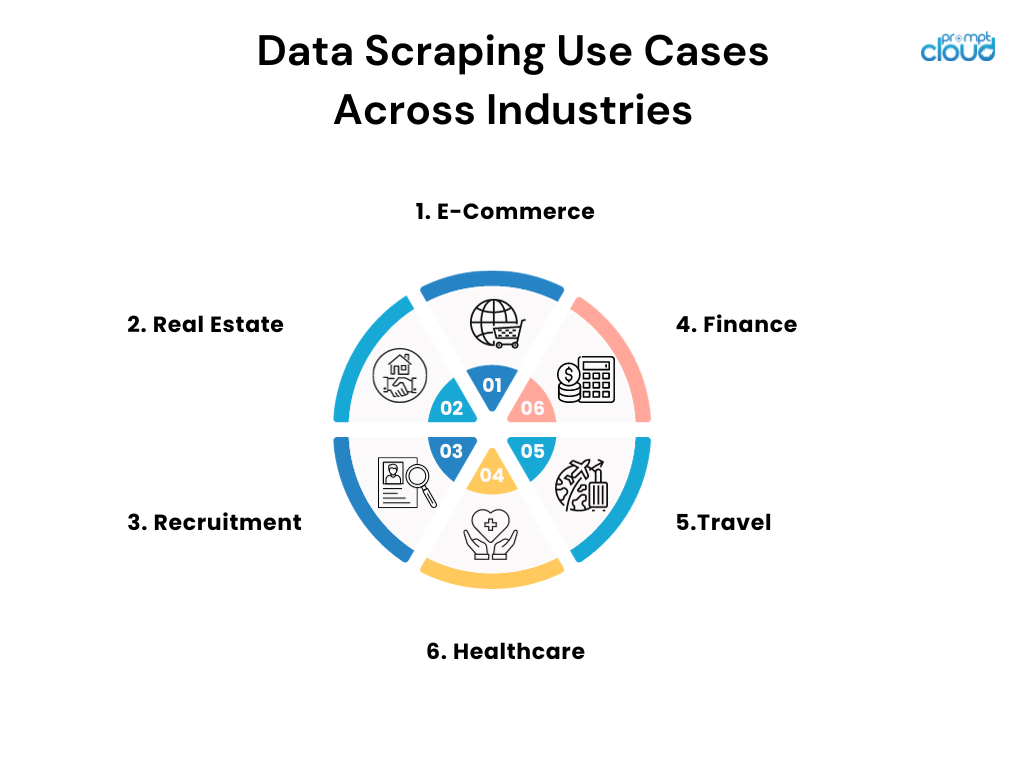
- 電子商務:線上零售商部署抓取來監控競爭對手的價格並相應地調整其定價策略。
- 房地產:代理商和公司從各種來源抓取清單以匯總房地產資訊、趨勢和價格資料。
- 招聘:公司透過招聘網站和社交媒體來尋找潛在的候選人並分析就業市場趨勢。
- 金融:分析師蒐集公共記錄和財務文件,以告知投資策略並追蹤市場情緒。
- 旅行:代理商會調低航空公司和飯店的價格,為顧客提供盡可能最好的優惠和套餐。
- 醫療保健:研究人員抓取醫學資料庫和期刊,以了解最新的發現和臨床試驗。
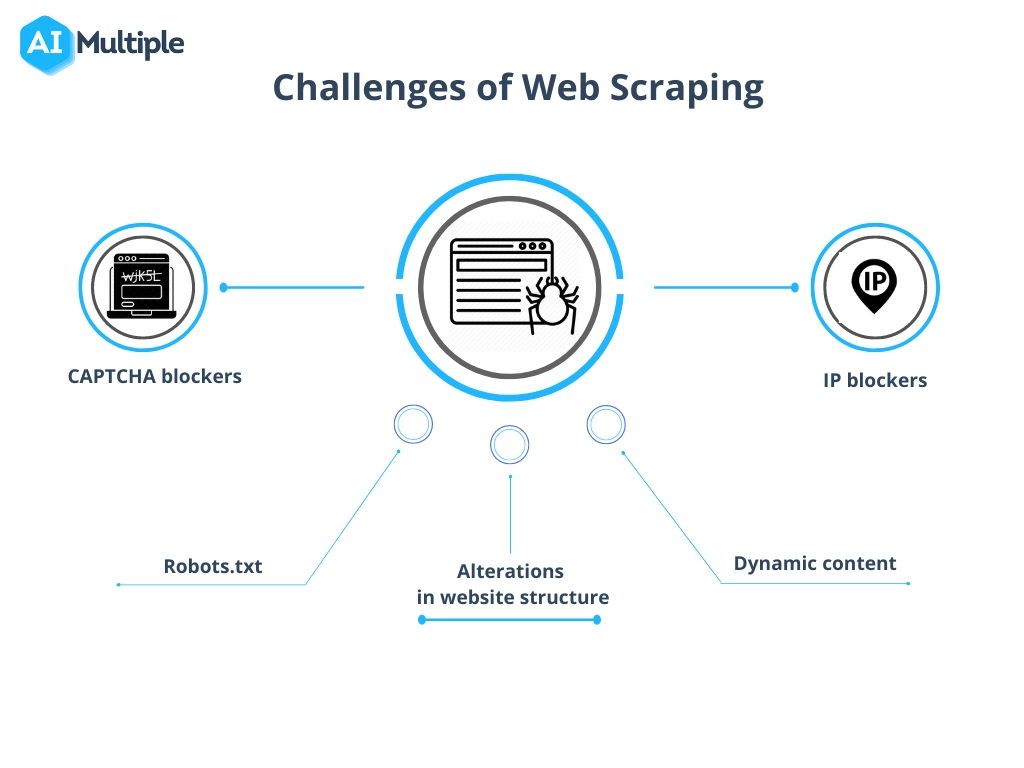
解決資料抓取中的常見挑戰
從網站抓取資料的過程雖然非常有價值,但經常涉及克服網站結構的改變、反抓取措施和資料品質問題等障礙。

圖片來源:https://research.aimultiple.com/
要有效地導航這些內容:
- 保持適應性:定期更新抓取腳本以符合網站更新。 使用機器學習可以幫助動態適應結構變化。
- 尊重法律邊界:了解並遵守抓取的合法性以避免訴訟。 請務必查看網站上的 robots.txt 檔案和服務條款。
- 表格頂部
- 模仿人類互動:網站可能會阻止發送請求過快的抓取工具。 在請求之間實施延遲和隨機間隔,以顯得不那麼機械化。
- 處理驗證碼:可以使用可以解決或繞過驗證碼的工具和服務,但必須考慮其使用是否會產生道德和法律影響。
- 維護資料完整性:確保擷取資料的準確性。 定期驗證資料並清理資料以保持品質和有用性。
這些策略有助於克服常見的抓取障礙並促進有價值的資料提取。
結論
從網站中有效提取資料是一種有價值的方法,具有多種應用,從市場研究到競爭分析。 必須遵守最佳實踐、確保合法性、尊重 robots.txt 準則並仔細控制抓取頻率以防止伺服器過載。
負責任地應用這些方法為豐富的資料來源打開了大門,這些資料來源可以提供可行的見解並推動企業和個人做出明智的決策。 正確的實施加上道德考慮,可以確保資料抓取仍然是數位領域的強大工具。
準備好透過從網站抓取資料來增強您的見解了嗎? 別再猶豫了! PromptCloud 提供符合您需求的道德且可靠的網頁抓取服務。 請透過 sales@promptcloud.com 與我們聯繫,將原始資料轉化為可操作的情報。 讓我們一起增強您的決策能力!
經常問的問題
從網站上抓取資料是否可以接受?
當然,資料抓取是可以的,但你必須遵守規則。 在進行任何抓取冒險之前,請仔細查看相關網站的服務條款和 robots.txt 檔案。 尊重網站的佈局、遵守頻率限制以及保持道德規範都是負責任的資料抓取實踐的關鍵。
如何透過抓取從網站中提取用戶資料?
透過抓取提取用戶資料需要採取符合法律和道德規範的細緻方法。 只要可行,建議利用網站提供的公開 API 進行資料檢索。 在沒有 API 的情況下,必須確保所採用的抓取方法遵守隱私權法、使用條款以及網站制定的政策,以減輕潛在的法律後果
抓取網站資料是否被視為非法?
網路抓取的合法性取決於多種因素,包括目的、方法以及對相關法律的遵守。 雖然網頁抓取本身並不違法,但未經授權的存取、違反網站的服務條款或無視隱私權法可能會導致法律後果。 網路抓取活動中負責任和道德的行為至關重要,涉及對法律界限和道德考慮的敏銳認識。
網站可以偵測網頁抓取的實例嗎?
網站已實施偵測並防止網路抓取活動的機制,監控使用者代理字串、IP 位址和請求模式等元素。 為了減輕檢測,最佳實踐包括採用輪換用戶代理、利用代理以及在請求之間實現隨機延遲等技術。 然而,值得注意的是,試圖規避偵測措施可能會違反網站的服務條款,並可能導致法律後果。 負責任和道德的網路抓取實踐優先考慮透明度並遵守法律和道德標準。