
使用 Python 進行動態網頁抓取 – 操作指南
已發表: 2024-06-08動態網頁抓取涉及從透過 JavaScript 或 Python 即時產生內容的網站檢索資料。 與靜態網頁不同,動態內容是非同步載入的,這使得傳統的抓取技術效率低落。
動態網頁抓取用途:
- 基於 AJAX 的網站
- 單頁應用程式 (SPA)
- 具有延遲載入元素的網站
關鍵工具和技術:
- Selenium – 自動化瀏覽器互動。
- BeautifulSoup – 解析 HTML 內容。
- 請求– 取得網頁內容。
- lxml – 解析 XML 和 HTML。
動態網路抓取Python需要更深入地了解網路技術才能有效地收集即時資料。
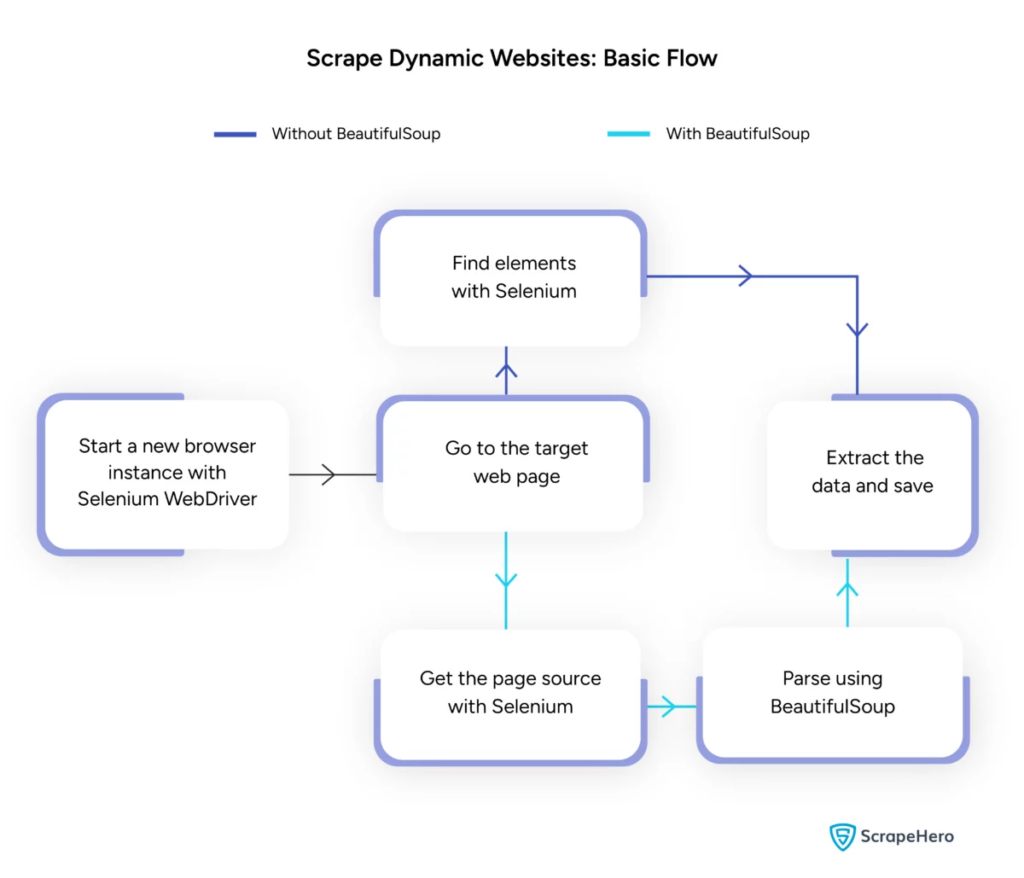
圖片來源:https://www.scrapehero.com/scrape-a-dynamic-website/
設定Python環境
若要開始動態 Web 抓取 Python,必須正確設定環境。 按著這些次序:
- 安裝 Python :確保機器上安裝了 Python。 最新版本可從Python官方網站下載。
- 建立虛擬環境:

啟動虛擬環境:

- 安裝所需的庫:

- 設定程式碼編輯器:使用 PyCharm、VSCode 或 Jupyter Notebook 等 IDE 來編寫和執行腳本。
- 熟悉 HTML/CSS :了解網頁結構有助於有效導覽和擷取資料。
這些步驟為動態網頁抓取 Python 專案奠定了堅實的基礎。
了解 HTTP 請求的基礎知識
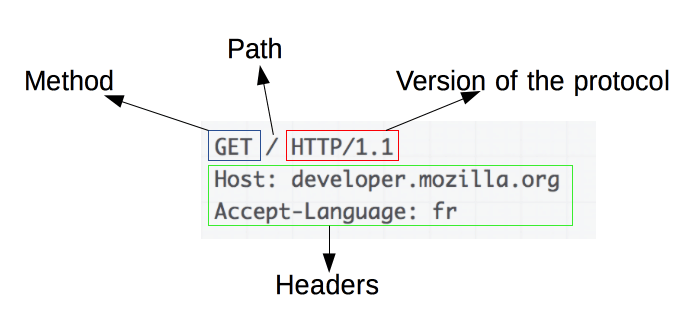
圖片來源:https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
HTTP 請求是網頁抓取的基礎。 當客戶端(例如 Web 瀏覽器或 Web scraper)想要從伺服器檢索資訊時,它會傳送 HTTP 請求。 這些請求遵循特定的結構:
- Method :要執行的操作,例如 GET 或 POST。
- URL :資源在伺服器上的位址。
- headers :有關請求的元數據,例如內容類型和用戶代理。
- Body :隨請求發送的可選數據,通常與 POST 一起使用。
了解如何解釋和建立這些元件對於有效的網頁抓取至關重要。 像 requests 這樣的 Python 函式庫簡化了這個過程,允許對請求進行精確控制。
安裝Python庫
圖片來源:https://ajaytech.co/what-are-python-libraries/
對於使用 Python 進行動態網頁抓取,請確保安裝了 Python。 開啟終端機或命令提示字元並使用 pip 安裝必要的庫:
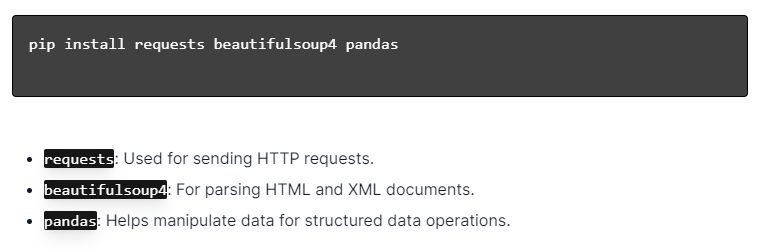
接下來,將這些庫匯入到您的腳本中:

透過這樣做,每個程式庫都可用於網頁抓取任務,例如傳送請求、解析 HTML 和有效管理資料。

建立簡單的網頁抓取腳本
要使用 Python 建立基本的動態網頁抓取腳本,必須先安裝必要的程式庫。 「requests」庫處理 HTTP 請求,而「BeautifulSoup」則解析 HTML 內容。
遵循的步驟:
- 安裝依賴項:

- 導入庫:

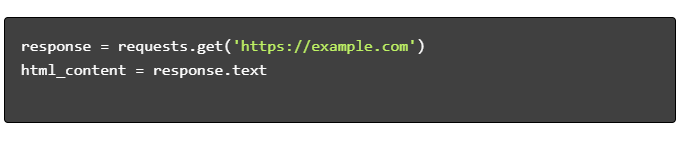
- 取得 HTML 內容:
- 解析 HTML:

- 擷取資料:

使用 Python 處理動態網頁抓取
動態網站動態產生內容,通常需要更複雜的技術。
考慮以下步驟:
- 識別目標元素:檢查網頁以尋找動態內容。
- 選擇 Python 框架:利用 Selenium 或 Playwright 等函式庫。
- 安裝所需的軟體包:
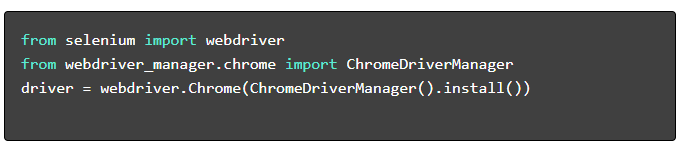
- 設定網路驅動程式:

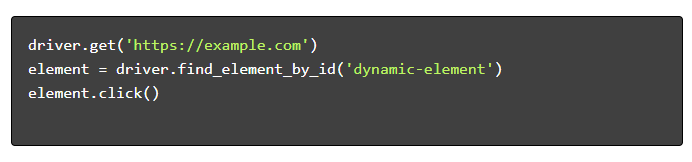
- 導航和互動:
網頁抓取最佳實踐
建議遵循網頁抓取最佳實踐,以確保效率和合法性。 以下是關鍵準則和錯誤處理策略:
- 尊重 Robots.txt :始終檢查目標網站的 robots.txt 檔案。
- 限制:實施延遲以防止伺服器過載。
- User-Agent :使用自訂的 User-Agent 字串以避免潛在的阻塞。
- 重試邏輯:使用 try- except 區塊並設定重試邏輯來處理伺服器逾時。
- 日誌記錄:維護全面的日誌以進行調試。
- 異常處理:專門捕捉網路錯誤、HTTP錯誤和解析錯誤。
- 驗證碼偵測:結合偵測和解決或繞過驗證碼的策略。
常見的動態網頁抓取挑戰
驗證碼
許多網站使用驗證碼來防止自動機器人。 要繞過這個:
- 使用 2Captcha 等驗證碼解決服務。
- 實施人為幹預來解決驗證碼。
- 使用代理來限制請求率。
IP封鎖
網站可能會阻止發出過多請求的 IP。 透過以下方式解決這個問題:
- 使用輪換代理。
- 實施請求限制。
- 採用用戶代理輪換策略。
JavaScript 渲染
有些網站透過 JavaScript 載入內容。 透過以下方式應對這項挑戰:
- 使用 Selenium 或 Puppeteer 實現瀏覽器自動化。
- 使用 Scrapy-splash 渲染動態內容。
- 探索無頭瀏覽器與 JavaScript 互動。
法律問題
網路抓取有時會違反服務條款。 透過以下方式確保合規性:
- 諮詢法律意見。
- 抓取可公開存取的資料。
- 遵守 robots.txt 指令。
資料解析
處理不一致的資料結構可能具有挑戰性。 解決方案包括:
- 使用 BeautifulSoup 等函式庫進行 HTML 解析。
- 使用正規表示式進行文字擷取。
- 使用 JSON 和 XML 解析器處理結構化資料。
儲存和分析抓取的數據
儲存和分析抓取的資料是網路抓取的關鍵步驟。 決定資料的儲存位置取決於資料的容量和格式。 常見的儲存選項包括:
- CSV 檔案:易於處理小型資料集和簡單分析。
- 資料庫:用於結構化資料的 SQL 資料庫; NoSQL 用於非結構化。
儲存後,可以使用 Python 庫來分析資料:
- Pandas :非常適合資料操作和清理。
- NumPy :高效率的數值運算。
- Matplotlib 和 Seaborn :適合資料視覺化。
- Scikit-learn :提供機器學習工具。
正確的資料儲存和分析可以提高資料的可存取性和洞察力。
結論和後續步驟
在了解了動態 Web 抓取 Python 後,有必要微調對突出顯示的工具和函式庫的理解。
- 檢查程式碼:查閱最終腳本並儘可能模組化以增強可重複使用性。
- 其他函式庫:探索 Scrapy 或 Splash 等高階函式庫以滿足更複雜的需求。
- 資料儲存:考慮強大的儲存選項 - SQL 資料庫或用於管理大型資料集的雲端儲存。
- 法律與道德考量:隨時了解網路擷取的法律準則,以避免潛在的侵權行為。
- 下一個項目:處理具有不同複雜性的新網頁抓取專案將進一步鞏固這些技能。
希望將專業的動態網頁抓取與 Python 整合到您的專案中? 對於那些需要大規模資料擷取而又無需複雜的內部處理的團隊,PromptCloud 提供了量身定制的解決方案。 探索 PromptCloud 的服務以獲得強大、可靠的解決方案。 今天就聯絡我們吧!