
R中的探索性因素分析
已發表: 2017-02-16什麼是R中的探索性因素分析?
探索性因子分析 (EFA) 或在 R 中粗略地稱為因子分析是一種統計技術,用於識別一組變量之間的潛在關係結構並將其縮小到較少數量的變量。 這實質上意味著大量變量的方差可以用幾個匯總變量即因子來描述。 這是R中探索性因子分析的概述。
顧名思義,EFA 本質上是探索性的——我們並不真正了解潛在變量,並且重複這些步驟,直到我們得到較少數量的因子。 在本教程中,我們將使用 R 來了解 EFA。現在,讓我們首先了解數據集的基本概念。
1. 數據
該數據集包含客戶在購買汽車時考慮的 14 個不同變量的 90 個響應。 調查問題採用 5 點李克特量表,1 表示非常低,5 表示非常高。 變量如下:
- 價格
- 安全
- 外觀
- 空間和舒適
- 技術
- 售後服務
- 轉售價值
- 汽油種類
- 燃油效率
- 顏色
- 維護
- 試駕
- 產品評論
- 感言
單擊此處下載編碼數據集。
2. 導入WebData
現在我們將以 CSV 格式存在的數據集讀入 R 並將其存儲為變量。
[代碼語言=“r”]數據<-read.csv(file.choose( ),header=TRUE) [/code]
它將打開一個窗口來選擇 CSV 文件,並且 `header` 選項將確保文件的第一行被視為標題。 輸入以下內容,查看數據框的前幾行,並確認數據已正確存儲。
[代碼語言=“r”]頭(數據)[/code]
3.包安裝
現在我們將安裝所需的包以進行進一步的分析。 這些包是 `psych` 和 `GParotation`。 在下面給出的代碼中,我們調用 `install.packages()` 進行安裝。
[代碼語言=”r”] install.packages('psych') install.packages('GPRotation') [/code]
4. 因素的數量
接下來,我們將找出我們將為因子分析選擇的因子數量。 這是通過“並行分析”和“特徵值”等方法進行評估的。
平行分析
我們將使用 `Psych` 包的 `fa.parallel` 函數來執行並行分析。 這裡我們指定數據框和因子方法(在我們的例子中是`minres`)。 運行以下命令以找到可接受的因子數並生成“碎石圖”:
[代碼語言=“r”]並行<- fa.parallel(data, fm = 'minres', fa = 'fa') [/code]
控制台將顯示我們可以考慮的最大因素數。 這是它的外觀。
“平行分析表明因子數 = 5,成分數 = NA”

在上面代碼生成的“碎石圖”中給出如下:
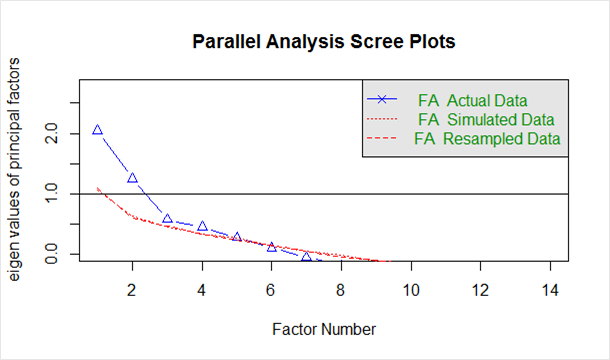
藍線顯示實際數據的特徵值,兩條紅線(相互重疊)顯示模擬和重採樣數據。 在這裡,我們查看實際數據中的大幅下降,並發現它向右穩定的點。 此外,我們找到了拐點——模擬數據和實際數據之間的差距趨於最小的點。
查看此圖和平行分析,2 到 5 個因素之間的任何地方都是不錯的選擇。
因子分析
現在我們已經得出了可能的因子數,讓我們從 3 作為因子數開始。 為了執行因子分析,我們將使用 `psych` 包`fa() 函數。 以下是我們將提供的論點:
- r - 原始數據或相關或協方差矩陣
- nfactors – 要提取的因子數
- rotate - 雖然有各種類型的旋轉,但 `Varimax` 和 `Oblimin` 是最受歡迎的
- fm – 因子提取技術之一,如“最小殘差 (OLS)”、“最大似然”、“主軸”等。
在這種情況下,我們將選擇傾斜旋轉(rotate = “oblimin”),因為我們認為這些因素之間存在相關性。 請注意,在假設因子完全不相關的情況下使用 Varimax 旋轉。 我們將使用“普通最小二乘/最小二乘”因式分解(fm = “minres”),因為眾所周知,它可以在不假設多元正態分佈的情況下提供類似於“最大似然”的結果,並通過像主軸一樣的迭代特徵分解得出解。
運行以下命令開始分析。
[代碼語言=“r”]三因素<-fa(data,nfactors = 3, rotate = “oblimin”,fm=”minres”) print(threefactor) [/code]
這是顯示因子和載荷的輸出:
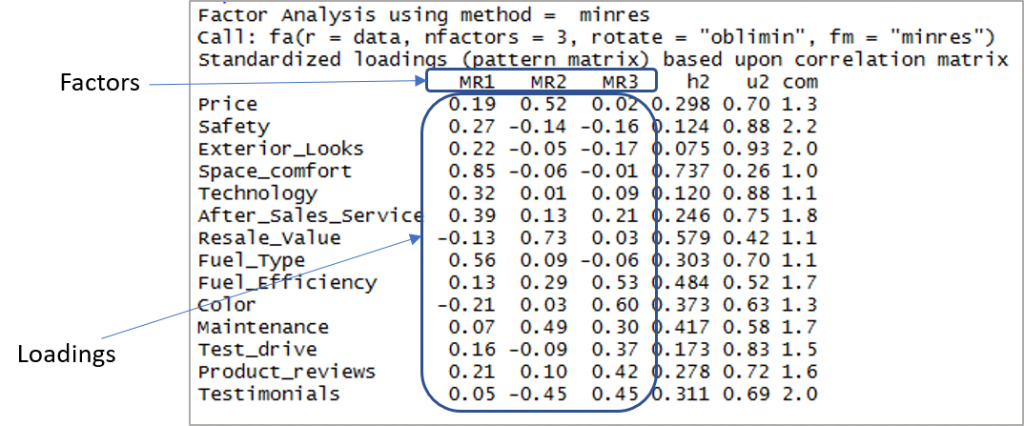
現在我們需要考慮超過 0.3 的載荷,而不是超過一個因素的載荷。 請注意,這裡可以接受負值。 因此,讓我們首先建立分界線以提高可見性。
[代碼語言=“r”] print(threefactor$loadings,cutoff = 0.3) [/code]
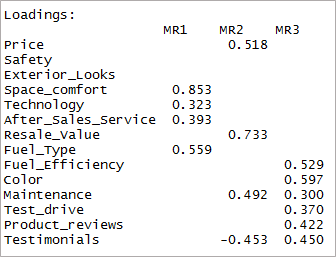
如您所見,兩個變量變得微不足道,另外兩個變量具有雙重加載。 接下來,我們將考慮“4”因素。
[代碼語言=“r”]四因素<-fa(data,nfactors = 4, rotate = “oblimin”,fm=”minres”) print(fourfactor$loadings,cutoff = 0.3) [/code]
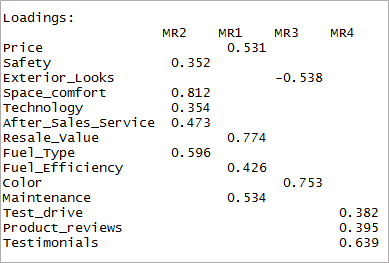
我們可以看到它只導致單次加載。 這被稱為簡單結構。
點擊以下查看因子映射。
[代碼語言=“r”] fa.diagram(fourfactor) [/code]
充分性測試
現在我們已經實現了一個簡單的結構,是時候驗證我們的模型了。 讓我們看一下因子分析輸出以繼續。

根表示殘差平方 (RMSR) 為 0.05。 這是可以接受的,因為這個值應該更接近於 0。接下來,我們應該檢查 RMSEA(近似的均方根誤差)指數。 它的值 0.001 表明模型擬合良好,因為它低於 0.05。 最後,Tucker-Lewis 指數 (TLI) 為 0.93——考慮到它超過 0.9,這是一個可接受的值。
命名因素

在確定因素的充分性之後,是時候為因素命名了。 這是分析的理論方面,我們根據可變載荷形成因子。 在這種情況下,這是如何創建因子的。
結論
在本 r 分析教程中,我們討論了 EFA(R 中的探索性因子分析)的基本思想,涵蓋了並行分析和碎石圖解釋。 然後我們轉移到 R 中的因子分析以實現簡單的結構並對其進行驗證以確保模型的充分性。 最後從變量中得出因素的名稱。 現在繼續,嘗試一下,並將您的發現發佈在評論部分。