
市集之聲
已發表: 2024-04-24這篇關於遺留系統現代化的文章是我最近在面向軟體公司的 AWS 資料高峰會上發表的演講的姊妹篇,內容是透過利用我們的最佳實踐從資料中創造價值,以確保機器學習專案的成功。 如果您願意,可以直接跳到底部觀看。
讓我們面對現實:軟體寫起來比維護起來容易。 這就是為什麼我們作為軟體工程師更喜歡“把它撕下來並重新開始”,而不是試圖理解另一個開發人員(或我們過去的自己)的想法。 我們似乎集體忘記了「程式必須編寫供人閱讀,並且只是順便供機器執行」。
你知道這是真的——我們都必須費盡心力地追溯一鍋意大利麵條式的代碼和薄薄的、舊世界風格的抽象,挖掘程序的核心內容,結果卻發現除了盤子底部的一團糟之外什麼也沒有。
人們很容易大喊“WTF”並責怪以前的開發人員,但事實往往更加複雜。 我們看不到未來,因此當我們設計一個全新的系統時,不可能了解需求、技術或業務目標將如何成長。 因此,隨著系統範圍的擴大以及業務對系統的依賴,系統可能會變得不可讀。 這有點自相矛盾:較舊、難以維護的系統往往提供最大的價值。 他們很難工作,因為他們與公司一起成長,也很可怕,因為打破它可能是一場災難。
這就是我要提醒你的地方:如果你喜歡困難的、有回報的問題…那就試試看。 採用您擁有的最舊的系統並使其可維護。 你知道我正在談論的那個——沒有人會「擁有」的那個。 其他部門依賴但工程師討厭的那個。 您必須先修補 Log4Shell 的那個。 做吧。 我賭你。
我最近有這樣的機會更新 Bazaarvoice 已有十年歷史的機器學習系統。 從表面上看,這聽起來並不令人興奮:這東西甚至沒有神經網路! 誰在乎! 嗯……這很重要。 該系統幾乎處理 Bazaarvoice 收到的所有用戶生成的產品評論(每月近 900 萬條),並對機器學習模型進行 9000 萬次推理調用。 是的-9000 萬次推論! 規模很大,我迫不及待想潛入其中。
在這篇文章中,我將分享如何透過重新架構(而不是重寫)對遺留系統進行現代化改造,使我們能夠使其具有可擴展性和成本效益,而無需刪除所有程式碼並重新開始。 由此產生的系統是無伺服器、容器化且可維護的,同時將我們的託管成本降低了近 80%。
什麼是遺留系統?
遺留系統是指仍在運作的老化運算軟體和/或硬體。 雖然它仍然可以實現其最初的目的,但缺乏未來成長的可擴展性。
舊的遺留系統
首先,讓我們來看看我們正在處理的事情。 我的團隊正在更新的舊系統負責管理所有 Bazaarvoice 的使用者生成內容。 具體來說,它確定每條內容是否適合我們客戶的網站。

這聽起來很簡單——消除仇恨言論、粗俗語言或招攬等明顯的違規行為——但在實踐中,情況要微妙得多。 每個客戶對於他們認為合適的東西都有獨特的要求。 例如,啤酒品牌希望討論酒精問題,但兒童品牌可能不會。 當我們加入新客戶時,我們會捕獲這些特定於客戶的選項,並且我們的客戶服務團隊將它們編碼到管理資料庫中。
為了增加一些複雜性,我們也對一部分內容進行採樣,由人工審核員進行審核。 這使我們能夠不斷衡量模型的性能並發現建立更多模型的機會。
我們遺留系統的完整架構如下:
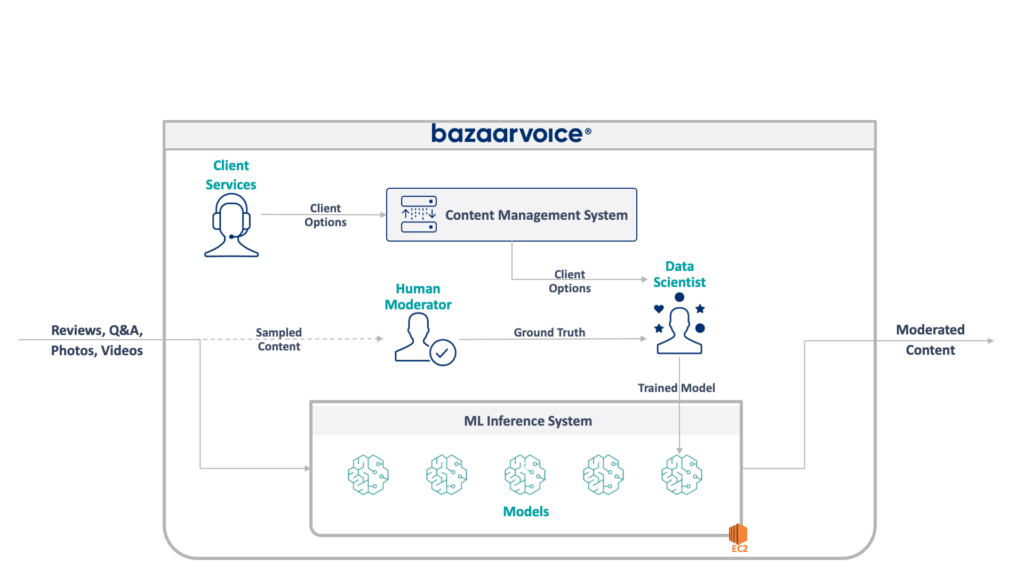
該系統有一些嚴重的缺點。 具體來說,所有模型都託管在單一 EC2 執行個體上。 這並不是由於糟糕的工程設計,而是由於最初的程式設計師無法預見公司所需的規模。 沒有人想到它會成長到如此程度。
此外,該系統還遭到了開發人員的拒絕:它是用 Scala 編寫的,很少有工程師能理解。 因此,它經常被忽視,因為沒有人願意碰它。
結果,系統繼續以持續成長的方式成長。 一旦我們開始重新建置它,它就在單一 x1e.8xlarge 實例上運行。 這個東西有近 1 TB 的內存,每月運行成本約為 5,000 美元(未預留)。 不過,別擔心,我們剛剛推出了第二個用於冗餘的產品和第三個用於品質檢查的產品。
該系統的運作成本很高,失敗的風險很高(一個錯誤的模型可能會導致整個服務癱瘓)。 此外,程式碼庫尚未積極開發,因此與現代資料科學套件相比明顯過時,並且不遵循我們用 Scala 編寫的服務的標準實踐。
新系統
在重新設計這個系統時,我們有一個明確的目標:使其可擴展。 降低營運成本是次要目標,簡化模型和程式碼管理也是。
我們提出的新設計如下圖所示:

我們解決所有這些問題的方法是將每個機器學習模型放在一個隔離的 SageMaker Serverless 端點上。 與 AWS Lambda 函數一樣,無伺服器端點在不使用時會關閉,為我們節省不常用模型的執行時間成本。 它們還可以快速擴展以響應流量的增加。

此外,我們將客戶端選項公開給單一微服務,該微服務將內容路由到適當的模型。 這是我們必須編寫的大部分新程式碼:一個易於維護的小型 API,可以讓我們的資料科學家更輕鬆地更新和部署新模型。
這種方法有以下好處:
- 將實現價值的時間縮短了 6 倍以上。 具體來說,將流量路由到現有模型是即時的,並且部署新模型可以在 5 分鐘內完成,而不是 30 分鐘
- 規模無限——我們目前有 400 個模型,但計劃擴展到數千個,以繼續增加我們可以自動調節的內容量
- 遷移 EC2 後成本降低了 82%,因為功能在不使用時關閉,而且我們不會為未充分利用的頂級機器付費
然而,簡單地設計一個理想的架構並不是重建遺留系統真正有趣的困難部分——您必須遷移到它。
我們遷移中的第一個挑戰是弄清楚如何將 Java WEKA 模型遷移到 SageMaker 上運行,更不用說 SageMaker Serverless 了。
幸運的是,SageMaker 在 Docker 容器中部署模型,因此至少我們可以凍結 Java 和依賴項版本以匹配我們的舊程式碼。 這將有助於確保新系統中託管的模型返回與舊系統相同的結果。

為了讓容器與 SageMaker 相容,您所需要做的就是實作一些特定的 HTTP 端點:
-
POST /invocation— 接受輸入、執行推理並傳回結果。 -
GET /ping— 如果 JVM 伺服器正常則回傳 200
(我們選擇忽略 BYO 多模型容器和 SageMaker 推理工具包周圍的所有問題。)
圍繞 com.sun.net.httpserver.HttpServer 進行一些快速抽象,我們就可以開始了。
你知道嗎? 這其實很有趣。 擺弄 Docker 容器並將已有 10 年歷史的東西強行引入 SageMaker Serverless 中,有一點修補的感覺。 當我們讓它工作時,這是非常令人興奮的——特別是當我們使用遺留系統程式碼在新的 sbt 堆疊而不是 Maven 中建置它時。
新的 sbt 堆疊使其易於使用,容器化確保我們在 SageMaker 環境中運行時可以獲得正確的行為。
遷移到新系統
因此,我們將模型放在容器中,並且可以將它們部署到 SageMaker——差不多完成了,對吧? 不完全的。
遷移到新架構的慘痛教訓是,您必須建立三倍於實際系統的資料才能支援遷移。 除了新系統之外,我們還必須建置:
- 舊系統中的資料擷取管道用於記錄模型的輸入和輸出。 我們用這些來確認新系統會回傳相同的結果
- 新系統中的資料處理管道用於計算結果並與舊系統中的資料進行比較。 這涉及使用 Datadog 進行大量測量,並且需要在發現差異時提供重播資料的能力
- 完整的模型部署系統,以避免影響舊系統的使用者(只需將模型上傳到 S3)。 我們知道我們最終希望將它們轉移到 API,但對於初始版本,我們需要無縫地做到這一點
所有這些都是一次性程式碼,我們知道一旦完成所有使用者的遷移就可以丟棄,但我們仍然必須建造它並確保新系統的輸出與舊系統相符。
預先期待這一點。
雖然在這個專案上建立遷移工具和系統確實花費了我們 60% 以上的工程時間,但這也是一個有趣的體驗。 單元測試變得更像數據科學實驗:我們編寫了整個套件以確保我們的輸出完全匹配。 正是這種不同的思維方式讓工作變得更加有趣。 如果你願意的話,這是我們正常框框之外的一步。
透過重新架構實現遺留系統的現代化
下次當您想從程式碼開始重建系統時,我想鼓勵您嘗試遷移架構而不是程式碼。 您會發現有趣且有益的技術挑戰,並且可能比調試新程式碼的意外邊緣情況更喜歡它。
想了解更多嗎? 請觀看下面我在 AWS 資料高峰會上發表的演講,其中深入探討了 MLOps 方面的問題。