
網路爬蟲如何運作
已發表: 2023-12-05網路爬蟲在對網路上存在的大量資訊進行索引和結構化方面發揮著至關重要的作用。 他們的角色包括遍歷網頁、收集資料並使其可搜尋。 本文深入研究網路爬蟲的機制,深入了解其組件、操作和不同類別。 讓我們深入了解網路爬蟲的世界吧!
什麼是網路爬蟲
網路爬蟲,稱為蜘蛛或機器人,是一種自動化腳本或程序,旨在有條不紊地瀏覽網路網站。 它以種子 URL 開始,然後沿著 HTML 連結訪問其他網頁,形成一個可以索引和分析的互連頁面網路。
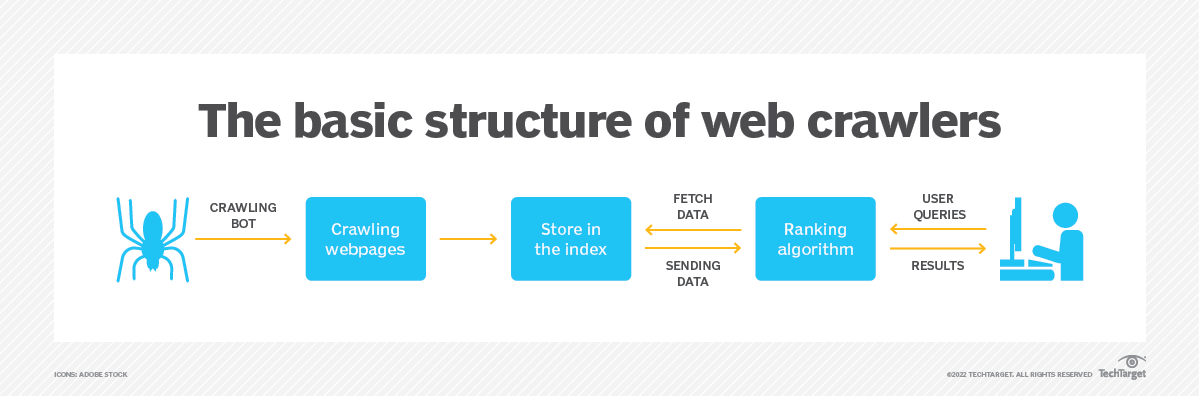
圖片來源:https://www.techtarget.com/
網路爬蟲的目的
網路爬蟲的主要目標是從網頁收集資訊並產生可搜尋索引以進行有效檢索。 Google、Bing 和 Yahoo 等主要搜尋引擎嚴重依賴網路爬蟲來建立搜尋資料庫。 透過網路內容的系統檢查,搜尋引擎可以提供使用者相關且最新的搜尋結果。
值得注意的是,網路爬蟲的應用範圍超出了搜尋引擎的範圍。 它們也被各種組織用於資料探勘、內容聚合、網站監控甚至網路安全等任務。
網路爬蟲的組成部分
網路爬蟲由多個組件組成,這些組件協同工作以實現其目標。 以下是網路爬蟲的關鍵組件:
- URL Frontier:此元件管理等待抓取的 URL 集合。 它根據相關性、新鮮度或網站重要性等因素對 URL 進行優先排序。
- 下載器:下載器根據URL前沿提供的URL來擷取網頁。 它將 HTTP 請求傳送到 Web 伺服器、接收回應並保存所取得的 Web 內容以供進一步處理。
- 解析器:解析器處理下載的網頁,提取有用的信息,例如連結、文字、圖像和元資料。 它分析頁面的結構並提取要新增到 URL 前緣的連結頁面的 URL。
- 資料儲存:資料儲存元件儲存收集到的數據,包括網頁、擷取的資訊和索引資料。 該資料可以以各種格式存儲,例如資料庫或分散式檔案系統。
網路爬蟲如何運作
在了解了所涉及的元素後,讓我們深入研究闡明網路爬蟲功能的順序過程:

- 種子 URL:爬網程式從種子 URL 開始,該種子可以是任何網頁或 URL 清單。 該 URL 將會新增至 URL 前緣以啟動爬網過程。
- 抓取:爬蟲從URL邊界選擇一個URL,並向對應的Web伺服器發送HTTP請求。 伺服器回應網頁內容,然後由下載器元件取得。
- 解析:解析器處理取得的網頁,提取相關訊息,例如連結、文字和元資料。 它還識別頁面上找到的新 URL 並將其新增至 URL 邊界。
- 連結分析:爬蟲根據相關性、新鮮度或重要性等特定標準對提取的 URL 進行優先排序並將其添加到 URL 前沿。 這有助於確定爬網程序存取和爬網頁面的順序。
- 重複流程:爬蟲透過從 URL 前緣選擇 URL、取得其 Web 內容、解析頁面並提取更多 URL 來繼續此過程。 重複此過程,直到沒有更多的 URL 可供爬網,或達到預先定義的限制。
- 資料儲存:在整個爬取過程中,採集到的資料都儲存在資料儲存元件中。 該數據稍後可用於索引、分析或其他目的。
網路爬蟲的類型
網路爬蟲有不同的變體並具有特定的用例。 以下是一些常用的網路爬蟲類型:
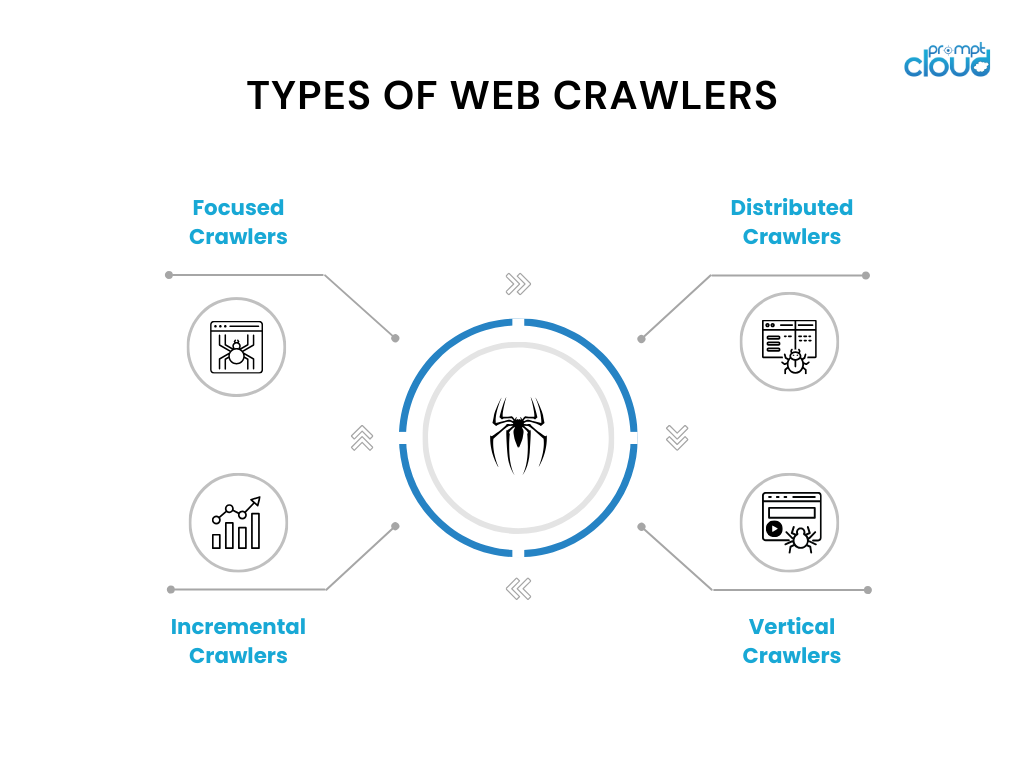
- 聚焦爬蟲:這些爬蟲在特定網域或主題內運行,並爬行與該網域相關的頁面。 例如用於新聞網站或研究論文的主題爬蟲。
- 增量爬蟲:增量爬蟲專注於爬行自上次爬行以來的新內容或更新內容。 他們利用時間戳分析或更改檢測演算法等技術來識別和抓取修改的頁面。
- 分散式爬蟲:在分散式爬蟲中,多個爬蟲實例並行運行,分擔爬取大量頁面的工作量。 這種方法可以加快抓取速度並提高可擴展性。
- 垂直爬蟲:垂直爬蟲針對網頁中特定類型的內容或數據,例如圖像、影片或產品資訊。 它們旨在為專門的搜尋引擎提取和索引特定類型的資料。
您應該多久抓取一次網頁?
抓取網頁的頻率取決於幾個因素,包括網站的大小和更新頻率、頁面的重要性以及可用資源。 某些網站可能需要頻繁爬網以確保將最新資訊編入索引,而其他網站可能不那麼頻繁地爬網。
對於高流量網站或內容快速變化的網站,更頻繁的爬網對於維護最新資訊至關重要。 另一方面,較小的網站或更新不頻繁的頁面可以不那麼頻繁地爬行,從而減少所需的工作量和資源。
內部網路爬蟲與網路爬蟲工具
在考慮創建網路爬蟲時,評估複雜性、可擴展性和必要的資源至關重要。 從頭開始建立爬蟲可能是一項耗時的工作,包括管理並發、監督分散式系統和解決基礎設施障礙等活動。 另一方面,選擇網路爬行工具或框架可以提供更快、更有效的解決方案。
或者,使用網路爬蟲工具或框架可以提供更快、更有效的解決方案。 這些工具提供可自訂的爬行規則、資料提取功能和資料儲存選項等功能。 透過利用現有工具,開發人員可以專注於他們的特定需求,例如數據分析或與其他系統的整合。
然而,考慮與使用第三方工具相關的限制和成本至關重要,例如客製化限制、資料所有權和潛在定價模型。
結論
搜尋引擎嚴重依賴網路爬蟲,網路爬蟲有助於對網路上存在的大量資訊進行整理和編目。 掌握網路爬蟲的機制、組件和不同類別可以更深入地了解支撐這一基本過程的複雜技術。
無論是選擇從頭開始建立網路爬蟲還是利用現有的網路爬蟲工具,都必須採用符合您特定需求的方法。 這需要考慮可擴展性、複雜性和您可以使用的資源等因素。 透過考慮這些因素,您可以有效地利用網路爬行來收集和分析有價值的數據,從而推動您的業務或研究工作向前發展。
在 PromptCloud,我們專注於網路資料擷取,從公開可用的線上資源中獲取資料。 請透過sales@promptcloud.com與我們聯繫