
如何阻止人工智慧抓取您的內容
已發表: 2023-10-24人工智慧生成工具(例如 Google Bard 和 Bing Chat)是根據包括網路在內的許多內容來源建構的。 令許多人感到驚訝的是,搜尋引擎一直在悄悄地根據他們在爬行傳統網路搜尋時找到的所有內容來訓練他們的人工智慧模型。
必應和Google現已宣布阻止內容用於人工智慧訓練的方法,同時保留網路搜尋索引。
那麼,你該阻止人工智慧嗎?你該如何阻止?
- 你應該阻止人工智慧嗎?
- 如何阻止人工智慧機器人?
- 如何阻止 Bing 的 AI
- 如何阻止谷歌的人工智慧
- 如何阻止 ChatGPT
- 測試
你應該阻止人工智慧嗎?
製造自己產品的公司可能會認為將其內容包含在人工智慧模型中是有好處的。 技術規格或產品支援等資訊可能有助於銷售並降低客戶支援成本。
但對許多其他線上企業來說,內容就是他們的產品。 人們擔心,投入在內容創作上的精力將被用來改進大型科技公司擁有的人工智慧產品,而不會以流量的形式提供任何價值。
谷歌和必應正在嘗試尋找方法來信任來源並提供一些推薦流量,但它可能比傳統的網路搜尋要少,而且更有可能是交易性的而不是資訊性的搜尋查詢。
需要注意的是,阻止這些 AI 的內容不會影響爬行行為。 谷歌表示,“robots.txt 用戶代理令牌用於控制能力。” 機器人將正常抓取您的網站以建立搜尋索引。
如果搜尋引擎已經被阻止抓取某些頁面,則無需專門針對 AI 來阻止它們。
如何阻止人工智慧機器人?
目前可以使用大多數 SEO 熟悉的方法、robots.txt 檔案和頁面層級 robots 指令來阻止 Google、Bing 和 ChatGPT。
Google 和 ChatGPT 選擇了 robots.txt 方法,該方法可讓您指定 URL 模式,而 Bing 選擇使用套用於各個頁面的 robots 指令。
robots.txt 的優點是可以輕鬆地在一個地方為整個網站進行設定。 與頁面級機器人指令相比,哪些 URL 被阻止是非常透明的,必須透過取得每個頁面進行測試。
如何阻止 Bing 的 AI
Bing 會尋找 nocache 或 noarchive robots 指令,這些指令可以作為元標記或 X-Robots-Tag 回應標頭加入到頁面中。
Nocache 將允許在訓練 Microsoft 的 AI 模型時僅使用 URL、標題和片段將頁麵包含在 Bing Chat 答案中。
Noarchive 不允許將頁麵包含在 Bing Chat 中,並且不會使用任何內容來訓練 Microsoft 的 AI 模型。
如果頁面同時具有 Nocache 和 Noarchive,則限制較少的 Nocache 將優先。
「 robots 」標記會將指令套用至所有爬蟲。 這包括 Google,它將阻止帶有快取連結的頁面出現在搜尋結果中。
<元名稱=“機器人”內容=“noarchive”>
您可以使用更具體的「 bingbot 」或「 msnbot 」標記來避免影響其他搜尋引擎。
<元名稱=”bingbot”內容=”nocache”>
如何阻止谷歌的人工智慧
Google 選擇了 robots.txt 方法,該方法可讓您指定 URL 模式來符合您不想在 Bard 及其 Vertex API 等效項中使用的頁面。 它目前不適用於搜尋生成體驗 (SGE)。
它們將與 Google 擴充功能的用戶代理令牌進行匹配。 令牌的大小寫並不重要。
使用者代理:Google 擴充
不允許: /
如果沒有專門針對 google 擴充令牌的規則區塊,它將與通配符令牌 (*) 相符。
用戶代理: *
不允許: /
如果您有針對 Googlebot 的特定規則區塊和單獨的通配符區塊,請務必小心。 Google-extend 將匹配通配符區塊,而不是 Googlebot 區塊。
使用者代理:Googlebot
允許: /
用戶代理: *
不允許: /
為了更精確,您可以在規則區塊之前列出多個使用者代理程式。
使用者代理:Google 擴充
使用者代理:Googlebot
允許: /

用戶代理: *
不允許: /
如何阻止 ChatGPT
ChatGPT 也選擇了 robots.txt 方法。
Chat GPT 有兩種不同的使用者代理令牌,ChatGPT-User 用於代表 ChatGPT 使用者進行查詢,GPTBot 是 OpenAI 的網路爬蟲,用於建立模型。
目前,選擇退出系統對兩個使用者代理一視同仁,因此任何不允許一個代理的 robots.txt 都將涵蓋這兩個代理程式。 這將來可能會改變,因此我們建議單獨阻止它們。
使用者代理:GPTBot
使用者代理:ChatGPT-User
不允許: /
測試
如果您封鎖整個網站,測試很簡單。
要檢查 Google 和 ChatGPT 是否被阻止,您需要查看您的 robots.txt 是否對您要阻止的機器人有禁止一切規則。
使用者代理:Google 擴充
用戶代理:GPTbot
不允許: /
如果您只想封鎖某些 URL,則可能需要一組更複雜的 robots.txt 指令。 您可以考慮測試一些您預計會被封鎖和未被封鎖的 URL。
Tomo 是我們的免費 robots.txt 工具,可以幫助您測試 robots.txt 中是否封鎖了特定網址。 您可以以 URL 清單的形式定義測試,以及每個 URL 的預期禁止狀態。
可以使用 Google-Extended、GPTBot 和 ChatGPT-User 使用者代理令牌對其進行配置,以顯示每個 URL 被阻止,以及是否與預期的測試結果相符。
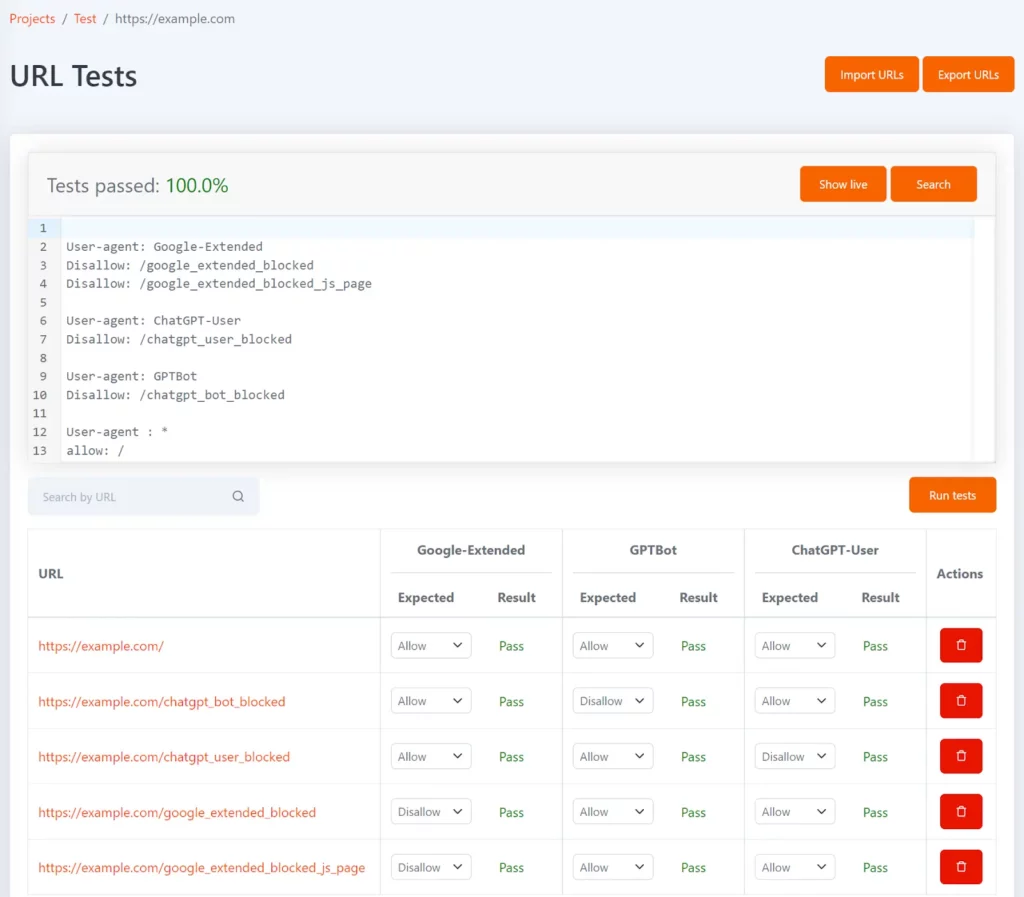
每當您的 robots.txt 檔案更新時,測試都會重新執行,如果結果與預期不符,您將會收到通知。
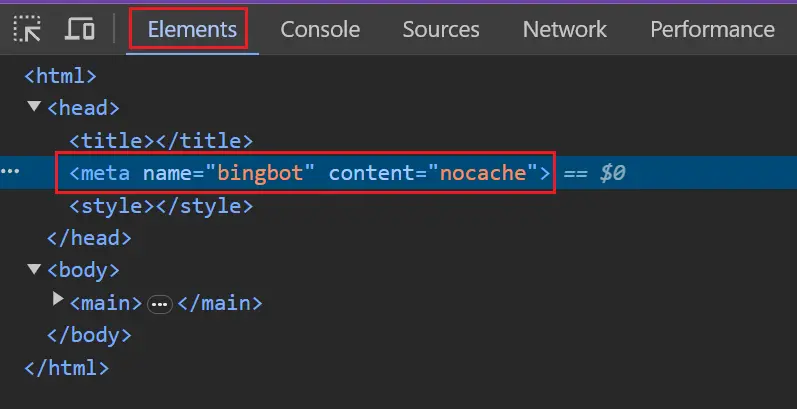
要測試 Bing 是否被阻止,您可以在瀏覽器中檢查關鍵頁面範本並確認它具有 robots 標記。
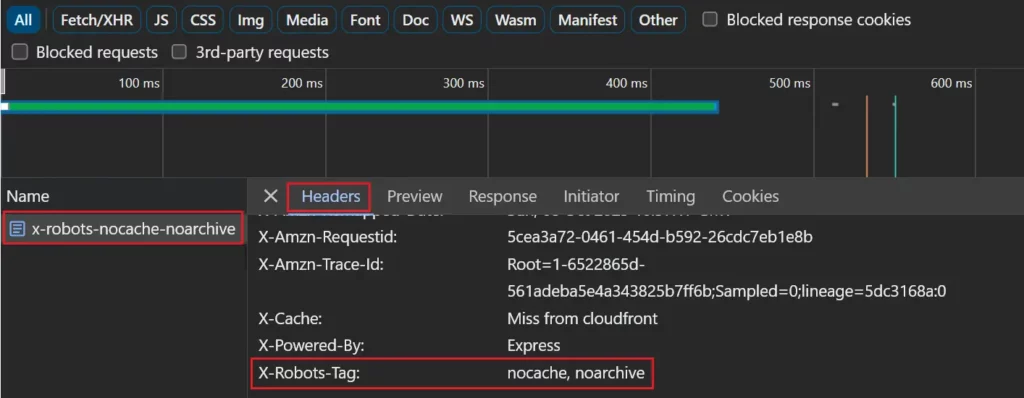
如果您使用 X-Robots-Tag 回應標頭,則可以透過選擇網路請求清單中的頁面並查看「標頭」選項卡,在網路標籤中看到它。
如果您封鎖一組特定的頁面,測試將會更加複雜,但是有一些工具可以提供協助。
Lumar 爬蟲現在也會自動報告 Google 和 Bing 的 AI 被封鎖的所有頁面。
您需要額外的技術支援嗎? 了解有關Semetrical 技術產品的更多資訊或聯絡以獲取更多資訊!