
掌握網頁擷取工具:擷取線上資料的初學者指南
已發表: 2024-04-09什麼是網頁抓取工具?
網頁抓取工具是一種旨在從網站中提取資料的工具。 它模擬人類導航來收集特定內容。 初學者經常利用這些爬蟲來完成各種任務,包括市場研究、價格監控和機器學習專案的資料編譯。
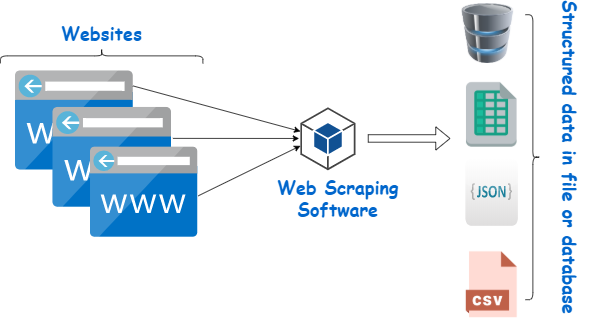
圖片來源:https://www.webharvy.com/articles/what-is-web-scraping.html
- 易於使用:它們用戶友好,允許具有最低技術技能的個人有效地捕獲網路數據。
- 效率:爬蟲可以快速收集大量數據,遠超過手動數據收集工作。
- 準確性:自動抓取降低了人為錯誤的風險,並提高了資料準確性。
- 成本效益:無需手動輸入,節省人力成本和時間。
了解網頁抓取工具的功能對於任何想要利用網路資料力量的人來說至關重要。
使用 Python 建立簡單的網頁抓取工具
要開始用 Python 建立網頁抓取工具,需要安裝某些函式庫,即向網頁發出 HTTP 請求的 requests,以及用於解析 HTML 和 XML 文件的 bs4 的 BeautifulSoup。
- 採集工具:
- 庫:使用請求來取得網頁並使用 BeautifulSoup 來解析下載的 HTML 內容。
- 定位網頁:
- 定義包含我們要抓取的資料的網頁的 URL。
- 下載內容:
- 使用請求,下載網頁的 HTML 程式碼。
- 解析 HTML:
- BeautifulSoup 會將下載的 HTML 轉換為結構化格式,以便於導覽。
- 擷取資料:
- 識別包含我們所需資訊的特定 HTML 標籤(例如,<div> 標籤內的產品標題)。
- 使用 BeautifulSoup 方法,提取並處理您需要的資料。
請記住定位與您要抓取的資訊相關的特定 HTML 元素。
抓取網頁的逐步過程
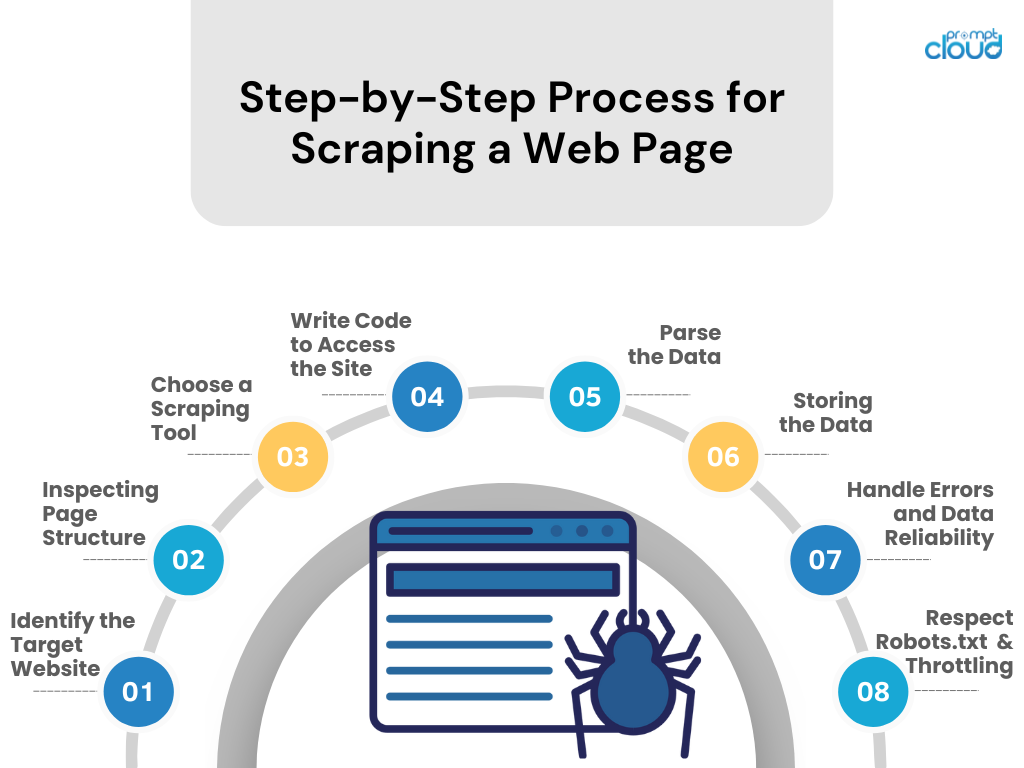
- 確定目標網站
研究您想要抓取的網站。 確保這樣做是合法和道德的。 - 檢查頁面結構
使用瀏覽器的開發人員工具檢查 HTML 結構、CSS 選擇器和 JavaScript 驅動的內容。 - 選擇一個抓取工具
選擇您熟悉的程式語言的工具或函式庫(例如,Python 的 BeautifulSoup 或 Scrapy)。 - 編寫程式碼來訪問該站點
編寫一個腳本,使用 API 呼叫(如果可用)或 HTTP 請求從網站請求資料。 - 解析數據
透過解析HTML/CSS/JavaScript從網頁中擷取相關資料。 - 儲存數據
以結構化格式(例如 CSV、JSON)保存抓取的數據,或直接儲存到資料庫。 - 處理錯誤和數據可靠性
實作錯誤處理來管理請求失敗並維護資料完整性。 - 尊重 Robots.txt 和限制
遵守網站的 robots.txt 檔案規則,並透過控制請求速率避免伺服器不堪重負。
選擇適合您需求的理想網頁抓取工具
在抓取網頁時,選擇符合您的熟練程度和目標的工具至關重要。 初學者應考慮:

- 易於使用:選擇具有視覺輔助和清晰文件的直覺工具。
- 資料需求:評估目標資料的結構和複雜性,以確定是否需要簡單的擴充或強大的軟體。
- 預算:權衡成本與功能; 許多有效的抓取工具都提供免費套餐。
- 客製化:確保工具適合特定的抓取需求。
- 支援:訪問有用的用戶社群有助於排除故障和改進。
明智地選擇,以獲得順利的刮擦旅程。
優化網頁抓取工具的提示和技巧
- 使用 Python 中的 BeautifulSoup 或 Lxml 等高效能解析函式庫來加快 HTML 處理速度。
- 實施快取以避免重新下載頁面並減少伺服器負載。
- 尊重 robots.txt 檔案並使用速率限制來防止被目標網站禁止。
- 輪換用戶代理程式和代理伺服器來模仿人類行為並避免檢測。
- 在非尖峰時段安排抓取工具,以盡量減少對網站效能的影響。
- 如果可用,請選擇 API 端點,因為它們提供結構化資料並且通常更有效率。
- 透過選擇性查詢來避免抓取不必要的數據,從而減少所需的頻寬和儲存。
- 定期更新您的抓取工具以適應網站結構的變化並保持資料完整性。
處理網頁抓取中的常見問題和故障排除
在使用網頁抓取工具時,初學者可能會遇到幾個常見問題:
- 選擇器問題:確保選擇器與網頁的目前結構相符。 瀏覽器開發人員工具等工具可以幫助識別正確的選擇器。
- 動態內容:某些網頁使用 JavaScript 動態載入內容。 在這種情況下,請考慮使用無頭瀏覽器或渲染 JavaScript 的工具。
- 封鎖的請求:網站可能會封鎖抓取工具。 採用輪換用戶代理、使用代理和尊重 robots.txt 等策略來減輕阻塞。
- 資料格式問題:擷取的資料可能需要清理或格式化。 使用正規表示式和字串操作來標準化資料。
請記住查閱文件和社區論壇以獲取具體的故障排除指南。
結論
初學者現在可以透過網頁抓取工具方便地從網路收集數據,使研究和分析更有效率。 在考慮法律和道德方面的同時了解正確的方法可以讓用戶充分利用網路抓取的潛力。 遵循這些指南可以順利介紹網頁抓取,其中充滿了寶貴的見解和明智的決策。
常見問題:
什麼是抓取頁面?
網路抓取,也稱為資料抓取或網路收集,包括使用模仿人類導航行為的電腦程式自動從網站提取資料。 使用網頁抓取工具,可以快速對大量資訊進行排序,只專注於重要部分,而不是手動編譯它們。
企業將網頁抓取應用於檢查成本、管理聲譽、分析趨勢和執行競爭分析等功能。 實施網頁抓取專案需要驗證所造訪的網站是否批准所有相關 robots.txt 和 no-follow 協議的操作和遵守。
如何抓取整個頁面?
要抓取整個網頁,通常需要兩個元件:一種在網頁中定位所需資料的方法,以及將該資料保存在其他地方的機制。 許多程式語言都支援網頁抓取,尤其是 Python 和 JavaScript。
兩者都存在各種開源函式庫,進一步簡化了流程。 Python 開發人員中的一些流行選擇包括 BeautifulSoup、Requests、LXML 和 Scrapy。 或者,ParseHub 和 Octoparse 等商業平台使技術水平較低的人員能夠直觀地建立複雜的網路抓取工作流程。 安裝必要的函式庫並了解選擇 DOM 元素背後的基本概念後,首先確定目標網頁中感興趣的資料點。
利用瀏覽器開發人員工具檢查 HTML 標籤和屬性,然後將這些結果轉換為所選庫或平台支援的對應語法。 最後,指定輸出格式首選項(無論是 CSV、Excel、JSON、SQL 或其他選項)以及已儲存的資料所在的目標。
如何使用Google抓取工具?
與普遍看法相反,儘管 Google 提供了 API 和 SDK 來促進與多個產品的無縫集成,但它本身並不會直接提供公共網路抓取工具。 儘管如此,熟練的開發人員還是創建了基於 Google 核心技術的第三方解決方案,有效地擴展了本機功能以外的功能。 例如 SerpApi,它抽象化了 Google Search Console 的複雜方面,並提供了一個易於使用的介面,用於關鍵字排名追蹤、自然流量估計和反向連結探索。
雖然在技術上與傳統的網路抓取不同,但這些混合模型模糊了傳統定義的界線。 其他實例則展示了用於重建驅動Google 地圖平台、YouTube 資料API v3 或Google 購物服務的內部邏輯的逆向工程工作,產生的功能與原始對應項非常接近,儘管存在不同程度的合法性和可持續性風險。 最終,有抱負的網頁抓取者應該在選擇特定途徑之前探索不同的選擇並評估相對於特定要求的優點。
Facebook 抓取合法嗎?
正如 Facebook 開發者政策中所述,未經授權的網頁抓取行為明顯違反了其社群標準。 使用者同意不開發或執行旨在規避或超過指定 API 速率限制的應用程式、腳本或其他機制,也不得嘗試對網站或服務的任何方面進行破解、反編譯或逆向工程。 此外,它還強調了對資料保護和隱私的期望,在允許的環境之外共享個人識別資訊之前需要明確的用戶同意。
任何不遵守概述原則的行為都會引發不斷升級的紀律措施,從警告開始,根據嚴重程度逐步推進到限制存取或完全撤銷特權。 儘管為根據批准的漏洞賞金計劃開展工作的安全研究人員制定了例外情況,但普遍共識主張避免未經批准的 Facebook 抓取舉措,以避免不必要的複雜情況。 相反,請考慮尋求與平台認可的現行規範和慣例相容的替代方案。