
克服網頁抓取中的技術挑戰:專家解決方案
已發表: 2024-03-29網路抓取是一種伴隨著許多技術挑戰的做法,即使對於經驗豐富的資料探勘者也是如此。 它需要使用程式技術從網站獲取和檢索數據,由於網路技術的複雜性和多樣性,這並不總是那麼容易。
此外,許多網站都採取了保護措施來防止資料收集,這使得爬取者必須協商反爬取機制、動態內容和複雜的網站結構。
儘管快速獲取有用資訊的目標看似簡單,但要實現這一目標需要克服幾個巨大的障礙,需要強大的分析和技術能力。
處理動態內容
動態內容是指根據使用者操作或初始頁面視圖載入後更新的網頁訊息,通常會為網頁抓取工具帶來挑戰。
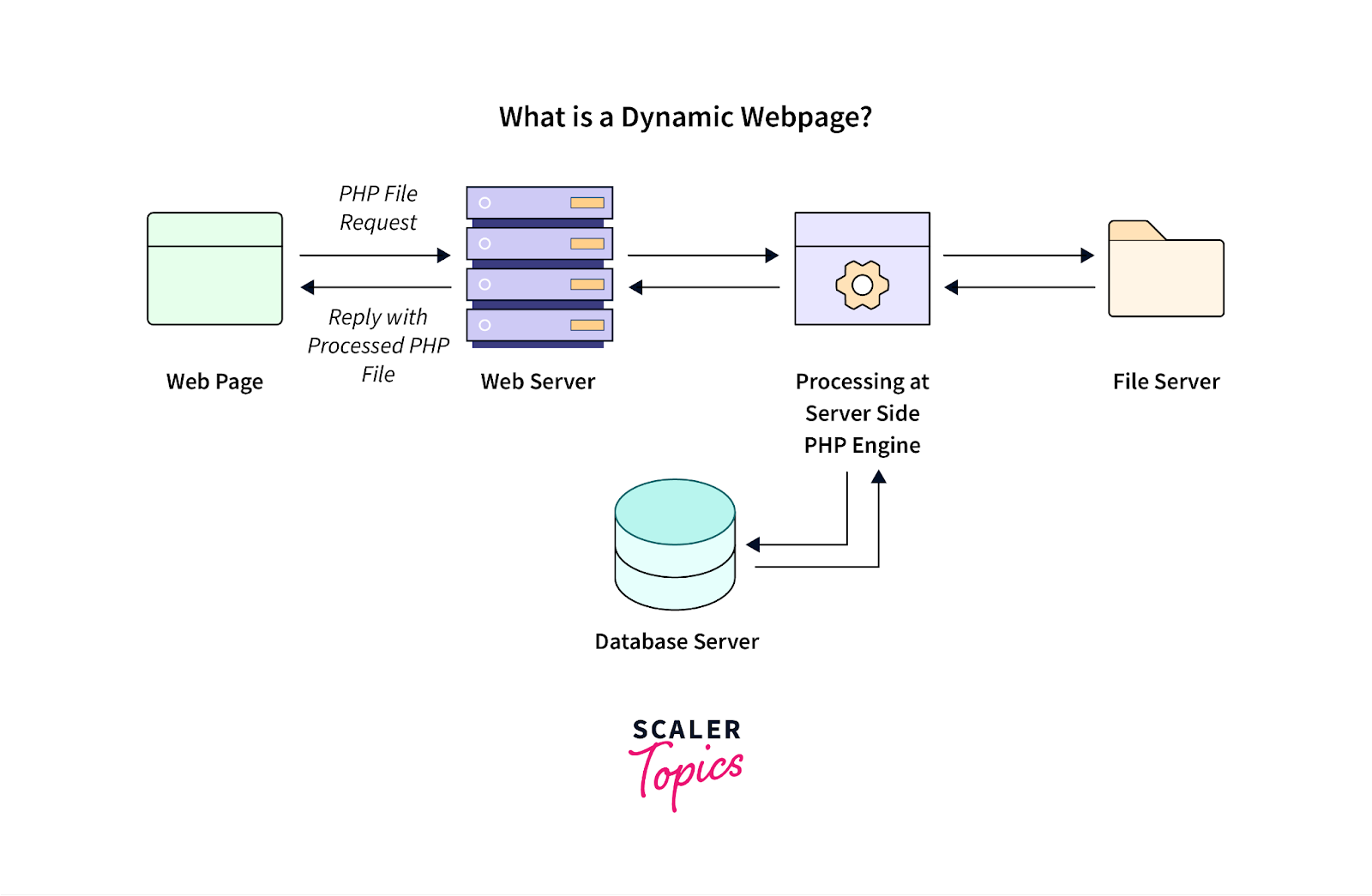
圖片來源:https://www.scaler.com/topics/php-tutorial/dynamic-website-in-php/
這種動態內容經常在使用 JavaScript 框架建立的當代 Web 應用程式中使用。 若要成功管理此類動態產生的內容並從中提取數據,請考慮以下最佳實踐:
- 考慮使用 Web 自動化工具,例如Selenium、Puppeteer或Playwright,它們使您的網頁抓取工具在網頁上的行為與真正使用者的行為類似。
- 如果網站利用WebSocket或AJAX處理技術動態載入內容,請實作這些技術。
- 透過在抓取程式碼中使用明確等待來等待元素加載,以確保內容在嘗試抓取之前已完全加載。
- 探索使用無頭瀏覽器,它可以執行 JavaScript 並呈現整個頁面,包括動態載入的內容。
透過掌握這些策略,抓取工具甚至可以從最具互動性和動態變化的網站中有效地提取資料。
防刮技術
網路開發人員通常會採取措施防止未經批准的資料抓取,以保護其網站。 這些措施可能會為網路爬蟲帶來重大挑戰。 以下是使用反抓取技術的幾種方法和策略:

圖片來源:https://kinsta.com/knowledgebase/what-is-web-scraping/
- 動態分解:網站可能會動態產生內容,使預測 URL 或 HTML 結構變得更加困難。 利用可以執行 JavaScript 和處理 AJAX 請求的工具。
- IP 封鎖:來自相同 IP 的頻繁請求可能會導致封鎖。 使用代理伺服器池來輪換 IP 並模仿人流模式。
- 驗證碼:這些驗證碼旨在區分人類和機器人。 應用驗證碼解決服務或選擇手動輸入(如果可行)。
- 速率限制:為了避免觸發速率限制,請限制請求速率並在請求之間實現隨機延遲。
- 使用者代理:網站可能會阻止已知的抓取工具使用者代理程式。 輪換用戶代理以模仿不同的瀏覽器或設備。
克服這些挑戰需要一種複雜的方法,尊重網站的服務條款,同時有效地存取所需的資料。
處理驗證碼和蜜罐陷阱
網路抓取工具經常遇到旨在區分人類使用者和機器人的驗證碼挑戰。 克服這個問題需要:

- 利用利用人類或人工智慧能力的驗證碼解決服務。
- 實施延遲和隨機化請求來模仿人類行為。
對於蜜罐陷阱,用戶不可見,但會捕獲自動腳本:
- 仔細檢查網站的程式碼以避免與隱藏連結互動。
- 採用較不激進的抓取做法來保持在雷達之下。
開發人員必須在道德上平衡有效性與尊重網站條款和使用者體驗。
抓取效率和速度優化
網路抓取過程可以透過優化效率和速度來改進。 為了克服該領域的挑戰:
- 利用多線程允許同時提取數據,從而提高吞吐量。
- 利用無頭瀏覽器消除不必要的圖形內容加載,從而加快執行速度。
- 優化抓取程式碼以最小的延遲執行。
- 實施適當的請求限制,以防止 IP 禁止,同時保持穩定的速度。
- 快取靜態內容以避免重複下載,從而節省頻寬和時間。
- 採用非同步程式技術來優化網路 I/O 操作。
- 選擇高效率的選擇器和解析函式庫來減少 DOM 操作的開銷。
透過整合這些策略,網路抓取工具可以實現穩健的效能,同時最大限度地減少操作問題。
資料擷取和解析
網路抓取需要精確的資料擷取和解析,帶來了獨特的挑戰。 以下是解決這些問題的方法:
- 使用強大的函式庫,如 BeautifulSoup 或 Scrapy,它們可以處理各種 HTML 結構。
- 謹慎實施正規表示式以精確定位特定模式。
- 利用 Selenium 等瀏覽器自動化工具與 JavaScript 密集型網站進行交互,確保資料在提取之前呈現。
- 採用 XPath 或 CSS 選擇器來準確定位 DOM 中的資料元素。
- 透過識別和操作載入新內容的機制(例如,更新 URL 參數或處理 AJAX 呼叫)來處理分頁和無限滾動。
掌握網頁抓取的藝術
在資料驅動的世界中,網頁抓取是一項非常寶貴的技能。 克服從動態內容到機器人偵測等技術挑戰需要毅力和適應性。 成功的網頁抓取涉及以下方法的結合:
- 實施智慧爬行以尊重網站資源並在不被發現的情況下進行導航。
- 利用進階解析來處理動態內容,確保資料擷取對於變更具有穩健性。
- 策略性地使用驗證碼解析服務以在不中斷資料流的情況下保持存取。
- 周全地管理 IP 位址和請求標頭以掩蓋抓取活動。
- 透過定期更新解析器腳本來處理網站結構變化。
透過掌握這些技術,人們可以熟練地應對複雜的網路爬行並解鎖大量有價值的數據。
管理大型廢料項目
大型網路抓取專案需要強大的管理以確保效率和合規性。 與網頁抓取服務供應商合作具有以下幾個優勢:

將抓取專案委託給專業人員可以優化結果並最大程度地減少內部團隊的技術壓力。
常見問題解答
網頁抓取有哪些限制?
網路抓取面臨某些限制,在將其納入其營運之前必須考慮這些限制。 從法律上講,某些網站不允許透過條款和條件或 robots.txt 檔案進行抓取; 忽視這些限制可能會導致嚴重後果。
從技術上講,網站可以部署驗證碼、IP 攔截和蜜罐等反抓取措施,從而防止未經授權的存取。 由於動態渲染和頻繁更新的來源,提取的資料的準確性也可能成為一個問題。 最後,網頁抓取需要技術知識、資源投資和持續的努力——這帶來了挑戰,特別是對於非技術人員來說。
為什麼資料抓取是一個問題?
問題主要是在沒有必要的許可或道德行為的情況下進行資料抓取時出現的。 提取機密資訊違反了隱私規範,並違反了旨在保護個人利益的法規。
過度使用抓取會對目標伺服器帶來壓力,對效能和可用性產生負面影響。 由於受害方可能提起侵權訴訟,智慧財產權竊盜是非法抓取引起的另一個問題。
因此,在執行資料抓取任務時,遵守政策規定、維護道德標準並在必要時徵求同意仍然至關重要。
為什麼網頁抓取可能不準確?
網路抓取需要透過專門的軟體從網站自動提取數據,但由於各種因素,並不能保證完全準確。 例如,網站結構的修改可能會導致抓取工具發生故障或捕獲錯誤訊息。
此外,某些網站實施了驗證碼測試、IP 封鎖或 JavaScript 渲染等反抓取措施,導致資料遺失或扭曲。 有時,開發人員在創建過程中的疏忽也會導致結果不佳。
然而,與熟練的網頁抓取服務提供者合作可以提高精度,因為他們帶來了必要的專業知識和資產來建立有彈性和靈活的抓取器,即使網站佈局發生變化,也能夠保持高精度水平。 熟練的專家在實施之前仔細測試和驗證這些刮刀,確保整個提取過程的正確性。
網頁抓取很無聊嗎?
事實上,參與網頁抓取活動可能會很費力且要求很高,特別是對於那些缺乏編碼專業知識或對數位平台的理解的人來說。 此類任務需要編寫定製程式碼、糾正有缺陷的抓取工具、管理伺服器架構以及及時了解目標網站內發生的更改,所有這些都需要相當高的技術能力以及大量的時間投入。
考慮到監管合規性、頻寬管理和實施分散式運算系統,擴展過去的基本網路抓取工作變得越來越複雜。
相較之下,選擇專業的網頁抓取服務可以透過根據用戶特定需求設計的現成產品大大減輕相關負擔。 因此,客戶主要專注於利用收集到的數據,同時將收集物流留給由熟練的開發人員和IT 專家組成的專門團隊負責系統優化、資源分配和解決法律查詢,從而顯著減少與網路抓取計劃相關的整體乏味。