
Python 網路爬蟲 – 逐步教程
已發表: 2023-12-07網路爬蟲是資料收集和網路抓取領域中令人著迷的工具。 它們自動化了瀏覽網路以收集資料的過程,這些資料可用於各種目的,例如搜尋引擎索引、資料探勘或競爭分析。 在本教程中,我們將踏上使用 Python 建立基本網路爬蟲的資訊之旅,Python 是一種以其簡單性和處理網路資料的強大功能而聞名的語言。
Python 擁有豐富的函式庫生態系統,為開發網路爬蟲提供了一個優秀的平台。 無論您是初露頭角的開發人員、數據愛好者,還是只是對網絡爬蟲的工作原理感到好奇,本分步指南都旨在向您介紹網絡爬蟲的基礎知識,並讓您具備創建自己的爬蟲程序的技能。
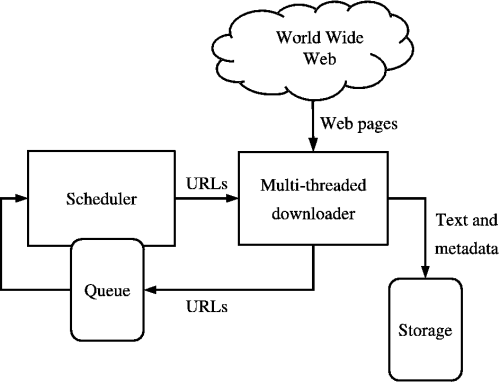
來源:https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Python 網路爬蟲 – 如何建構網路爬蟲
第 1 步:了解基礎知識
網路爬蟲,也稱為蜘蛛,是一種以有條理和自動化的方式瀏覽萬維網的程式。 對於我們的爬蟲,我們將使用 Python,因為它簡單且具有強大的庫。
第 2 步:設定您的環境
安裝 Python :確保您已安裝 Python。 您可以從 python.org 下載它。
安裝程式庫:您需要 requests 來發出 HTTP 請求,並需要 bs4 中的 BeautifulSoup 來解析 HTML。 使用 pip 安裝它們:
pip install 請求 pip install beautifulsoup4
第三步:寫出基本爬蟲
導入庫:
從 bs4 匯入 BeautifulSoup 匯入請求
取得網頁:
在這裡,我們將獲取網頁的內容。 將“URL”替換為您要抓取的網頁。
url = 'URL' 回應 = requests.get(url) 內容 = response.content
解析 HTML 內容:
湯 = BeautifulSoup(內容, 'html.parser')
提取資訊:
例如,要提取所有超鏈接,您可以執行以下操作:
for soup.find_all('a') 中的連結: print(link.get('href'))
第四步:擴展你的爬蟲
處理相對 URL :
使用 urljoin 處理相對 URL。
從 urllib.parse 導入 urljoin
避免兩次抓取同一頁:
維護一組已存取的 URL 以避免冗餘。
新增延遲:
尊重的爬行包括請求之間的延遲。 使用 time.sleep()。
第 5 步:尊重 Robots.txt
確保您的抓取工具尊重網站的 robots.txt 文件,該文件指示不應抓取網站的哪些部分。
第 6 步:錯誤處理
實作 try- except 區塊來處理潛在的錯誤,例如連線逾時或拒絕存取。
第七步:更深入
您可以增強爬網程式以處理更複雜的任務,例如表單提交或 JavaScript 渲染。 對於 JavaScript 較多的網站,請考慮使用 Selenium。
第 8 步:儲存數據
決定如何儲存您抓取的資料。 選項包括簡單的文件、資料庫,甚至直接將資料傳送到伺服器。
第 9 步:保持道德
- 不要讓伺服器超載; 在您的請求中加入延遲。
- 遵守網站的服務條款。
- 未經許可,請勿抓取或儲存個人資料。
被封鎖是網路爬行時的常見挑戰,特別是在處理具有偵測和阻止自動存取措施的網站時。 以下是一些可協助您在 Python 中解決此問題的策略和注意事項:

了解您被封鎖的原因
頻繁請求:來自相同 IP 的快速、重複請求可能會觸發阻止。
非人類模式:機器人通常表現出與人類瀏覽模式不同的行為,例如存取頁面速度過快或以可預測的順序存取頁面。
標頭管理不善: HTTP 標頭遺失或不正確可能會使您的請求看起來可疑。
忽略 robots.txt:不遵守網站 robots.txt 檔案中的指令可能會導致被封鎖。
避免被阻止的策略
尊重 robots.txt :始終檢查並遵守網站的 robots.txt 檔案。 這是一種道德實踐,可以防止不必要的阻塞。
輪換用戶代理:網站可以透過您的用戶代理識別您的身分。 透過輪換它,您可以降低被標記為機器人的風險。 使用 fake_useragent 庫來實現這一點。
from fake_useragent import UserAgent ua = UserAgent() headers = {'User-Agent': ua.random}
新增延遲:在請求之間實現延遲可以模仿人類行為。 使用 time.sleep() 新增隨機或固定延遲。
import time time.sleep(3) # 等待3秒
IP 輪換:如果可能,請使用代理服務來輪換您的 IP 位址。 為此提供免費和付費服務。
使用會話:Python 中的 requests.Session 物件可以幫助維護一致的連線並在請求之間共用標頭、cookie 等,使您的爬蟲看起來更像常規的瀏覽器會話。
將 requests.Session() 作為會話: session.headers = {'User-Agent': ua.random} response = session.get(url)
處理 JavaScript :有些網站嚴重依賴 JavaScript 來載入內容。 Selenium 或 Puppeteer 等工具可以模仿真實的瀏覽器,包括 JavaScript 渲染。
錯誤處理:實作強大的錯誤處理,以優雅地管理和回應區塊或其他問題。
道德考慮
- 始終尊重網站的服務條款。 如果網站明確禁止網頁抓取,最好遵守。
- 請注意您的爬網程序對網站資源的影響。 伺服器過載可能會給網站所有者帶來問題。
先進技術
- Web 抓取框架:考慮使用 Scrapy 等框架,它具有處理各種抓取問題的內建功能。
- 驗證碼解決服務:對於有驗證碼挑戰的網站,有一些服務可以解決驗證碼,儘管它們的使用會引起道德問題。
Python 中的最佳網頁爬行實踐
從事網路爬蟲活動需要在技術效率和道德責任之間取得平衡。 使用 Python 進行網路爬蟲時,遵守尊重資料及其來源網站的最佳實踐非常重要。 以下是使用 Python 進行網路爬行的一些關鍵注意事項和最佳實踐:
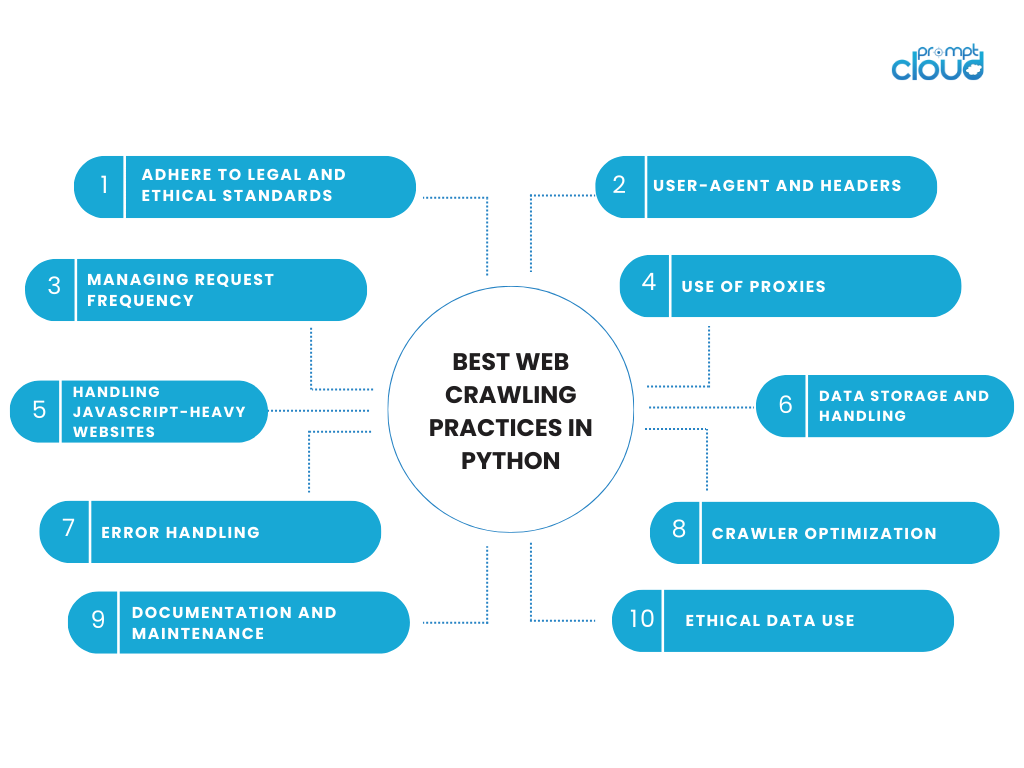
遵守法律和道德標準
- 尊重 robots.txt:始終檢查網站的 robots.txt 檔案。 該文件概述了網站所有者不希望被抓取的網站區域。
- 遵循服務條款:許多網站的服務條款中都包含有關網頁抓取的條款。 遵守這些條款既符合道德又符合法律規定。
- 避免伺服器過載:以合理的速度發出請求,以避免網站伺服器負載過重。
用戶代理和標頭
- 識別您自己的身分:使用包含您的聯絡資訊或爬網目的的使用者代理字串。 這種透明度可以建立信任。
- 正確使用標頭:配置良好的 HTTP 標頭可以降低被封鎖的可能性。 它們可以包括使用者代理、接受語言等資訊。
管理請求頻率
- 新增延遲:在請求之間實現延遲以模仿人類瀏覽模式。 使用 Python 的 time.sleep() 函數。
- 速率限制:了解在給定時間範圍內向網站發送的請求數量。
使用代理
- IP 輪換:使用代理程式輪換您的 IP 位址可以幫助避免基於 IP 的封鎖,但應以負責任且合乎道德的方式進行。
處理 JavaScript 密集型網站
- 動態內容:對於使用 JavaScript 動態載入內容的網站,Selenium 或 Puppeteer(與 Python 的 Pyppeteer 結合使用)等工具可以像瀏覽器一樣呈現頁面。
資料儲存和處理
- 資料儲存:考慮資料隱私法規,負責任地儲存爬取的資料。
- 最大限度地減少資料提取:僅提取您需要的資料。 除非絕對必要且合法,否則避免收集個人或敏感資訊。
錯誤處理
- 強大的錯誤處理:實作全面的錯誤處理來管理逾時、伺服器錯誤或無法載入的內容等問題。
爬蟲優化
- 可擴展性:設計您的爬網程序以應對規模的增加,無論是在爬行的頁面數量還是處理的資料量方面。
- 效率:優化程式碼以提高效率。 高效率的程式碼可以減少系統和目標伺服器上的負載。
文件和維護
- 保留文件:記錄您的程式碼和爬取邏輯,以便日後參考和維護。
- 定期更新:保持爬行程式碼更新,特別是當目標網站的結構發生變化時。
符合道德的數據使用
- 道德利用:以道德方式使用您收集的數據,尊重使用者隱私和數據使用規範。
綜上所述
在結束我們對用 Python 建立網路爬蟲的探索時,我們了解了自動化資料收集的複雜性以及隨之而來的道德考量。 這項努力不僅提高了我們的技術技能,還加深了我們對廣闊的數位環境中負責任的數據處理的理解。
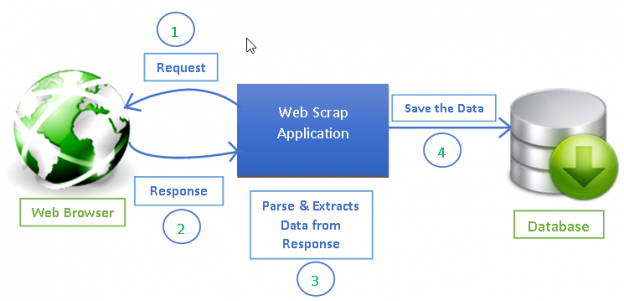
資料來源:https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
然而,創建和維護網路爬蟲可能是一項複雜且耗時的任務,特別是對於具有特定大規模資料需求的企業而言。 這就是 PromptCloud 的自訂網頁抓取服務發揮作用的地方。 如果您正在尋找適合您的 Web 資料需求的客製化、高效且合乎道德的解決方案,PromptCloud 可以提供一系列服務來滿足您的獨特需求。 從處理複雜的網站到提供乾淨的結構化數據,他們確保您的網頁抓取專案順利進行並與您的業務目標保持一致。
對於可能沒有時間或技術專業知識來開發和管理自己的網路爬蟲的企業和個人來說,將此任務外包給 PromptCloud 等專家可能會改變遊戲規則。 他們的服務不僅節省時間和資源,還能確保您獲得最準確和相關的數據,同時遵守法律和道德標準。
有興趣詳細了解 PromptCloud 如何滿足您的特定資料需求? 請透過 sales@promptcloud.com 與他們聯繫,了解更多信息,並討論他們的客製化網頁抓取解決方案如何幫助推動您的業務發展。
在網路資料的動態世界中,擁有像 PromptCloud 這樣可靠的合作夥伴可以增強您的業務能力,讓您在資料驅動的決策中佔據優勢。 請記住,在資料收集和分析領域,正確的合作夥伴至關重要。
快樂的數據狩獵!