
為法學碩士選擇和配置推理引擎
已發表: 2024-04-02推理機簡介
人們開發了許多最佳化技術來減輕推理過程不同階段發生的低效率問題。 使用普通的變壓器/技術很難大規模地擴展推理。 推理引擎將優化打包到一個包中,簡化了我們的推理過程。
對於非常小的一組臨時測試或快速參考,我們可以使用普通變壓器程式碼來進行推理。
推理引擎的格局正在迅速發展,因為我們有多種選擇,因此針對特定用例進行測試並列出最佳選擇非常重要。 以下是我們所做的一些推理引擎實驗以及我們發現它適用於我們的案例的原因。
對於我們微調的 Vicuna-7B 模型,我們嘗試過
- TGI
- 法學碩士
- 阿佛洛狄忒
- 最佳-Nvidia
- 功率推斷
- LLAMACPP
- 翻譯2
我們瀏覽了github 頁面及其快速入門指南來設定這些引擎,PowerInfer、LlaamaCPP、Ctranslate2 不是很靈活,並且與其他提到的引擎相比,不支援許多優化技術,例如連續批次、分頁注意力和保持低於標準的性能。
為了獲得更高的吞吐量,推理引擎/伺服器應該最大化記憶體和運算能力,並且客戶端和伺服器都必須以並行/非同步的方式工作來服務請求,以保持伺服器始終工作。 如前所述,如果沒有 PagedAttention、Flash Attention、連續批次等優化技術的幫助,它總是會導致效能不佳。
在這方面,TGI、vLLM 和 Aphrodite 是更合適的候選者,透過進行下述多次實驗,我們找到了最佳配置,以從推理中獲得最大性能。 預設啟用連續批次和分頁注意力等技術,需要在推理引擎中手動啟用推測解碼以進行以下測試。
推理機比較分析
TGI
要使用TGI,我們可以瀏覽github頁面的「入門」部分,這裡docker是配置和使用TGI引擎的最簡單方法。
文字產生啟動器參數 -> 此清單列出了我們可以在伺服器端使用的不同設定。 幾個重要的,
- –max-input-length :確定模型輸入的最大長度,這在大多數情況下需要更改,預設值為 1024。
- –最大總令牌數:最大 總令牌,即輸入+輸出令牌長度。
- –speculate、–quantiz、–max-concurrent-requests -> 預設值為 128,這顯然要少一些。
要啟動本地微調模型,
docker run –gpus device=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text- Generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –最大輸入長度3600 –最大總令牌4000 –推測2
要從集線器啟動模型,
型號=”lmsys/vicuna-7b-v1.5”; 體積=$PWD/數據; 令牌=”<hf_token>”; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text- Generation-inference:1.4.4 –model-id $model –model dtype float16 –num-shard 1 –最大輸入長度3600 –最大總令牌4000 –推測2
你可以請chatGPT解釋一下上面的指令,以獲得更詳細的理解。 這裡我們在 9091 連接埠啟動推理伺服器。 我們可以使用任何語言的客戶端向伺服器發出請求。 文字產生推理 API -> 提及用於請求的所有端點和負載參數。
例如
Payload=”<此處提示>”
curl -XPOST“0.0.0.0:9091/generate”-H“內容類型:application/json”-d“{“輸入”:$payload,“參數”:{“max_new_tokens”:400,“do_sample”:false , 「best_of」:空,「repetition_penalty」:1,「return_full_text」:假,「seed」:空,「stop_sequences」:空,「溫度」:0.1,「top_k」:100,「top_p」:0.3,」截斷”:空,“典型_p”:空,“水印”:假,“decoder_input_details”:假}}”
很少觀察,
- 延遲隨著 max-token-tokens 的增加而增加,很明顯,如果我們處理長文本,那麼總體時間將會增加。
- 推測有幫助,但它取決於用例和輸入輸出分佈。
- Eetq 量化對提高吞吐量有最大幫助。
- 如果您有一個多 GPU,則在每個 GPU 上執行 1 個 API 並將這些多 GPU API 放在負載平衡器後面會比 TGI 本身的分片帶來更高的吞吐量。
法學碩士
要啟動 vLLM 伺服器,我們可以使用 OpenAI 相容的 REST API 伺服器/docker。 開始非常簡單,按照 Deploying with Docker — vLLM 進行操作,如果您要使用本機模型,則附加磁碟區並使用路徑作為模型名稱,
docker run –runtime nvidia –gpus device=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=主機 vlai:latest –型號/型號
上面將在提到的 8000 連接埠上啟動 vLLM 伺服器,一如既往,您可以使用參數。
發出貼文請求,
「`殼
Payload=”<此處提示>”
curl -XPOST -m 1200“0.0.0.0:8000/v1/completions”-H“內容類型:application/json”-d“{“prompt”:$payload,“model”:“/model”,“max_tokens ” :400,“top_p”:0.3,“top_k”:100,“溫度”:0.1}”
「`
阿佛洛狄忒
「`殼

pip 安裝阿芙羅狄蒂引擎
python -m aphrodite.endpoints.openai.api_server –模型 PygmalionAI/pygmalion-2-7b
「`
或者
「`
docker run -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus device=1 –ipc 主機 alpindale/aphrodite-engine
「`
Aphrodite 提供 pip 和 docker 安裝,如入門部分所述。 Docker 通常相對更容易啟動和測試。 使用選項、伺服器選項幫助我們如何發出請求。
- Aphrodite 和 vLLM 都使用基於 openAI 伺服器的有效負載,因此您可以查看其文件。
- 我們嘗試了 deepspeed-mii,因為它處於從舊程式碼庫到新程式碼庫的過渡狀態(當我們嘗試時),它看起來並不可靠且易於使用。
- Optimum-NVIDIA 不支援其他主要最佳化並導致效能次優,參考連結。
- 新增了一個要點,即我們用來執行臨時並行請求的程式碼。
指標和測量
我們想嘗試並發現:
- 最佳編號客戶端/推理引擎伺服器的線程數。
- 吞吐量如何隨著記憶體的增加而成長
- 張量核心的吞吐量如何成長。
- 線程與客戶端並行請求的影響。
觀察利用率的非常基本的方法是透過 linux utils nvidia-smi、nvtop 進行觀察,這將告訴我們佔用的記憶體、計算利用率、資料傳輸速率等。
另一種方法是使用 GPU 和 nsys 來分析進程。
| 序號 | 圖形處理器 | 顯存 | 推理機 | 執行緒數 | 時間(秒) | 推測 |
| 1 | A6000 | 48 /48GB | TGI | 24 | 第664章 | – |
| 2 | A6000 | 48 /48GB | TGI | 64 | 第561章 | – |
| 3 | A6000 | 48 /48GB | TGI | 128 | 第554章 | – |
| 4 | A6000 | 48 /48GB | TGI | 256 | 第568章 | – |
根據上述實驗,128/ 256 執行緒優於較低執行緒數,超過 256 開銷開始導致吞吐量降低。 這個發現是依賴CPU和GPU的,需要自己實驗。 | ||||||
| 5 | A6000 | 48 /48GB | TGI | 128 | 第596章 | 2 |
| 6 | A6000 | 48 /48GB | TGI | 128 | 第945章 | 8 |
較高的推測值會導致我們的微調模型被更多拒絕,從而降低吞吐量。 1 / 2 因為推測值很好,這取決於模型,並且不能保證在不同用例中都能正常運作。 但結論是推測解碼提高了吞吐量。 | ||||||
| 7 | 3090 | 24/24GB | TGI | 128 | 第741章 | 2 |
| 7 | 4090 | 24/24GB | TGI | 128 | 第481章 | 2 |
儘管與 A6000 相比,4090 的 vRAM 較少,但由於張量核心數量和記憶體頻寬速度更高,它的效能更勝一籌。 | ||||||
| 8 | A6000 | 24/48GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2 個 24/48GB | TGI | 128 | 1205 | 2 |
設定和配置 TGI 以實現高吞吐量
使用選擇的腳本語言(例如 python/ruby)設定非同步請求,並使用我們發現的相同檔案進行設定:
- 所花費的時間增加了序列產生的最大輸出長度。
- 客戶端和伺服器上的 128/ 256 執行緒優於 24、64、512。當使用較低執行緒時,計算利用率不足,超過 128 等閾值時,開銷會變得更高,因此吞吐量會降低。
- 使用「GNU 並行」而不是 Go、Python/Ruby 等語言中的執行緒從非同步請求跳到並行請求時,效能提高了 6%。
- 4090 的吞吐量比 A6000 高 12%。 儘管與 A6000 相比,4090 的 vRAM 較少,但由於張量核心數量和記憶體頻寬速度更高,它的效能更勝一籌。
- 由於 A6000 具有 48GB vRAM,為了斷定額外的 RAM 是否有助於提高吞吐量,我們在表的實驗 8 中嘗試使用部分 GPU 內存,我們發現額外的 RAM 有助於提高,但不是線性的。 此外,當嘗試拆分(即在同一 GPU 上託管 2 個 API,每個 API 使用一半記憶體)時,它的行為就像 2 個順序 API 運行,而不是並行接受請求。
觀察和指標
以下是一些實驗的圖表以及完成固定輸入集所需的時間,所用時間越短越好。
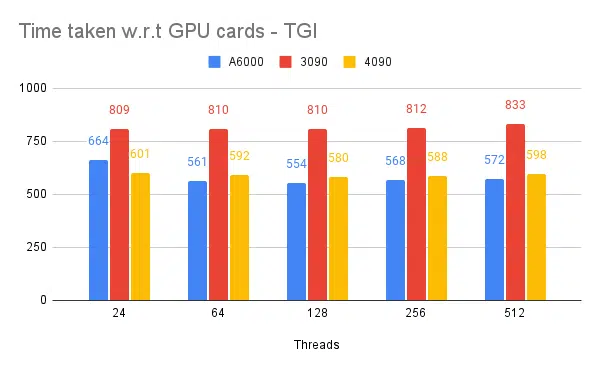
- 提到的是客戶端線程。 在啟動推理引擎時我們需要提到伺服器端。
推測測試:

多重推理引擎測驗:
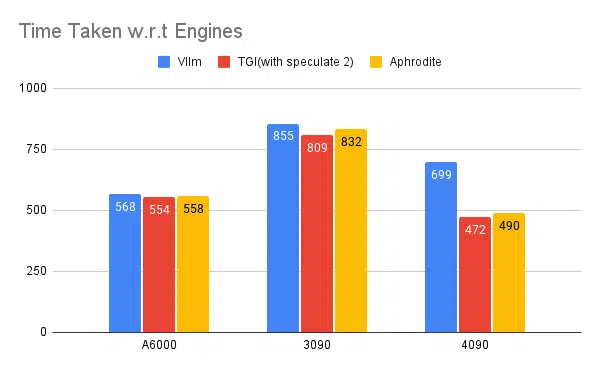
使用 vLLM 和 Aphrodite 等其他引擎進行相同類型的實驗,我們觀察到類似的結果,截至撰寫本文時,vLLM 和 Aphrodite 尚不支援推測解碼,這使我們選擇 TGI,因為它提供的吞吐量高於其他引擎推測性解碼。
此外,您可以設定 GPU 分析器來增強可觀察性,幫助識別資源使用過多的區域並最佳化效能。 進一步閱讀:Nvidia Nsight 開發者工具 — Max Katz
結論
我們看到推理生成的前景不斷發展,提高 LLM 的吞吐量需要充分了解 GPU、效能指標、最佳化技術以及與文字生成任務相關的挑戰。 這有助於為工作選擇正確的工具。 透過了解 GPU 內部結構以及它們如何對應 LLM 推理,例如利用張量核心和最大化記憶體頻寬,開發人員可以選擇經濟高效的 GPU 並有效優化效能。
不同的 GPU 卡提供不同的功能,了解差異對於為特定任務選擇最合適的硬體至關重要。 連續批次處理、分頁注意力、核心融合和快閃注意力等技術為克服出現的挑戰和提高效率提供了有前景的解決方案。 根據我們獲得的實驗和結果,TGI 看起來是我們用例的最佳選擇。
閱讀與大語言模型相關的其他文章:
了解 LLM 推理最佳化的 GPU 架構
提升 LLM 吞吐量的先進技術