
建構網路爬蟲的分步指南
已發表: 2023-12-05在錯綜複雜的互聯網中,資訊分散在無數的網站上,網路爬蟲成為無名英雄,努力組織、索引這些豐富的數據並使之可供訪問。 本文開始對網路爬蟲進行探索,闡明其基本運作原理,區分網路爬蟲和網路抓取,並提供實用的見解,例如製作簡單的基於 Python 的網路爬蟲的逐步指南。 隨著我們深入研究,我們將揭示 Scrapy 等高級工具的功能,並了解 PromptCloud 如何將網路爬行提升到工業規模。
什麼是網路爬蟲
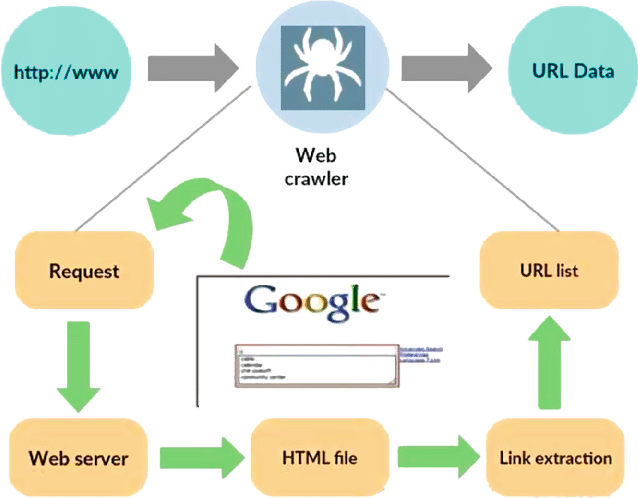
資料來源: https ://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
網路爬蟲,也稱為蜘蛛或機器人,是一種專門的程序,旨在系統化、自主地導航廣闊的萬維網。 其主要功能是為了各種目的遍歷網站、收集資料和索引信息,例如搜尋引擎優化、內容索引或資料提取。
網路爬蟲的核心是模仿人類使用者的行為,但速度更快、更有效率。 它從指定的起點(通常稱為種子 URL)開始其旅程,然後沿著超連結從一個網頁到另一個網頁。 追蹤連結的過程是遞歸的,允許爬蟲探索網路的很大一部分。
當爬蟲訪問網頁時,它會系統地提取並儲存相關數據,其中可以包括文字、圖像、元數據等。 然後對提取的資料進行組織和索引,使搜尋引擎在查詢時更容易檢索並向使用者呈現相關資訊。
網路爬蟲在 Google、Bing 和 Yahoo 等搜尋引擎的功能中發揮關鍵作用。 透過持續、有系統地抓取網絡,他們確保搜尋引擎索引是最新的,為用戶提供準確且相關的搜尋結果。 此外,網路爬蟲也用於各種其他應用,包括內容聚合、網站監控和資料探勘。
網路爬蟲的有效性取決於其導航不同網站結構、處理動態內容以及遵守網站透過 robots.txt 檔案設定的規則的能力,該檔案概述了可以爬網的網站的哪些部分。 了解網路爬蟲的運作方式對於理解它們在使龐大的資訊網路可訪問和組織起來方面的重要性至關重要。
網路爬蟲如何運作
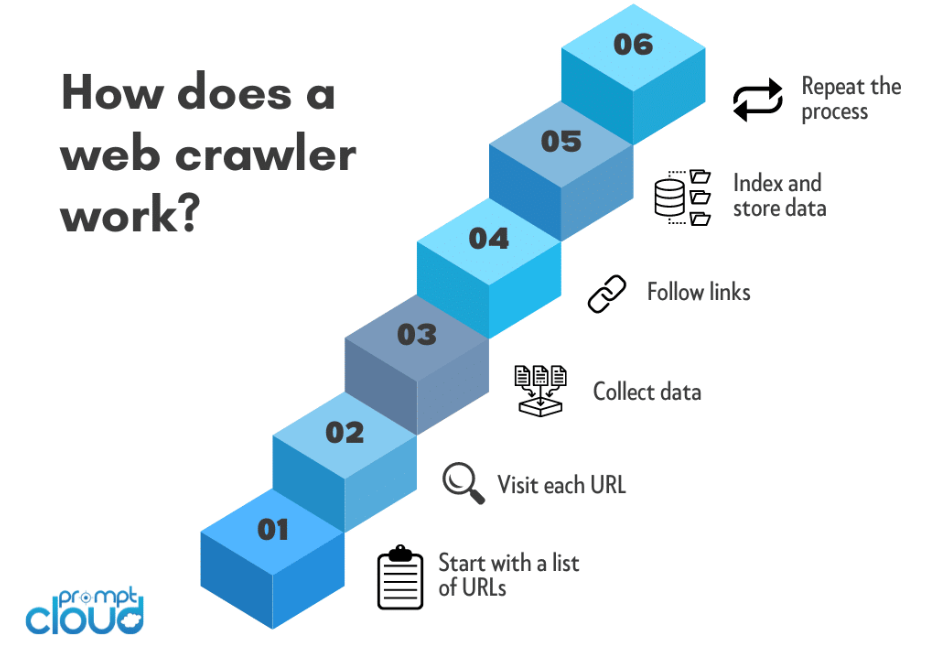
網路爬蟲,也稱為蜘蛛或機器人,透過導航萬維網從網站收集資訊的系統流程進行操作。 以下是網路爬蟲如何運作的概述:
種子網址選擇:
網路爬行過程通常從種子 URL 開始。 這是爬蟲開始其旅程的初始網頁或網站。
HTTP 請求:
爬蟲會向種子 URL 發送 HTTP 請求以檢索網頁的 HTML 內容。 此請求類似於網頁瀏覽器造訪網站時發出的請求。
HTML 解析:
一旦取得 HTML 內容,爬蟲就會解析它以提取相關資訊。 這涉及將 HTML 程式碼分解為爬蟲可以導航和分析的結構化格式。
網址擷取:
爬蟲識別並提取 HTML 內容中存在的超連結 (URL)。 這些 URL 代表爬蟲隨後將訪問的其他頁面的連結。
隊列和調度器:
提取的 URL 將會加入到佇列或排程器中。 佇列確保爬網程序按特定順序存取 URL,通常首先優先考慮新的或未存取的 URL。
遞迴:
爬蟲沿著佇列中的鏈接,重複發送 HTTP 請求、解析 HTML 內容和提取新 URL 的過程。 這種遞歸過程讓爬蟲瀏覽多層網頁。
資料擷取:
當爬蟲遍歷網路時,它會從每個造訪的頁面中提取相關資料。 提取的資料類型取決於爬蟲的目的,可能包括文字、圖像、元資料或其他特定內容。
內容索引:
將收集到的資料進行組織和索引。 索引涉及建立一個結構化資料庫,以便在使用者提交查詢時可以輕鬆搜尋、檢索和呈現資訊。
尊重機器人.txt:
網路爬蟲通常遵守網站的 robots.txt 檔案中指定的規則。 此文件提供了有關可以對網站的哪些區域進行爬網以及應該排除哪些區域的指南。
抓取延遲和禮貌:
為了避免伺服器超載並造成中斷,爬蟲通常會採用爬行延遲和禮貌機制。 這些措施確保爬蟲以尊重且不造成乾擾的方式與網站互動。
網路爬蟲有系統地瀏覽網路、追蹤連結、提取資料並建立有組織的索引。 此過程使搜尋引擎能夠根據使用者的查詢向使用者提供準確且相關的結果,使網路爬蟲成為現代網路生態系統的基本組成部分。
網路爬行與網路抓取

來源:https://research.aimultiple.com/web-crawling-vs-web-scraping/

雖然網路爬行和網路抓取經常互換使用,但它們具有不同的目的。 網路爬行涉及系統地瀏覽網路以索引和收集信息,而網頁抓取則專注於從網頁中提取特定資料。 本質上,網絡爬行是關於探索和繪製網絡,而網絡抓取是關於收集目標資訊。
建構網路爬蟲
用Python建立一個簡單的網路爬蟲涉及幾個步驟,從設定開發環境到編寫爬蟲邏輯。 以下是詳細的指南,可協助您使用 Python 建立基本的網路爬蟲,利用 requests 程式庫發出 HTTP 請求,並使用 BeautifulSoup 進行 HTML 解析。
第 1 步:設定環境
確保您的系統上安裝了 Python。 您可以從 python.org 下載它。 此外,您還需要安裝所需的程式庫:
pip install requests beautifulsoup4
第2步:導入庫
建立一個新的 Python 檔案(例如 simple_crawler.py)並匯入必要的函式庫:
import requests from bs4 import BeautifulSoup
第三步:定義爬蟲函數
建立一個函數,將 URL 作為輸入,發送 HTTP 請求,並從 HTML 內容中提取相關資訊:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
第四步:測試爬蟲
提供範例 URL 並呼叫 simple_crawler 函數來測試爬蟲:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
第 5 步:運行爬網程序
在終端機或命令提示字元中執行 Python 腳本:
python simple_crawler.py
爬蟲將取得所提供的 URL 的 HTML 內容,對其進行解析並列印標題。 您可以透過新增更多功能來擴充爬網程式以提取不同類型的資料。
使用 Scrapy 進行網頁爬行
使用 Scrapy 進行網頁抓取打開了通往強大而靈活的框架的大門,該框架專為高效且可擴展的網頁抓取而設計。 Scrapy 簡化了建立網路爬蟲的複雜性,為建立可以導航網站、提取資料並以系統方式儲存的蜘蛛提供了一個結構化環境。 以下是使用 Scrapy 進行網路爬行的詳細介紹:
安裝:
在開始之前,請確保您已安裝 Scrapy。 您可以使用以下方式安裝它:
pip install scrapy
建立一個 Scrapy 專案:
啟動一個 Scrapy 專案:
開啟終端並導航至要建立 Scrapy 專案的目錄。 運行以下命令:
scrapy startproject your_project_name
這將建立一個帶有必要文件的基本專案結構。
定義蜘蛛:
在專案目錄中,導覽至 Spiders 資料夾並為您的 Spider 建立一個 Python 檔案。 透過子類化 scrapy.Spider 並提供名稱、允許的網域和起始 URL 等基本詳細資訊來定義蜘蛛類。
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
擷取資料:
使用選擇器:
Scrapy 利用強大的選擇器從 HTML 中提取資料。 您可以在蜘蛛的解析方法中定義選擇器來捕捉特定元素。
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
此範例提取 <title> 標籤的文字內容。
以下連結:
Scrapy 簡化了追蹤連結的過程。 使用follow方法可以跳到其他頁面。
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
運行蜘蛛:
使用專案目錄中的以下命令執行蜘蛛:
scrapy crawl your_spider
Scrapy 將啟動蜘蛛,追蹤鏈接,並執行 parse 方法中定義的解析邏輯。
使用 Scrapy 進行網頁抓取提供了一個強大且可擴展的框架,用於處理複雜的抓取任務。 其模組化架構和內建功能使其成為從事複雜 Web 資料擷取專案的開發人員的首選。
大規模網路爬行
大規模網路爬行帶來了獨特的挑戰,尤其是在處理分佈在眾多網站上的大量資料時。 PromptCloud 是一個專門的平台,旨在大規模簡化和優化網路爬行過程。 以下是 PromptCloud 如何協助處理大規模網路爬行計畫:
- 可擴展性
- 資料擷取與豐富
- 數據品質和準確性
- 基礎設施管理
- 使用方便
- 合規與道德
- 即時監控和報告
- 支援與維護
PromptCloud 是一個強大的解決方案,適合尋求大規模網路爬行的組織和個人。 透過解決與大規模資料擷取相關的關鍵挑戰,該平台提高了網路爬行計畫的效率、可靠性和可管理性。
總之
網路爬蟲是廣闊的數位領域中的無名英雄,勤奮地在網路中導航以索引、收集和組織資訊。 隨著網路爬蟲專案規模的擴大,PromptCloud 作為解決方案介入,提供可擴展性、資料豐富性和道德合規性,以簡化大規模計劃。 請透過sales@promptcloud.com與我們聯繫