
了解 LLM 推理最佳化的 GPU 架構
已發表: 2024-04-02LLM 簡介與 GPU 最佳化的重要性
在當今自然語言處理 (NLP) 不斷進步的時代,大型語言模型 (LLM) 已成為執行各種任務(從文本生成到問答和摘要)的強大工具。 這些不僅僅是下一個可能的代幣生成器。 然而,這些模型不斷增長的複雜性和規模對計算效率和效能提出了重大挑戰。
在這篇部落格中,我們深入研究了 GPU 架構的複雜性,探索不同的元件如何促進 LLM 推理。 我們將討論關鍵效能指標,例如記憶體頻寬和張量核心利用率,並闡明各種 GPU 卡之間的差異,使您能夠在為大型語言模型任務選擇硬體時做出明智的決策。
在快速發展的環境中,NLP 任務需要不斷增加的運算資源,而最佳化 LLM 推理吞吐量至關重要。 加入我們,踏上這段旅程,透過 GPU 優化技術釋放法學碩士的全部潛力,並深入研究使我們能夠有效提高效能的各種工具。
法學碩士的 GPU 架構重點 – 了解您的 GPU 內部架構
憑藉執行高效平行運算的性質,GPU 成為運行所有深度學習任務的首選設備,因此了解 GPU 架構的高階概述對於了解推理階段出現的潛在瓶頸非常重要。 Nvidia卡因CUDA(計算統一設備架構)而受到青睞,CUDA是NVIDIA開發的專有平行運算平台和API,它允許開發人員用C程式語言指定執行緒級並行性,提供對GPU虛擬指令集和並行性的直接存取計算元素。
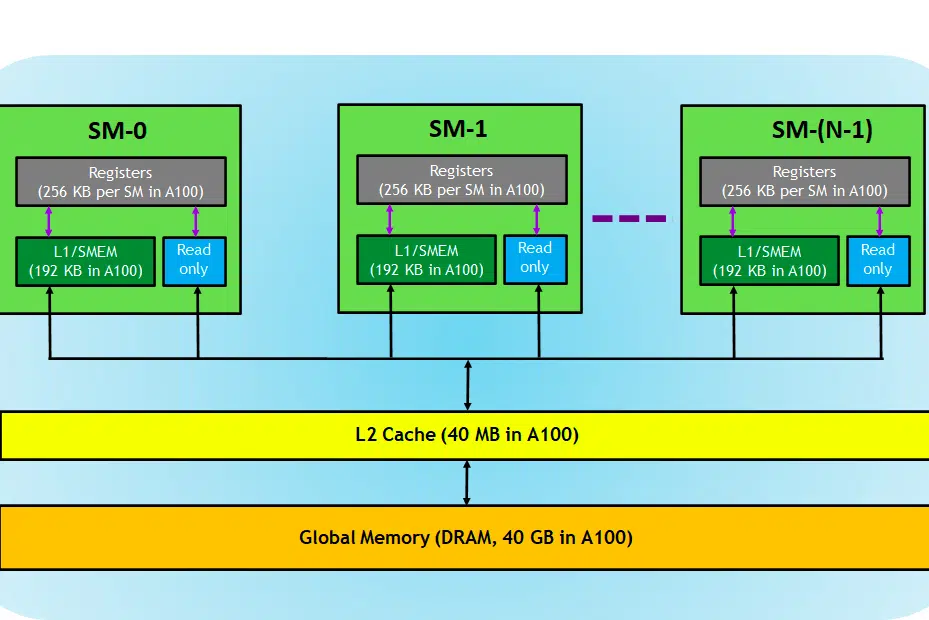
在上下文中,我們使用 NVIDIA 卡進行解釋,因為如前所述,它廣泛用於深度學習任務,並且很少有其他術語(例如張量核心)適用於此。
讓我們來看看 GPU 卡,在映像中,我們可以看到 GPU 裝置的三個主要部分和(一個主要的隱藏部分)
- SM(串流多處理器)
- 二級緩存
- 記憶體頻寬
- 全域記憶體(DRAM)
就像 CPU 和 RAM 一起發揮作用一樣,RAM 是資料駐留的地方(即記憶體),CPU 是處理任務的地方(即進程)。 在GPU中,高頻寬全域記憶體(DRAM)會保存載入到記憶體中的模型(例如LLAMA 7B)權重,並且在需要時,這些權重會傳送到處理單元(即SM處理器)進行計算。
串流式多處理器
串流多處理器或 SM 是稱為 CUDA 核心(NVIDIA 專有平行運算平台)的較小執行單元的集合,以及負責指令獲取、解碼、調度和分派的附加功能單元。 每個 SM 獨立運作並包含自己的暫存器檔案、共享記憶體、L1 快取和紋理單元。 SM 高度並行化,允許它們同時處理數千個線程,這對於在 GPU 運算任務中實現高吞吐量至關重要。 處理器的效能通常以 FLOPS 來衡量,即 FLOPS。 它每秒可以執行的浮動操作。
深度學習任務主要由張量運算組成,即矩陣-矩陣乘法,nvidia 在新一代 GPU 中引入了張量核心,這些核心專門設計用於以高效的方式執行這些張量運算。 如前所述,張量核心在深度學習任務中非常有用,我們必須檢查張量核心以確定 GPU 執行 LLM 訓練/推理的效率,而不是 CUDA 核心。
二級緩存
L2 快取是一種在 SM 之間共享的高頻寬內存,旨在優化系統內的內存存取和資料傳輸效率。 與 DRAM 相比,它是一種更小、更快的記憶體類型,更靠近處理單元(例如串流多處理器)。 它減少了每個記憶體請求存取速度較慢的 DRAM 的需要,從而有助於提高整體記憶體存取效率。
記憶體頻寬
因此,效能取決於我們將權重從記憶體傳輸到處理器的速度以及處理器處理給定計算的效率和速度。
當運算能力高於/快於記憶體到SM之間的資料傳輸速率時,SM將缺乏資料來處理,因此計算未充分利用,這種記憶體頻寬低於消耗率的情況稱為記憶體限制階段。 值得注意的是,這是推理過程中常見的瓶頸。
相反,如果計算花費更多時間進行處理並且更多資料排隊等待計算,則此狀態是計算限制階段。
為了充分利用 GPU,我們必須處於運算密集狀態,同時盡可能有效率地進行運算。
記憶體
DRAM 充當 GPU 中的主記憶體,提供大量記憶體來儲存運算所需的資料和指令。 它通常按層次結構組織,具有多個儲存體和通道以實現高速存取。
對於推理任務,GPU 的 DRAM 決定了我們可以載入多大的模型,計算 FLOPS 和頻寬決定了我們可以獲得的吞吐量。
比較用於 LLM 任務的 GPU 卡
要獲取有關張量核心數量、頻寬速度的信息,可以查看 GPU 製造商發布的白皮書。 這是一個例子,

| RTX A6000 | RTX 4090 | RTX 3090 | |
| 記憶體大小 | 48GB | 24GB | 24GB |
| 記憶體型 | GDDR6 | GDDR6X | |
| 頻寬 | 768.0GB/秒 | 1008 GB/秒 | 936.2GB/秒 |
| CUDA 核心/GPU | 10752 | 16384 | 10496 |
| 張量核心 | 第336章 | 第512章 | 328 |
| 一級緩存 | 128 KB(每個 SM) | 128 KB(每個 SM) | 128 KB(每個 SM) |
| FP16 非張量 | 38.71 兆次浮點運算 (1:1) | 82.6 | 35.58 兆次浮點運算 (1:1) |
| FP32 非張量 | 38.71 兆次浮點運算 | 82.6 | 35.58 兆次浮點運算 |
| FP64 非張量 | 1,210 GFLOPS (1:32) | 556.0 GFLOPS (1:64) | |
| 具有 FP16 累積的峰值 FP16 張量 TFLOPS | 154.8/309.6 | 330.3/660.6 | 142/284 |
| 具有 FP32 累積的峰值 FP16 張量 TFLOPS | 154.8/309.6 | 165.2/330.4 | 71/142 |
| 具有 FP32 的峰值 BF16 張量 TFLOPS | 154.8/309.6 | 165.2/330.4 | 71/142 |
| 峰值 TF32 張量 TFLOPS | 77.4/154.8 | 82.6/165.2 | 35.6/71 |
| 峰值 INT8 張量 TOPS | 309.7/619.4 | 660.6/1321.2 | 284/568 |
| 峰值 INT4 張量 TOPS | 619.3/1238.6 | 1321.2/2642.4 | 568/1136 |
| 二級緩存 | 6MB | 72MB | 6MB |
| 記憶體總線 | 384位 | 384位 | 384位 |
| TMU | 第336章 | 第512章 | 328 |
| ROP | 112 | 176 | 112 |
| SM計數 | 84 | 128 | 82 |
| RT 核心 | 84 | 128 | 82 |
在這裡我們可以看到 FLOPS 是針對張量運算專門提到的,這些資料將幫助我們比較不同的 GPU 卡並篩選出適合我們用例的 GPU 卡。 從表中可以看出,雖然A6000的記憶體是4090的兩倍,但4090的張量觸發器和記憶體頻寬在數量上更勝一籌,因此對於大型語言模型的推理能力更強。
進一步閱讀:100 秒了解 Nvidia CUDA
結論
在快速發展的 NLP 領域,推理任務的大型語言模型(LLM)最佳化已成為關鍵的關注領域。 正如我們所探索的,GPU 架構在這些任務中實現高效能和高效率方面發揮關鍵作用。 了解 GPU 的內部元件,例如串流多處理器 (SM)、L2 快取、記憶體頻寬和 DRAM,對於識別 LLM 推理過程中的潛在瓶頸至關重要。
不同 NVIDIA GPU 卡(RTX A6000、RTX 4090 和 RTX 3090)之間的比較揭示了記憶體大小、頻寬以及 CUDA 和 Tensor Core 數量等因素的顯著差異。 這些差異對於就哪種 GPU 最適合特定的 LLM 任務做出明智的決定至關重要。 例如,雖然 RTX A6000 提供更大的內存,但 RTX 4090 在張量 FLOPS 和內存頻寬方面表現出色,使其成為要求苛刻的 LLM 推理任務的更有效選擇。
優化 LLM 推理需要一種平衡的方法,既要考慮 GPU 的運算能力,也要考慮目前 LLM 任務的特定要求。 選擇合適的 GPU 需要了解記憶體容量、處理能力和頻寬之間的權衡,以確保 GPU 能夠有效處理模型的權重並執行計算,而不會成為瓶頸。 隨著 NLP 領域的不斷發展,對於那些希望突破大型語言模型的極限的人來說,了解最新的 GPU 技術及其功能至關重要。
使用的術語
- 吞吐量:
在推理的情況下,吞吐量是在給定時間段內處理多少請求/提示的測量。 吞吐量通常以兩種方式來衡量:
- 每秒請求數 (RPS) :
- RPS 衡量模型在一秒鐘內可以處理的推理請求數量。 推理請求通常涉及基於輸入資料產生回應或預測。
- 對於 LLM 生成,RPS 表示模型回應傳入提示或查詢的速度。 RPS 值越高,表示即時或近距離即時應用程式的回應能力和可擴展性越好。
- 實現高 RPS 值通常需要高效的部署策略,例如將多個請求一起批次處理以分攤開銷並最大限度地利用運算資源。
- 每秒令牌數 (TPS) :
- TPS 衡量模型在文字生成過程中處理和產生標記(單字或子單字)的速度。
- 在LLM生成的背景下,TPS反映了模型在生成文字方面的吞吐量。 它表明模型能夠多快地產生連貫且有意義的響應。
- TPS 值越高意味著文字生成速度越快,從而允許模型在給定時間內處理更多輸入資料並產生更長的回應。
- 實現高 TPS 值通常涉及最佳化模型架構、平行運算以及利用 GPU 等硬體加速器來加快令牌生成。
- 潛伏:
LLM 中的延遲是指推理期間輸入和輸出之間的時間延遲。 最大限度地減少延遲對於增強用戶體驗並在利用法學碩士的應用程式中實現即時互動至關重要。 根據我們需要提供的服務,在吞吐量和延遲之間取得平衡至關重要。 對於即時互動聊天機器人/副駕駛等情況需要低延遲,但對於內部資料重新處理等批次資料處理情況則不需要。
在此閱讀有關提高 LLM 吞吐量的高級技術的更多資訊。