
如何使用 R 和 Python 將數據上傳到 BigQuery
已發表: 2023-06-06網絡分析世界繼續朝著 7 月 1 日這個決定性的日期前進,屆時 Universal Analytics 將停止處理數據並被 Google Analytics 4 (GA4) 取代。 其中一項關鍵變化是,在 GA4 中,您最多只能在平台中保留數據 14 個月。 這是 UA 的重大變化,但作為交換,您可以免費將 GA4 數據推送到 BigQuery 中,但有限制。
BigQuery 是超越 GA4 的數據存儲的極其有用的資源。 隨著它在幾個月內變得比以往任何時候都更加重要,現在是開始使用它來滿足您所有數據存儲需求的最佳時機。 通常,最好在上傳之前以某種方式處理數據。 為此,我們建議使用用 R 或 Python 編寫的腳本,尤其是在需要重複執行此類操作的情況下。 您還可以直接從這些腳本將數據上傳到 BigQuery,而這正是本博客將指導您完成的內容。
從 R 上傳到 BigQuery
R 是一種非常強大的數據科學語言,也是最容易用於將數據上傳到 BigQuery 的語言。 第一步是導入所有必要的庫。 對於本教程,我們將需要以下庫:
library(googleAuthR)
library(bigQueryR)
如果您以前沒有使用過這些庫,請在控制台中運行install.packages(<PACKAGE NAME>)來安裝它們。
接下來,我們必須解決使用 API 時通常最棘手、最令人沮喪的部分——授權。 幸運的是,有了 R,這就相對簡單了。 您將需要一個包含授權憑據的 JSON 文件。 這可以在 Google Cloud Console 中找到,BigQuery 位於同一位置。 首先,導航到 Google Cloud Console,然後單擊“API 和服務”。
接下來,單擊邊欄中的“憑據”。
在 Credentials 頁面上,您可以查看現有的 API 密鑰、OAuth 2.0 客戶端 ID 和服務帳戶。 為此,您需要一個 OAuth 2.0 客戶端 ID,因此請點擊您 ID 相關行末尾的下載按鈕,或者通過單擊頁面頂部的“創建憑據”來創建一個新 ID。 確保您的 ID 有權查看和編輯相關的 BigQuery 項目——為此,打開側邊欄,將鼠標懸停在“IAM 和管理”上,然後點擊“IAM”。 在此頁面上,您可以使用頁面頂部的“授予訪問權限”按鈕授予您的服務帳戶對相關項目的訪問權限。
獲取並保存 JSON 文件後,您可以使用 gar_set_client() 函數將路徑傳遞給它以設置您的憑據。 完整的授權代碼如下:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
顯然,您需要將 gar_set_client() 函數中的路徑替換為您自己的 JSON 文件的路徑,並將用於訪問 BigQuery 的電子郵件地址插入到 bqr_auth() 函數中。
授權設置完成後,我們需要一些數據上傳到 BigQuery。 我們需要將這些數據放入數據框中。 出於本文的目的,我將創建一些包含多個位置和銷售數量的虛構數據,但您很可能會從 .csv 文件或電子表格中讀取真實數據。 要從 .csv 文件中讀取數據,您可以簡單地使用 read.csv() 函數,將文件路徑作為參數傳遞:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
或者,如果您將數據存儲在電子表格中,則您的方法將根據電子表格所在的位置而有所不同。 如果您的電子表格存儲在 Google 表格中,您可以使用 googlesheets4 庫將其數據讀入 R:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
和以前一樣,如果您以前沒有使用過這個包,則必須在運行代碼之前在控制台中運行 install.packages(“googlesheets4”)。
如果您的電子表格在 Excel 中,您將需要使用 readxl 庫,它是 tidyverse 庫的一部分——我推薦使用它。 它包含大量函數,使 R 中的數據操作變得更加容易:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
再一次,確保運行 install.package(“tidyverse”) 如果您之前沒有運行過!
最後一步是將數據上傳到 BigQuery。 為此,您需要在 BigQuery 中有一個位置來上傳它。 您的表將位於一個數據集中,該數據集將位於一個項目中,並且您需要採用以下格式的所有這三個名稱:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
就我而言,這意味著我的代碼如下:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
如果您的表還不存在,請不要擔心,代碼會為您創建它。 不要忘記將項目、數據集和表的名稱插入到上面的代碼中(在引號內),並確保上傳正確的數據框! 完成後,您應該會在 BigQuery 中看到您的數據,如下所示:
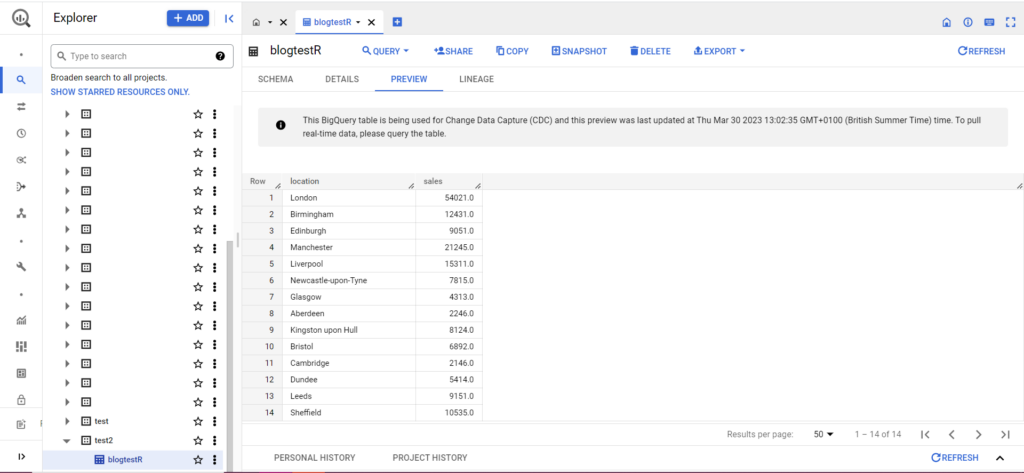
作為最後一步,假設您有其他數據要添加到 BigQuery。 例如,在我上面的數據中,假設我忘記包含來自大陸的幾個位置,我想上傳到 BigQuery,但我不想覆蓋現有數據。 為此,bqr_upload_data 有一個名為 writeDisposition 的參數。 writeDisposition 有兩個設置,“WRITE_TRUNCATE”和“WRITE_APPEND”。 前者告訴 bqr_upload_data() 覆蓋表中的現有數據,而後者告訴它追加新數據。 因此,要上傳這個新數據,我會寫:

bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
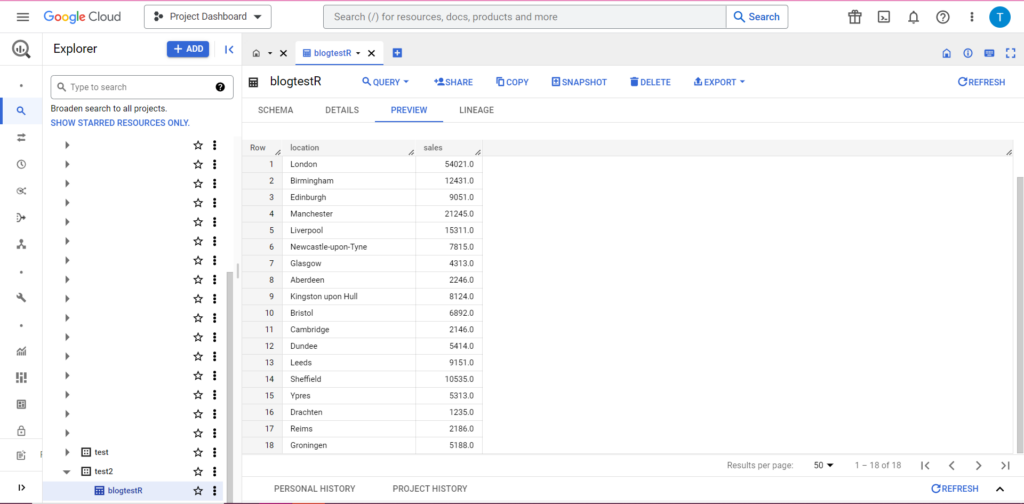
果然,在 BigQuery 中我們可以看到我們的數據有一些新室友:
從 Python 上傳到 BigQuery
在 Python 中,情況有些不同。 再一次,我們需要導入一些包,所以讓我們從這些開始:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
授權很複雜。 我們將再次需要一個包含憑據的 JSON 文件。 如上所述,我們將導航到 Google Cloud Console 並單擊“APIs and Services”,然後單擊側邊欄中的“Credentials”。 這一次,在頁面底部,將有一個名為“服務帳戶”的部分。
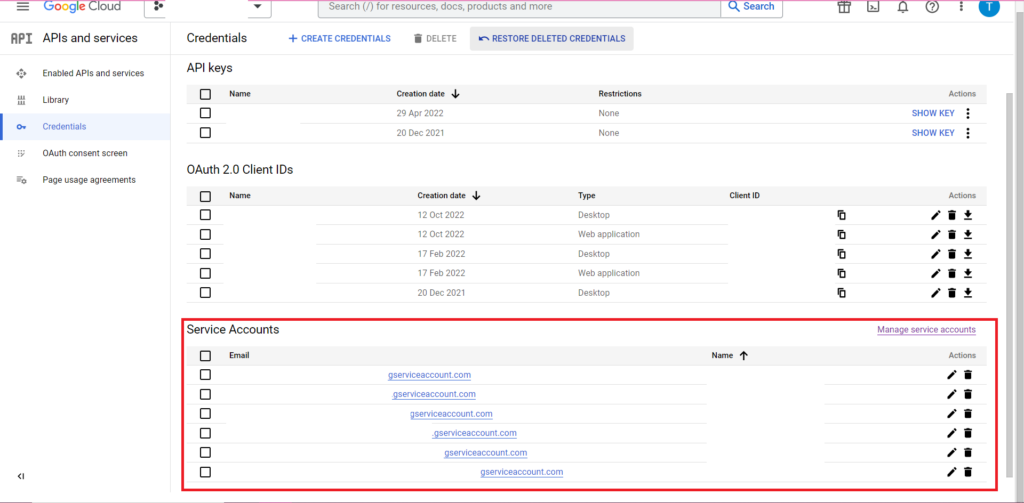
在那裡,您可以將密鑰下載到您的服務帳戶,或者通過單擊“管理服務帳戶”,您可以創建一個新密鑰或一個新的服務帳戶,您可以為其下載憑據。
然後,您需要確保您的服務帳戶有權訪問和編輯您的 BigQuery 項目。 再次導航到邊欄中“IAM 和管理”下的 IAM 頁面,您可以在此處使用頁面頂部的“授予訪問權限”按鈕授予您的服務帳戶對相關項目的訪問權限。
整理好後,您可以編寫授權代碼:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
接下來,您必須將數據放入數據框中。 Dataframes 屬於 pandas 包,創建起來非常簡單。 要從 CSV 中讀入,請遵循以下示例:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
顯然,您需要將上面的路徑替換為您自己的 CSV 文件。 要從 Excel 文件中讀取,請按照以下示例操作:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
從谷歌表格中讀取是很棘手的,需要另一輪授權。 我們將需要導入一些新包,並使用我們在上面的 R 教程中檢索到的 JSON 憑據文件。 您可以按照此代碼授權和讀取您的數據:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
將數據放入數據框中後,就可以再次上傳到 BigQuery 了! 您可以按照此模板執行此操作:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
例如,這是我剛剛編寫的用於上傳我之前製作的數據的代碼:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
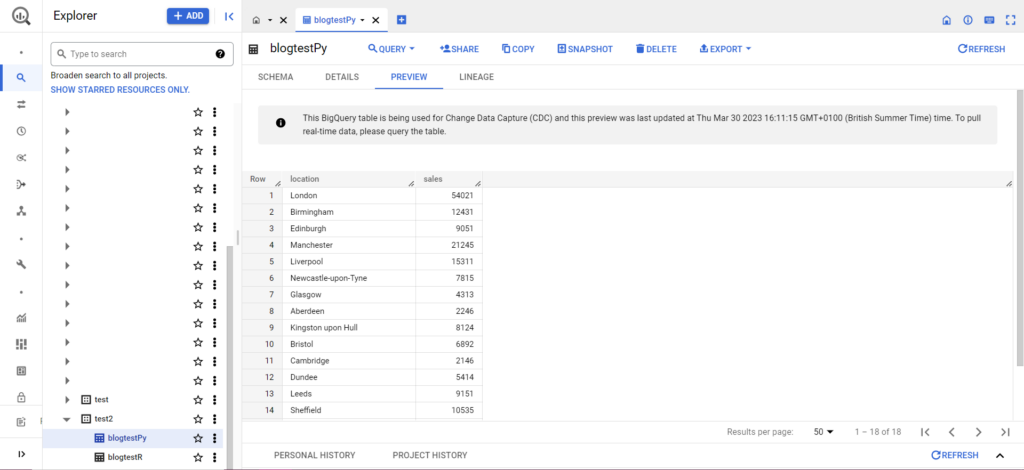
一旦完成,數據應該立即出現在 BigQuery 中!
一旦掌握了這些功能,您可以使用它們做更多的事情。 如果您想更好地控制您的分析設置,Semetrical 可以為您提供幫助! 查看我們的博客,了解有關如何充分利用數據的更多信息。 或者,要獲得有關所有事物分析的更多支持,請訪問 Web Analytics 以了解我們如何為您提供幫助。