
搜索引擎使用什麼技術來抓取網站?
已發表: 2023-03-02
如果您曾經想知道搜索引擎使用什麼技術來抓取網站,那麼請準備好最終讓您的問題得到解答。 您將了解到網絡爬蟲是什麼、主要搜索引擎使用的許多不同類型的網絡爬蟲,以及搜索索引過程的全部內容。 您還將了解所有這些將如何影響搜索引擎結果,以及網站所有者如何告訴搜索引擎網絡爬蟲根據他們的意願為內容編制索引。 讓我們進一步了解搜索引擎使用的這項技術,它可以將數十億個相關搜索結果準確地提供給在萬維網上尋找信息的人們。
什麼是網絡爬蟲或搜索引擎機器人?
網絡爬蟲機器人也稱為蜘蛛,是一種自動化程序,谷歌和微軟等公司使用這些程序來教他們的搜索引擎他們可以在互聯網上找到的每個網站的每個可訪問網頁上顯示的內容。 只有通過了解網頁上包含哪些信息,這些搜索引擎才能在其用戶之一鍵入請求了解特定主題的搜索查詢時準確檢索此信息。
網絡爬蟲機器人的類型
每個搜索引擎都有自己的網絡爬蟲。 這裡有一些最廣泛使用的。
谷歌機器人
谷歌是地球上最流行的搜索引擎,它使用兩個版本的網絡爬蟲來索引數千億個網頁。 GoogleBot Desktop 將查看模仿某人使用台式計算機瀏覽互聯網的行為的頁面,而 GoogleBot Mobile 將對智能手機用戶執行相同的操作。
GoogleBot 是有史以來最有效的搜索機器人之一,可以快速抓取網頁並為其編制索引。 然而,它在爬行非常複雜的網站結構時確實存在一些問題。 此外,GoogleBot 通常需要幾天或幾週的時間來抓取新發布的網頁,這意味著它暫時不會出現在相關結果中。
冰棒
Bingbot 是微軟在自己的搜索引擎 Bing 上對谷歌的回應。 這與 Google 的網絡爬蟲類似,甚至包括一個抓取工具,指示機器人將如何抓取頁面,讓您查看此處是否存在任何問題。
吸食機器人
Slurp Bot 是雅虎使用的網絡爬蟲,儘管他們也使用 Bingbot 來提供他們的搜索引擎結果。 如果網站所有者希望其網頁內容出現在雅虎移動搜索結果中,則必須允許 Slurp Bot 訪問。 此外,Slurp Bot 還可以訪問雅虎的合作夥伴網站,將內容添加到他們的雅虎新聞、雅虎體育和雅虎財經網站。
鴨鴨機器人
這是 DuckDuckGo 使用的網絡爬蟲,DuckDuckGo 是一種搜索引擎,以通過不像許多流行的那樣跟踪用戶的活動而為其用戶提供無與倫比的隱私級別而聞名。 他們提供從 DuckDuckBot 以及維基百科等眾包網站和其他搜索引擎獲得的搜索結果。
百度蜘蛛和 Yandex Bot
這些是中國搜索引擎百度和俄羅斯 Yandex 分別使用的爬蟲機器人。 百度在中國大陸搜索引擎市場佔有率超過80%。
網絡抓取、搜索索引和搜索引擎排名的工作原理
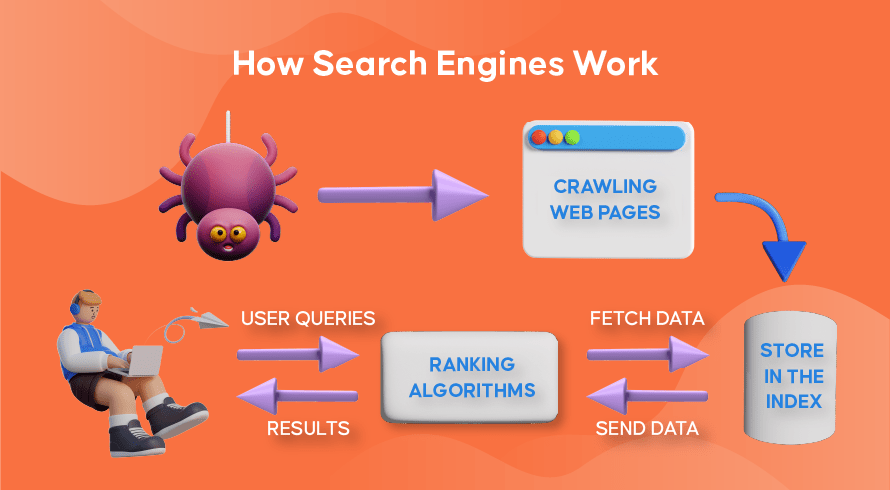
現在讓我們探討一下大多數搜索引擎如何使用網絡爬蟲來查找、存儲、組織和檢索網站中包含的信息。
網絡爬蟲的工作原理
在網站上查找新內容和更新內容的過程稱為“網絡爬行”,執行此功能的軟件程序因此得名。 機器人將首先開始抓取一些網頁,找到其內容,然後跟隨該網頁上包含的超鏈接來發現新的 URL,從而獲得更多內容。
搜索引擎索引的工作原理
在機器人通過網絡爬行發現新的或更新的內容後,他們發現的所有內容都會被添加到一個名為“搜索引擎索引”的龐大數據庫中。 這就像一個圖書館,其中的書籍就像網頁一樣,經過組織以便以後輕鬆檢索。 每本書中包含我們可以看到的網頁上包含的大部分文本(不包括“a”、“an”和“the”等詞)以及只有爬蟲才能看到的元數據。 元數據是搜索引擎用來理解網頁內容的。 元標題和元描述是元數據的示例。
搜索排名如何運作
每當用戶輸入搜索查詢時,相應的搜索引擎將檢查其索引,找到與該請求最相關的信息,組織包含相關內容的網絡鏈接列表,並將其呈現給搜索引擎中的用戶結果頁面 (SERP)。
SERP 的這種組織稱為“搜索排名”,由搜索算法執行,該算法考慮了收集的數據,包括元數據、網站(權威)的可信度以及關鍵字和鏈接。 被認為是非常可靠的來源並包含對用戶有用的高度相關內容的網站將排名很高,在 SERP 上獲得最高結果。 這就是為什麼每個網站所有者都有策略在 SERP 上對他們的網站進行排名。
搜索引擎優化 (SEO) 如何進入圖片
網站所有者可以優化其頁面上的內容,使搜索引擎更容易將其識別為對用戶相關且有用。 這會將這些頁面推到 SERP 的頂部,為網站帶來更多自然流量。 戰略性地在頁面副本、鏈接構建以及使用原始圖像和視頻中包含相關關鍵字是可以利用 SEO 技術的一些方式。
此外,網站還可以使用 SEMrush 等各種工具來查找和修復其頁面上的各種問題,例如斷開的鏈接,這將進一步提高其在搜索引擎眼中的排名。
告訴搜索引擎如何抓取您的網站

有時您會發現網絡爬蟲沒有充分發揮其功能,導致索引中缺少您網站的重要頁面。 這意味著相關搜索查詢不會隨您的內容一起顯示,從而使潛在客戶難以找到訪問您頁面的方式。 幸運的是,有一些方法可以與搜索引擎進行通信,讓您可以對哪些內容被編入索引以及哪些內容被忽略進行一些控制。
存儲在您網站根目錄中的 robots.txt 文件會告訴網絡爬蟲您要抓取哪些頁面、要忽略哪些頁面以及您的網站架構是如何安排的。 如果特定頁面用於測試、特殊促銷和電子商務中使用的重複 URL,您可能希望阻止它們被編入索引。
例如,如果不存在 robots.txt 文件,GoogleBot 仍將繼續抓取完整的網站。 當檢測到您的 robots.txt 文件時,GoogleBot 會在抓取時按照您的指示進行操作。 如果它在檢測文件時遇到問題或遇到錯誤,它可能不會抓取您的網站。 您必須正確使用 robots.txt 文件,組織您的網站架構,並使用頁面 SEO 最佳實踐來避免任何抓取問題。 您可以執行網站審核以分析和識別困擾您網站的任何問題。
您的網站需要 SEO 服務嗎?
如果您正在尋找了解網絡爬蟲和搜索索引如何提高網站排名的服務提供商,那麼 Inquivix 就是您一直在尋找的 SEO 合作夥伴。 我們提供從內容創建到網站架構優化和網站性能分析的一整套頁面搜索引擎優化服務,以不斷提高您的網站體驗質量。 要了解更多信息,請立即訪問 Inquivix On-Page SEO 服務!
常見問題
搜索引擎使用稱為“網絡爬蟲”(也稱為“蜘蛛”或“機器人”)的程序來發現網站頁面上的新內容和更新內容。 然後它將按照頁面中包含的鏈接查找更多頁面。 在頁面上找到的內容保存在索引中,該索引用於在用戶請求時檢索搜索結果的信息。

GoogleBot Desktop 和 GoogleBot Mobile 是大多數國家/地區最流行的網絡抓取工具,其次是 Bingbot、Slurp Bot 和 DuckDuckBot。 Baiduspider 主要在中國使用,而 Yandex Bot 在俄羅斯使用。